

A data pipeline is like a delivery system in a massive online store. Just as parcels need to reach customers’ doorsteps efficiently and accurately, data needs to travel from its sources to where it can be used for making crucial decisions, powering apps, or generating insights that can empower each business.
Nowadays, businesses collect tons of customer interaction data to increase operational efficiency. Just imagine that 328.77 million terabytes of data are created daily in 2024, and 81 zettabytes of data are expected to be generated by 2025. That’s why modern businesses need data pipelines to keep all that information moving smoothly from one point to another. They ensure data is collected, cleaned, analyzed, and utilized effectively.
In this article, we’ll discuss the key components of a high-performance data pipeline, consider the benefits of its integration, and how to choose the most efficient way for business.
Table of Contents
- Benefits of a Data Pipeline Integration
- 5 Key Data Components
- How to Implement a Data Pipeline
- Choose the Most Efficient Pipeline for Your Team and Business
Benefits of a Data Pipeline Integration
Streamlined Data Flow
Data pipeline integration organizes the chaos, creating a smooth, direct path from data collection to insights. It eliminates data silos and ensures all parts of the business have easy access to the data they need, exactly when they need it.
Enhanced Efficiency
Automation within integrated pipelines means data tasks that used to take hours or days (like compiling reports manually) can now happen automatically and in real time.
Better Decision Making
With an integrated data pipeline, decision-makers get timely and relevant data, leading to quicker and more informed decisions. It’s like having a real-time business intelligence system that keeps you informed about market trends and customer behaviors as they happen.
Scalability and Flexibility
As businesses grow, data infrastructure grows with them. Integrated pipelines are designed to be scalable and adaptable, handling increased data loads and new data types without breaking a sweat.
Integrating data pipelines isn’t just a technical upgrade but a strategic boon that makes businesses quicker on their feet, more responsive to changes, and better equipped to handle the challenges of the modern market.
5 Key Data Pipeline Components

A data pipeline is like a truck and road system that automates data flow in the digital world, ensuring it’s processed and ready for analysis or operational use without manual effort. Let’s discover the key components of a highly efficient data pipeline.
1. Data Standardization
Data standardization is about converting data from various sources and formats into a consistent and easy-to-use unified format, like making sure all your music files are converted to MP3s to play smoothly on any device.
Importance of Data Standardization in Pipelines
When dealing with data pipelines, data standardization is crucial for several reasons:
- Integration and Analysis. Standardization helps merge data from different sources to ensure accurate and meaningful data analysis.
- Efficiency. Standardized data reduces errors and improves data processing, much like having all machine parts made to specification ensures it runs smoothly.
- Accuracy and reliability. Standardization ensures data remains accurate and reliable throughout its lifecycle across all systems and processes by applying uniform formats and rules.
Techniques and Best Practices for Achieving Data Standardization in Pipelines
Here’s how to nail data standardization in your data pipelines:
- Define Clear Rules. Set up specific rules for how different data types should be formatted, named, and handled. This could be as simple as deciding whether dates should be in “DD-MM-YYYY” or “MM-DD-YYYY” format.
- Use Middleware. Employ middleware or data integration tools that can automatically standardize data as it passes through the pipeline.
- Data Validation. Implement validation steps to check data as it comes in. Data that doesn’t meet the standard can be corrected automatically or flagged for manual review.
- Regular Audits. Schedule regular checks on your data and the standardization processes to ensure they work as expected. It’s like a regular health check-up for your data.
- Training and Documentation. Ensure your team knows the importance of data standardization and how to apply it. Well-documented standards and training can help prevent deviations.
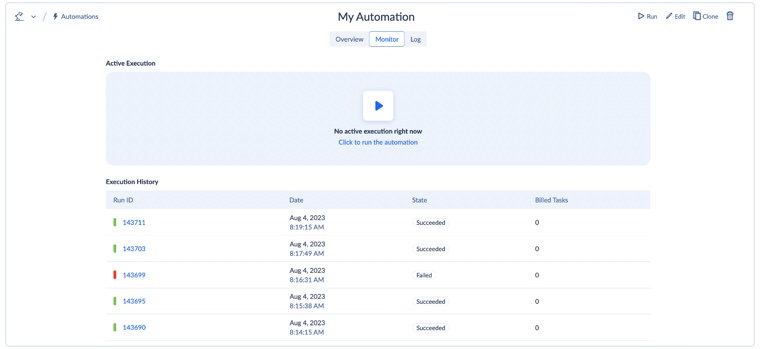
Skyvia is a good example of a data integration tool needed for standardization that offers super transformative features, monitoring, etc. For instance, you can check the results of the last five automation executions and the status of the current automation execution on the Monitor tab.
2. Repeated Operation Consistency
In data pipelines, repeated operation consistency means that every time you run a data process, you can expect the output to be the same, given the same input. This is essential when processing data in stages or repeatedly over time. It’s like a baking recipe; if you follow the same steps with the same ingredients, the outcome should always taste the same.
Operations that run consistently and predictably are easier to manage and optimize. It reduces the need for manual checks or reworks, which can slow down processes and increase costs.
Importance of Consistent Operations
Maintaining consistent operations is crucial for several reasons:
- Reliability. Teams can rely on the data and the processes to make informed decisions. It builds trust across the organization.
- Scalability. Consistent operations are easier to scale. As data volume grows, businesses can be confident that the processes will handle the increase without unexpected issues.
- Compliance. Many industries have strict regulations about data handling. Consistent operations help ensure that these regulations are met when data is processed.
Strategies to Ensure Consistency in Repeated Operations
While focusing on the strategies to ensure repeated operations consistency, you will know that your data operations are as reliable as your morning coffee — always good, always correct, and always ready to help start your day right. In the data world, that means making faster and more confident decisions.
Here are some strategies to keep the data operations consistent.
- Data backup. Data professionals use data backup to provide consistent, reliable snapshots of data, ensuring that repeated operations always have a solid foundation to work from.
- Automated Testing. Implement tests that run automatically whenever data is processed. These can catch inconsistencies early before they affect downstream processes. It’s like having a quality control system to check every data batch.
- Standardized Environments. Use containerization tools like Docker to create and share consistent environments across all pipeline stages. This means that everyone, from developers to analysts, works in the same setup, which minimizes the “it works on my machine” problem.
- Monitoring and Logging. Keep an eye on your data processes with comprehensive monitoring and logging. This can help quickly identify and address deviations from expected outcomes.
- Regular Audits. Schedule regular reviews of data operations to ensure they meet the required standards of consistency.
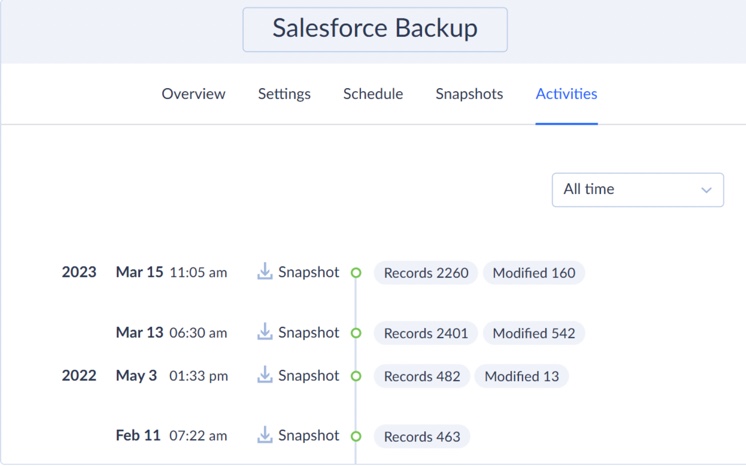
You may use Skyvia to keep the data consistent during repeated operations. For example, you can easily monitor the backup’s activity on the Activities tab. Here, you can see a timeline with all snapshots, restore operations performed by this backup, and some of the operation details.
3. Incremental Data Integration
Incremental data integration focuses on adding only new or changed data to the data warehouse or system since the last time data was collected. This approach saves time, reduces the load on data systems, and makes the entire process a lot smoother.
Benefits of Incremental Data Integration
- Efficiency. It speeds up data processes because there’s less data to move and process each time.
- Cost-effective. It saves data storage and processing power costs, as there is no need to repeatedly process large volumes of unchanged data.
- Up-to-date Data. It helps keep data updated and current without the overhead of full updates, ensuring that decision-makers have the latest information at their fingertips.
For example, the strategic approach that Cirrus Insight adopted to integrate Salesforce with QuickBooks using Skyvia aims to enhance productivity and reduce costs.

4. Data Filtering
Data filtering is similar to having a good editor for a book. It cuts out the fluff, leaving the valuable content that data users really need. Implementing smart filtering strategies ensures the data pipeline functions at its best, delivering quality insights efficiently and cost-effectively.
Techniques for Effective Data Filtering
You can use several techniques to filter data effectively, each serving a specific purpose depending on your needs.
| Technique | What It Is | Benefits |
|---|---|---|
| Data Partitioning | Dividing data into smaller, manageable chunks based on specific criteria. For example, you might partition sales data by region. | More straightforward data processing in parallel or managing data more efficiently, as a user can quickly access just the chunk needed without sifting through the entire dataset. |
| Data Bucketing | Similar to partitioning, bucketing is about grouping data that shares a common attribute or range of values into “buckets.” For instance, you might bucket customers into age groups for a marketing analysis. | It helps organize data in a way that improves query performance and can aid in more targeted analysis. |
| Conditional Filters | Applying conditions to only pass data that meets specific criteria. For example, filtering out all sales records where the amount is below a certain threshold. | It reduces the volume of data passing through the pipeline, significantly speeding up processing and reducing costs. |
Impact of Data Filtering on Pipeline Performance and Data Quality
Similarly to the standardization process, filtering out unnecessary data early on reduces the amount of data needed to be processed downstream. This means quicker processing times and less strain on the data systems. Filtering also helps ensure that the processing data is relevant and high-quality. This cleanliness is crucial because it means analyses and decisions are based on correct information — no poor decisions from irrelevant data.
Less data to store and process also means lower costs. Cloud services often charge based on storage and processing, so keeping data lean and mean can have direct financial benefits.
Here is how Skyvia’s data filtering can amp up pipeline performance and data quality.

- Enhanced Pipeline Performance. Skyvia’s data filtering allows the selection of the needed data without wasting resources on unnecessary transfers. By filtering out the irrelevant data, the pipelines run faster and more efficiently. It’s like streamlining the workload to focus only on what matters most.
- Improved Data Quality. Users can ensure that only clean, relevant data enters pipelines. This helps maintain high data quality by immediately filtering errors, duplicates, and inconsistencies. Consider it a quality check that keeps data in top-notch condition.
- Reduced Load. By filtering data before it hits the pipeline, Skyvia reduces the load on the systems. This means better overall performance and lower operational costs. It’s a smart way to keep things running smoothly without overburdening the infrastructure.
5. Automated Pipeline Control
Automated pipeline control involves using technology to automatically manage and oversee the data flow in the pipeline. This means scheduling tasks, managing data loads, monitoring performance, and handling errors — all on autopilot.
How Automation Enhances Pipeline Efficiency, Consistency, and Reliability
Automated tools can schedule and execute data tasks at optimal times and with optimal resources, ensuring that the data is processed quickly and ready when needed. This means no downtime waiting for manual triggers or setups. It’s pretty well implemented in Skyvia: everything is comfortable and convenient, with a customer-centric approach.
Automation enforces rules and procedures uniformly across all data processes. Whether it’s data cleaning or loading, automation ensures that these tasks are performed the same way every time, leading to predictable and reliable results.
With features like error detection and automatic retries, automated pipeline control can handle problems immediately, often without human intervention. This means the data processes are less likely to be disrupted and more likely to deliver dependable performance around the clock.
Tools and Technologies for Implementing Automated Pipeline Control
Let’s review the tools and technologies that help implement effective automated pipeline control.
- Skyvia makes it super easy to move and sync data between different platforms with its user-friendly interface and versatile integrations. You can set up flexible schedules, ensuring data is always up-to-date. It’s also reliable and secure, so data is always protected.
- Apache Airflow is great for scheduling and monitoring complex workflows. It lets planning, executing, and tracking the data jobs visually and programmatically.
- Apache NiFi supports data routing, transformation, and system mediation logic. It’s designed to automate the data flow between systems.
- AWS Data Pipeline web service helps automate data movement and transformation.
- Azure Data Factory allows data movement and transformation from various sources to be orchestrated and automated.
- Cron Jobs can be used to schedule tasks to run scripts at specific times. It’s a basic but effective way to automate parts of the pipeline.
Here are the real-life success stories of the benefits of data pipeline integration.
- CashMe Fintech Company Builded Complex Data Analytics with Microsoft Dynamics, Snowflake, and PowerBI.
- Bakewell Cookshop E-Commerce Company Synchronized Retail Shop Data with BigCommerce via Skyvia Data Integration.
- Plüm Énergie Automated Data Flow between Jira and PostgreSQL Using Skyvia Data Integration.

How to Implement a Data Pipeline
Having a solid data pipeline isn’t just about automation; it’s mostly about keeping data in tip-top shape, where each data pipeline component is essential. Data integrity and consistency are key players here. A well-designed pipeline ensures that data is accurate and reliable every step of the way, so you can trust the information you’re working with.
Implementing a data pipeline can seem like a big task, but taking it step by step makes it manageable. Let’s walk through the key considerations and steps of such implementation.
Key Considerations
- Be mindful of how your data is formatted and structured. Consistent data formats simplify processing.
- Choose storage that matches your access needs and budget. Cloud solutions are flexible and scalable.
- Ensure your data retrieval methods are efficient and suit your analysis needs.
Automation in Data Pipelines
- Set up the schedule of regular data runs (daily, hourly, etc.) to keep your data updated.
- Trigger your pipeline based on events, like new data arrival or specific business events, for real-time processing.
Step-by-Step Guide to Implement Key Components of Data Pipeline
- Start by defining your data format, structure, and where it hosts. This helps plan how you’ll move and transform it.
- Sketch out the pipeline’s flow. Consider how data will move from the source to the destination. Visualizing this process can make the next steps more straightforward.
- Choose the right tools and technologies for your needs. Popular choices include Apache Airflow for orchestration, SQL for data manipulation, cloud-based data pipeline tools like Skyvia, and cloud storage solutions like AWS S3.
- Set up the initial step where data enters your pipeline (databases, APIs, or flat files). Make sure you handle different data formats properly.
- Decide how you’ll clean, transform, and enrich your data. This step is crucial for maintaining data quality and making it usable for analysis.
- Choose where you’ll store your processed data. Options include data warehouses like Snowflake, PostgreSQL databases, and data lakes.
- Ensure you have efficient ways to access your data. This might involve setting up APIs, SQL queries, or other retrieval methods that fit your use case.
- Make your pipeline bright with automation. Use tools to schedule regular data runs or trigger pipelines based on specific events.
- Set up monitoring to catch issues early. Tools like Grafana or Prometheus can help monitor your pipeline’s health. Regular maintenance is key to smooth operations.
Choose the Most Efficient Pipeline for Your Team and Business
Choosing the most efficient data pipeline for your team and business can feel a bit like finding the perfect pair of shoes. There are lots of options, and you want the best fit.
First off, consider the factors that matter most to your team. Think about the volume of data you’re handling, how fast you need it processed, and the complexity of the data sources. Having a pipeline that can handle the workload without sweat is better.
Next, customize the pipeline to match your specific business needs and goals. Decide if you’re focusing on real-time analytics or batch processing. Do you need extra layers of security for sensitive data? Tailoring the pipeline ensures it aligns perfectly with what you’re aiming to achieve.
Take into consideration the 5 key components needed for successful data pipeline implementation.
Remember to select the right platforms for efficient data movement. In this case, Skyvia is a professional cloud-based ETL pipeline tool offering a user-friendly interface and robust data integration, backup, and management capabilities. Skyvia makes it easy to connect 180+ data sources and automate the data flow, saving you tons of time and hassle or an honest price.
Lastly, think about scalability. As your business grows, your data needs will too. Choose a pipeline that can scale up easily so you’re always prepared for the next big thing.

