

Summary
- Skyvia: Best for no-code, automated data integration with an intuitive interface for non-technical users
- Fivetran: Best for fully managed, scalable ETL pipelines with seamless integrations across a wide range of platforms
- Stitch: Best for easy-to-use ETL with a strong focus on simplicity and broad integrations
- Talend: Best for data governance and enterprise-level ETL with comprehensive compliance features
- Apache NiFi: Best for visual flow management with powerful batch and streaming capabilities
Data in the digital world is like oil in the fossil fuel for vehicles. Similar to how transportation means need fuel to ride, companies need data to move forward.
Obviously, cars can’t work with raw oil to drive since this material needs to be transformed into petrol first. The same goes for businesses with information systems – they need to process data before use.
Data pipeline tools collect all the required data and make it usable. So, this article explores popular solutions along with their features, limitations, and pricing. It also compares different kinds of data pipeline tools and provides real-world examples of how and when to use them.
Table of contents
- What Are Data Pipelines?
- Top 10 Data Pipeline Tools
- How to Choose a Data Pipeline Tool
- Types of Pipelining Software
- How to Build Data Pipelines Using Skyvia Data Flow
- Case Studies of Data Pipelines in Action
- Conclusion
What Are Data Pipelines?
“A data pipeline is a method in which raw data is ingested from various data sources, transformed and then ported to a data store, such as a data lake or data warehouse, for analysis.” – IBM.
Data pipeline tools are software applications that enable users to build data pipelines. The primary objective of these solutions is to automate data collection and flow by connecting source and destination tools.
Many such tools also offer simple and sophisticated options to transform data on the go. Data pipeline solutions allow businesses to automate various data-related processes, manage large data sets effectively, and enhance reporting.
Components of a Data Pipeline
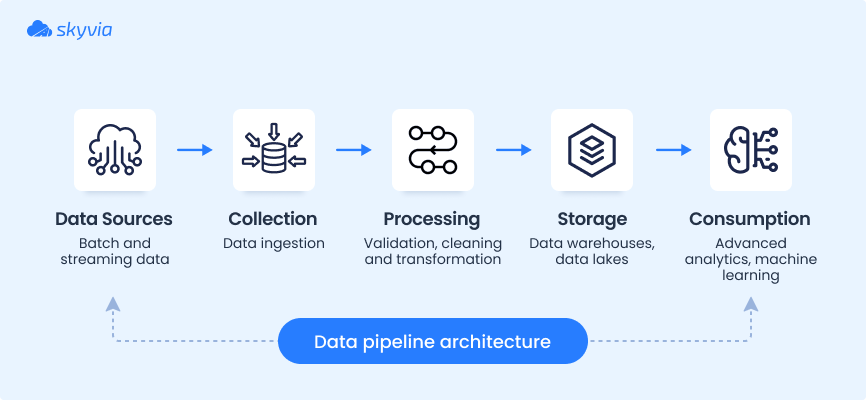
The structure of a data flow differs from one company to another. Anyway, each data pipeline contains more or less the same set of components:
- Data sources. Each business has its toolset (SaaS apps, databases, IoT systems, etc.), which constitutes a starting point of a data pipeline.
- Data ingestion tools. They extract raw data from the source systems either in a batch or streaming mode. The first option is better for periodical data retrieval, while the second one is suitable for real-time processing.
- Transformation features. Cleansing and normalizing data after ingestion is crucial to ensure quality in further pipeline stages.
- Storage destinations. After transformations, data goes to the destination database, data warehouse, or another storage system.
- Delivery and consumption systems. These are usually BI and analytics tools, machine learning platforms, AI apps, and other systems that consume and utilize data.
Data Pipelines vs. ETL Processes
Data pipelines are often interchangeably used as ETL pipelines to describe automated data integration processes. However, these notions aren’t identical even though they share some processes in common.
In a nutshell, an ETL pipeline is just a part of an entire data pipeline, which takes care of batch collection, transformation, and loading of structure data. Meanwhile, typical data pipelines can handle real-time workflows, unstructured data, and complex integration scenarios.
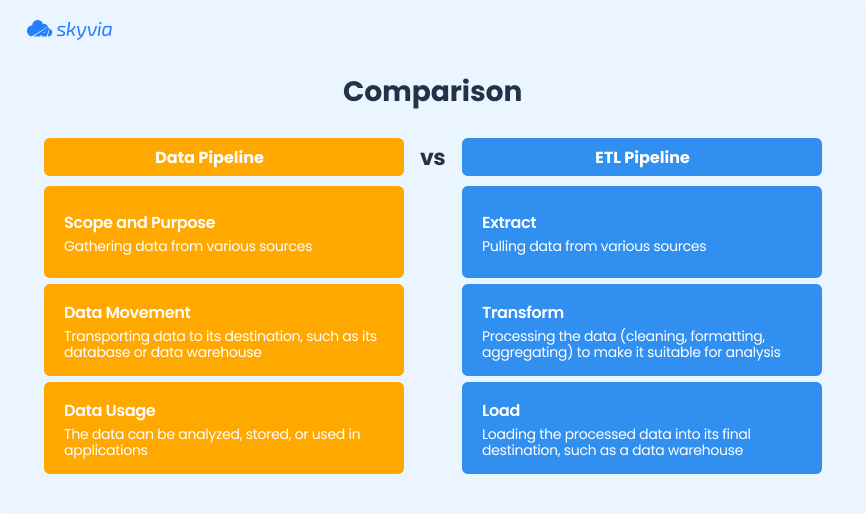
Feel free to check the key differences between ETL and data pipelines.
Benefits of Data Pipelines: Why You Need Them
Apart from automating and streamlining workflows, data pipelines bring a number of other benefits to businesses.
- Centralized data management. Since these solutions can consolidate data in a single central location, they enable the creation of the SSOT (single source of truth). This provides a centralized data repository that anyone on the team can access.
- Flexibility. Modern data pipelines are easily scalable and elastic, which means they can adapt to changing data loads and volumes.
- Data quality. Due to the transformation options, data is cleansed and standardized, which improves its quality. At this stage, raw data is converted into a uniform format and becomes suitable for analysis and other operations.
- Enhanced decision-making. Data pipelines make data flow through various stages and transformation processes, making it usable for reporting, analytics, predictions, etc. This promotes a data-driven approach to deriving insights and evaluating business performance outcomes.
Top 10 Data Pipeline Tools for 2025
Selecting the right data pipeline tool can significantly impact how smoothly and effectively you manage your data workflows. To help you navigate the options, we’ve compared the top 10 tools based on key criteria like ease of use, pricing, and best use cases. Below you’ll find a quick comparison followed by detailed insights into each platform.
| Tool | Best For | Skill Level | Pricing Overview | Notable Features/Limitations |
|---|---|---|---|---|
| Skyvia | SMBs & teams needing easy, no-code cloud ETL | Beginner to Medium | Free tier; paid plans start at $79/month | 200+ connectors, no coding, limited free plan features |
| Fivetran | Enterprises wanting fully managed ELT automation | Beginner | Usage-based, starting free, scales by MAR | 150+ connectors, ELT only, minimal transformation control |
| Apache Airflow | Data engineers wanting customizable workflows | Advanced (Python) | Open-source, free | Highly customizable, requires coding, community support |
| Airbyte | Teams wanting open-source & custom connectors | Medium to Advanced | Free self-hosted, paid cloud starting custom | No-code connectors, CDK for coding custom connectors |
| Stitch | SMBs needing simple cloud ETL | Beginner to Medium | Starting at $100/month | 130+ connectors, API, limited support on free tiers |
| Talend | Enterprises needing hybrid cloud/on-prem solutions | Medium to Advanced | Custom pricing via sales | Handles structured/unstructured data, complex setup |
| Integrate.io | Mid-market e-commerce focus | Medium | Custom pricing via sales | Supports CDC, API generation, limited connectors |
| Matillion | Growing businesses wanting cloud-native ETL | Medium | Starting free developer tier; paid plans up to $2000+/month | GUI & SQL transformations, no restart from failure |
| StreamSets | Enterprises needing batch & streaming pipelines | Advanced (Kubernetes) | Custom pricing via sales | Supports batch & streaming, Kubernetes knowledge required |
| Apache Spark | Data scientists & engineers needing powerful processing | Advanced (coding) | Open-source, free | Multi-language support, no dedicated support |
1. Skyvia
Best for
Businesses and teams looking for a versatile, no-code data integration platform that supports both ELT and ETL workflows. Ideal for organizations that need easy, browser-based access to over 200 connectors, want to automate data backups, and build scalable pipelines without heavy technical overhead. Particularly suited for SMBs and departments without dedicated data engineering resources.
Reviews
G2 Rating: 4.8 out of 5 (based on 200+ reviews).
Skyvia is a cloud-based platform for data integration with a no-coding approach. It supports ELT and ETL scenarios, allowing users to connect to a wide range of data sources and build integration pipelines visually.
Skyvia provides several products for building integrations of various complexity, creating data endpoints, automating backups, and many more. Since this tool runs in the cloud, it can be accessed via any web browser without any added software installations.
Pros
- Requires no coding.
- More than 200 connectors to cloud sources, databases, and data warehouses.
- Provides SSH and SSL connection support.
- Has a free trial in addition to flexible pricing plans.
- Responsive support team.
Cons
- Limited transformation options in the Free plan.
- Basic error handling.
Pricing
Skyvia provides five pricing plans.
| Free | Basic | Standard | Professional | Enterprise | |
|---|---|---|---|---|---|
| Starting price | $0 | $79/month | $159/month | $199/month | Custom |
| Records per month | 10k | 5M+ | 500k+ | 5M+ | Custom |
| Scheduled integrations | 2 | 5 | 50 | Unlimited | Unlimited |
| Integration scenarios | Simple | Simple and advanced | |||

2. Fivetran
Best for
Organizations seeking a fully managed, automated ELT solution to replicate data seamlessly from a wide range of SaaS applications and databases. Ideal for teams prioritizing ease of use, minimal manual intervention, and robust support, especially when handling frequent schema changes. Best suited for businesses focused on quick data ingestion into cloud data warehouses with limited need for pre-load transformations.
Reviews
G2 Rating: 4.2 out of 5 (based on 380+ reviews).
Fivetran is a web-based platform that allows users to create data pipelines in the cloud. It enables data replication from various SaaS (Software as a Service) sources and databases with ELT pipelines
Fivetran offers no-code connectors to databases or data warehouses that can be used to build integrations. This tool relies on automation to effectively handle schema changes, significantly minimizing manual input.
Pros
- Support of over 150+ connectors for better connectivity.
- 24/7 technical support for quick resolutions.
- A fully managed approach minimizes coding and customization in building data pipelines.
Cons
- Fivetran supports only ELT pipelines but not ETL pipelines. This means data transformation isn’t supported before it achieves the destination.
- Minimal scope for customization of the code.
Pricing
Fivetran provides four pricing plans.
| Free | Starter | Standard | Enterprise | |
|---|---|---|---|---|
| Users | 10 | 10 | Unlimited | Unlimited |
| Sync frequency | Hourly | Hourly | 15 minutes | 1 minute |
| Monthly active rows (MAR) | up to 500,000 | Flexible | ||
| Starting price | $0 | Depends on MAR | ||
3. Apache Airflow
Best for
Technical teams and data engineers who need a flexible, open-source orchestration platform for building, scheduling, and monitoring complex data workflows. Ideal for organizations with strong Python skills seeking full control over pipeline customization and integration with version control systems. Best suited for those willing to manage their own infrastructure and rely on community support rather than dedicated vendor assistance.
Reviews
G2 rating: 4.5 out of 5 (based on nearly 100 reviews).
Airflow is an open-source data pipeline orchestration tool. It uses Python programming to create and schedule workflows, also known as DAGs (Directed Acyclic Graphs). You can also monitor and orchestrate these workflows with the Python-based interface.
Along with creating data pipelines, Airflow can help you with other tasks. For example, it allows you to manage infrastructure, build machine learning models, or run Python code. What’s more, it provides logs of the completed and running workflow through its UI.
Pros
- Free to use as it’s an open-source solution.
- Airflow can be easily integrated with version control systems like Git.
- Users can customize the existing operators or define them depending on a use case.
Cons
- Building data pipelines requires Python knowledge.
- Airflow doesn’t provide any dedicated technical support, so users need to rely on community support in case of issues.
Pricing
Since Apache Airflow is an open-source solution, it’s available for free.
4. Airbyte
Best for
Data teams looking for an open-source, flexible ELT platform with no-code connectors and the ability to customize or build connectors via code. Suitable for organizations that want control over their infrastructure and integration with modern data orchestration tools like Kubernetes and Airflow. Ideal for users with coding skills who need both free self-hosted options and enterprise-grade support in paid plans.
Reviews
G2 rating: 4.5 out of 5 (based on nearly 50 reviews).
Airbyte is an open-source data integration platform. It easily builds ELT data pipelines with the help of no-code pre-built connectors for both data sources and destinations.
This tool also provides CDK (Connector Development Kit) for creating custom connectors. You can also use this kit to edit the existing connectors to match your particular workflows.
Pros
- Airbyte provides an open-source version as well as licensed ones that help users manage all the operational processes.
- Supports integrations with other stacks such as Kubernetes, Airflow, Prefect, etc.
- The licensed edition provides 24/7 technical support for any debugging.
Cons
- Airbyte supports only ELT pipelines.
- Creating connectors with CDK requires coding knowledge.
Pricing
The open-source version of Airbyte comes for free and can be installed on your servers. A paid enterprise version can also be hosted on your infrastructure. Otherwise, you may choose a cloud-based paid version at a custom price, which offers support, extra security features, and other benefits.
5. Stitch
Best for
Small to mid-sized teams needing a straightforward, cloud-based ETL solution with a wide range of connectors and easy setup. Ideal for users who want visual pipeline management with scheduling and monitoring capabilities, and who value community-driven integrations via the Singer project. Suitable for organizations that prioritize simplicity and scalability in the cloud but do not require on-premises deployment.
Reviews
G2 Rating: 4.4 out of 5 (based on 60+ reviews).
Stitch is a cloud-based data pipeline tool. It provides connectors to 130+ sources that can be configured in a visual interface, which makes it easy to ingest data into a warehouse.
This tool also ensures orchestration, embedding, data transformation, and other features for pipeline management. You can also use Stitch API to push any data to the destination system in a programmatic way.
Pros
- Includes a dashboard for data pipeline tracking and monitoring.
- Provides community-driven development and integration with different tools through the Singer project.
- Has scheduling options to run jobs at predefined intervals.
Cons
- No on-premise version.
- Some connectors are accessed only with the Enterprise version.
- Limited customer support.
Pricing
Stitch has three pricing plans.
| Standard | Advanced | Premium | |
|---|---|---|---|
| Starting price | $100/month | $1250/month | $2500/month |
| Rows per month | 5-300 M | 100 M | 1 B |
| Destinations | 1 | 3 | 5 |
| Sources | 10 (standard) | Unlimited | Unlimited |
| Users | 5 | Unlimited | Unlimited |
6. Talend
Best for
Enterprises and teams needing a comprehensive, hybrid data integration platform capable of handling complex ETL workflows across both cloud and on-premises environments. Well suited for organizations that require robust support for structured, semi-structured, and unstructured data, as well as advanced API design and testing capabilities. Ideal for users who value an all-in-one solution with strong governance and management features, and who can manage a more involved installation and setup process.
Reviews
G2 Rating: 4.0 out of 5 (based on 65 reviews).
Talend offers multiple products and services, both open-source and paid ones. Talend Data Studio is a free, open-source solution, while Talend Data Fabric is a paid version, which includes Talend Big Data, Management Console, API Services, Data Inventory, Pipeline Designer, etc.
In particular, the Talend Pipeline Designer tool is dedicated to constructing data pipelines. It’s a web-based tool that builds complex ETL dataflows and processes data during the transit.
Pros
- Supports both on-premises and cloud data pipelines.
- Provides the ability to design and test APIs for data sharing.
- Handles unstructured data along with structured and semistructured data.
Cons
- No transparent pricing – you need to contact the sales team for a quote.
- The complex installation process for on-premise versions.
- Limited features and connectors for Talend Open Studio.
Pricing
The price for Talend solutions is discussed with their sales managers.
7. Integrate.io
Best for
Businesses, especially in e-commerce, looking for a cloud-based ETL/ELT platform with minimal coding requirements. Suitable for teams needing API generation capabilities and support for change data capture (CDC) workflows. Ideal for organizations aiming to orchestrate multiple dependent data pipelines in the cloud, with a focus on integrating REST API-enabled sources. Less suited for those requiring broad connector variety or on-premises deployment.
Reviews
G2 Rating: 4.3 out of 5 (based on 200+ reviews).
Integrate.io is a cloud-based data integration platform. It allows users to build ETL, reverse ETL, and ELT data pipelines. This tool also supports API generation and CDC technology.
Integrate.io allows users to create and manage data pipelines with minimal coding requirements. Before ingestion, it’s also possible to apply filters to extract data based on the specified condition.
Pros
- Ability to pull data from any source that offers a REST API.
- Creates dependencies between multiple data pipelines.
- Offers API generation for multiple databases, security, network data sources, etc.
Cons
- A limited number of connectors. The available connectors are focused on e-commerce use cases.
- Doesn’t offer an on-premise version.
Pricing
The price for Integrate.io is discussed with their sales managers.
8. Matillion
Best for
Organizations seeking a cloud-native data integration platform with a user-friendly drag-and-drop interface for building ETL and ELT pipelines. Well-suited for teams that need flexible deployment across major cloud providers and want to perform transformations using either SQL or visual components. Ideal for businesses requiring a robust orchestration and management solution with support for both cloud and on-premises data sources. Less optimal for users who prioritize extensive documentation or need fault-tolerant job restart capabilities.
Reviews
G2 rating: 4.4 out of 5 (based on 80 reviews).
Matillion is a cloud-native data integration tool that provides an intuitive user interface to develop data pipelines. There are two products Matillion offers: Data Loader for moving data from any service to the cloud and Matillion ETL to define data transformations and build data pipelines on the cloud.
Matillion ETL is a fully-featured data integration solution for creating ETL and ELT pipelines within a drag-and-drop interface. This tool can be deployed on your preferred cloud provider.
Pros
- Provides connectors to both cloud and on-premises data systems.
- Contains features for data orchestration and management.
- Data transformations can be performed either with SQL queries or via GUI by creating transformation components.
Cons
- Lack of documentation describing features and instructions for their configuration.
- There is no option to restart tasks from the point of failure. The job needs to be restarted from the beginning.
Pricing
Matillion offers four pricing plans.
| Developer | Basic | Advanced | Enterprise | |
|---|---|---|---|---|
| For whom | individuals | growing teams | scaling businesses | large organizations |
| Starting price | $0/month | $1000/month | $2000/month | Custom |
| Users | 2 | 5 | Unlimited | Unlimited |
| Support | Community | Standard | Standard | Premium |
9. StreamSets
Best for
Enterprises needing a fully managed cloud platform capable of handling both batch and streaming data pipelines with robust transformation capabilities. Ideal for organizations integrating multiple SaaS and on-premises data sources that require scalable, real-time data processing. Best suited for teams comfortable with Kubernetes or those willing to invest in learning it, as the platform operates on Kubernetes infrastructure. Not recommended for organizations seeking on-premises deployment options.
Reviews
G2 rating: 4.0 out of 5 (based on nearly 50 reviews).
StreamSets is a fully managed cloud platform for building and managing data pipelines. It offers two licensed editions – a professional edition with a limited set of features and an enterprise edition with extensive support and full functionality.
This tool supports 100+ connectors to databases and SaaS apps for easy creation and management of dataflows. It supports two types of engines to run data pipelines:
- Data collector that supports batch, streaming, and CDC modes.
- Transformer engine that applies transformations on the entire dataset.
Pros
- Supports integration with multiple SaaS apps and on-premise solutions.
- Handles batch and streaming data pipelines.
Cons
- No on-premise solution.
- The users might require Kubernetes knowledge as the data pipelines run on top of it.
Pricing
The price for IBM StreamSets is discussed with their sales managers.
10. Apache Spark
Best for
Organizations and data teams with strong programming expertise looking for a powerful, flexible, and free open-source engine to build complex, real-time and batch data pipelines. Ideal for users who need multi-language support (Python, Scala, Java, R, SQL) and require deep customization for data transformation and exploratory data analysis on large datasets. Not suitable for teams without coding skills or those needing dedicated vendor support.
Reviews
G2 rating: 4.3 out of 5 (based on 50+ reviews).
Apache Spark is an open-source data transformation engine. It can be integrated with a wide range of frameworks, supporting a wide variety of use cases.
Users can build data pipelines that process real-time as well as batch data with Apache Spark. They can also perform Exploratory Data Analysis (EDA) on large data volumes and run SQL queries by connecting to different storage services.
Pros
- It’s free to use as it is open-source.
- Offers support for multiple languages such as Python, Scala, Java, R, and SQL.
Cons
- It requires extensive coding experience to implement data pipelines.
- Debugging is challenging as there is no dedicated technical support, though there is an extensive community that can help address issues.
Pricing
Since Apache Spark is an open-source solution, it’s available for free.
How to Choose a Data Pipeline Tool
Choosing the right data pipeline tool is a critical step that can impact your business’s data efficiency and scalability. Beyond just functionality, you need to evaluate various factors carefully to ensure the platform aligns with your technical needs, budget, and growth plans. Here are key aspects to consider in depth:
- Ease of use. Look for tools with an intuitive, user-friendly interface that allows both technical and non-technical users to design, monitor, and manage data pipelines visually. A low-code or no-code environment empowers business users to build and modify workflows without relying heavily on IT teams. Additionally, check for quality documentation, tutorials, and customer support that ease onboarding and reduce learning curves.
- Scalability. Choose a platform that scales flexibly with your data volume and organizational growth. It should efficiently handle sudden spikes or drops in data flow without performance degradation. Consider whether the architecture supports horizontal scaling (e.g., distributed processing) and if the pricing model accommodates scaling without exponential cost increases.
- Integration Сapabilities. A strong data pipeline tool must support a broad and growing library of pre-built connectors to your key databases, cloud services, SaaS apps, and on-premises systems. Also, assess the ability to create custom connectors or extend functionality via APIs or SDKs to future-proof your integration ecosystem.
- Processing Speed and Latency. Depending on your use case, evaluate if the tool supports real-time or near-real-time data ingestion and transformation, or if batch processing suffices. For use cases like fraud detection or live customer personalization, low latency and streaming support are critical. For reporting and archival, batch processing may be more cost-effective.
- Security and Compliance. Security features are non-negotiable when handling sensitive or regulated data. Ensure the platform offers encryption at rest and in transit, multi-factor authentication, fine-grained role-based access control, audit logging, and compliance with standards like GDPR, HIPAA, SOC 2, and others relevant to your industry.
- Pricing Model and Total Cost of Ownership. Analyze the pricing structure closely — whether it is subscription-based, usage-based (per data volume or rows processed), or tiered plans. Consider hidden costs such as data transfer fees, connector add-ons, or support plans. A tool with transparent pricing aligned with your data patterns helps optimize expenses. Also factor in the cost of training, maintenance, and potential downtime.
- Community and Vendor Support. A vibrant user community can accelerate problem-solving and provide valuable best practices. Check if the vendor offers robust support channels, SLAs, and regular product updates. Open-source tools typically have active communities but may lack dedicated support, while commercial platforms offer professional assistance.
- Reliability and Monitoring. Look for features like error detection, retry mechanisms, alerting, and detailed logging to maintain pipeline health. Built-in monitoring dashboards help detect bottlenecks and ensure smooth operations, reducing downtime and manual intervention.
- Flexibility and Customization. Consider how easily you can customize transformations, data routing, and scheduling. Platforms supporting scripting, expressions, or custom modules enable handling complex business logic and evolving requirements.
Types of Pipelining Software
There are many data pipeline tools available on the market. They are categorized according to their licensing type, purpose of use, and operational environment.
Open-source vs. Licensed Tools
Open-source solutions are available at no cost and allow users to modify the source code. Anyone can install and use them on their systems.
Here are some examples of the open-source services:
- Apache Airflow
- Airbyte
- Dagster
The licensed data pipeline tools require a valid subscription for accessing and using them. Some companies offer a trial version for users to explore the functionality of the chosen service.
Here are some examples of the licensed solutions:
- Skyvia
- Hevodata
- Fivetran

Cloud vs. On-premise Tools
Cloud data pipeline platforms are fully managed, meaning that users don’t have to install them and take care of the underlying infrastructure. All the data transfer and processing happens over the cloud servers. These tools can also scale easily when required.
Here are some examples of cloud solutions:
- Skyvia
- Google Dataflow
- StreamSets
Many organizations don’t want their data stored or processed on the cloud to remain coherent with privacy policies. On-premise tools are installed on servers maintained by a dedicated team within the organization. These solutions aren’t as scaleable as their cloud alternatives.
Here are some examples of the on-premise systems:
- Apache Airflow
- Oracle Data Integrator
- Informatica
Stream vs. Batch Tools
Stream services process data as soon as it arrives on a real-time basis. Here are some of the tools supporting stream data flows:
- Apache Spark
- Apache Nifi
- Google Dataflow
Batch data pipeline tools run at regular intervals and extract data in chunks. Here are the examples of such platforms that support batch processes:
- Skyvia
- Apache Airflow
- Talend
How to Build Data Pipelines Using Skyvia Data Flow
If you decide to select Skyvia for building data pipelines, you can do that with one of the available solutions:
Here, we’ll explore how to build and set up pipelines with Data Flow in Skyiva. This solution allows you to create a diagram of connected components in a visual drag-and-drop interface.
Sample Task Description
Let’s assume you have to create and configure an integration scenario involving three data systems:
- A source database. It has the Customers table, which includes the CompanyName and ContactName fields.
- A CRM. In our case, it’s Hubspot CRM that stores all the deals-related information and has the Number Of Opened Deals field in the Companies table.
- A target database. It contains the Contact table that should store CompanyName, ContactName, with the Number Of Opened Deals in it.
Prerequisites
Make sure you have the Skyvia account or create a new one. Note that you can use this tool for free to try out all the fundamental features.
The next step is to configure connections for the databases and HubSpot.
- In your Skyvia account, go to + Create New -> Connection.
- Choose the required connector from the list and click on it.
- Fill out the required credentials. See the instructions provided next to the setup form.
- Click Create.
Solution
Once you’ve created all the connections, you can start building a data pipeline with the help of Data Flow. To do so, go to + Create New -> Data Integration -> Data Flow in your Skyvia account.
Add components to the board by dragging them from the panel on the left. Then, link the components by connecting the input and output circles on the diagram.
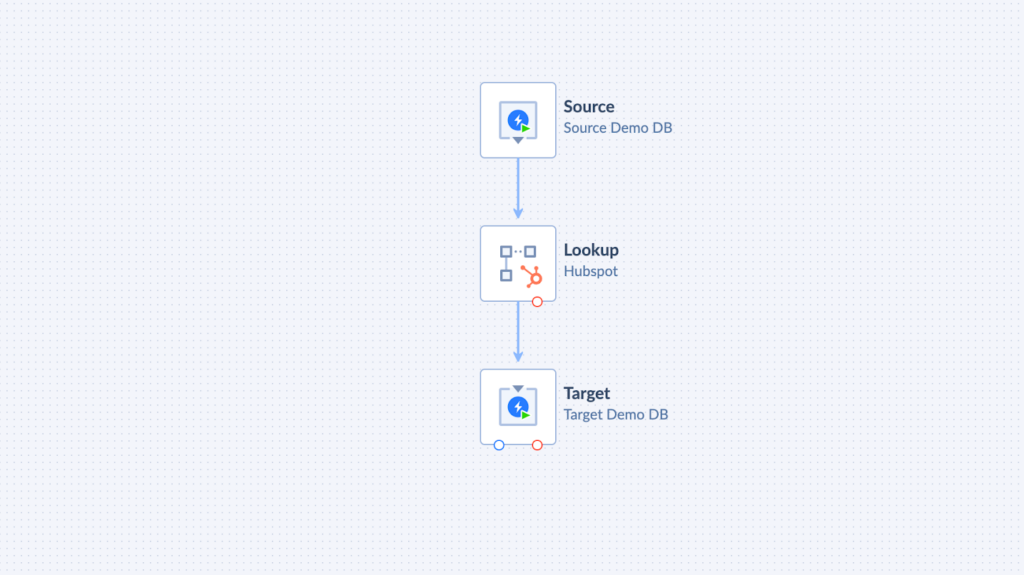
Source Setup
Source extracts data from the selected system and makes up a starting flow of the Data Flow diagram.
- Drag the Source components from the panel to the diagram and click on it.
- Select the system from the Connection dropdown in the right panel.
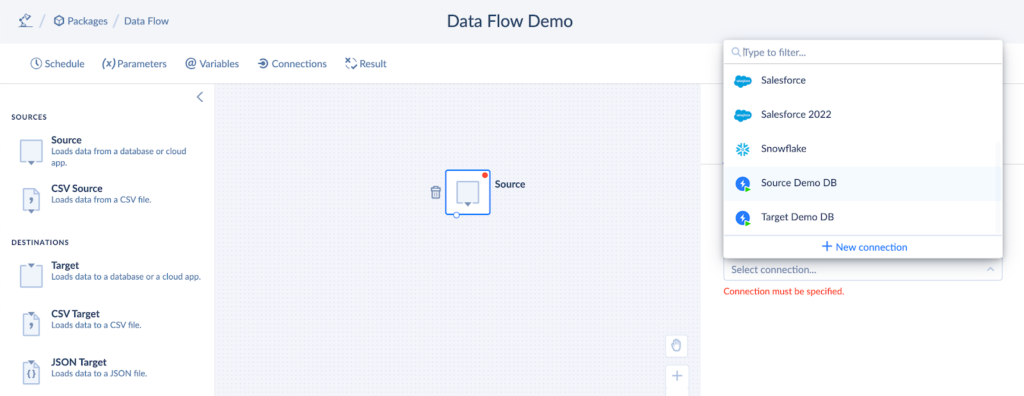
- Select Execute Command from the Actions drop-down list.
- In the Command Text box, create an SQL query.
SELECT CompanyName, ContactName FROM Customers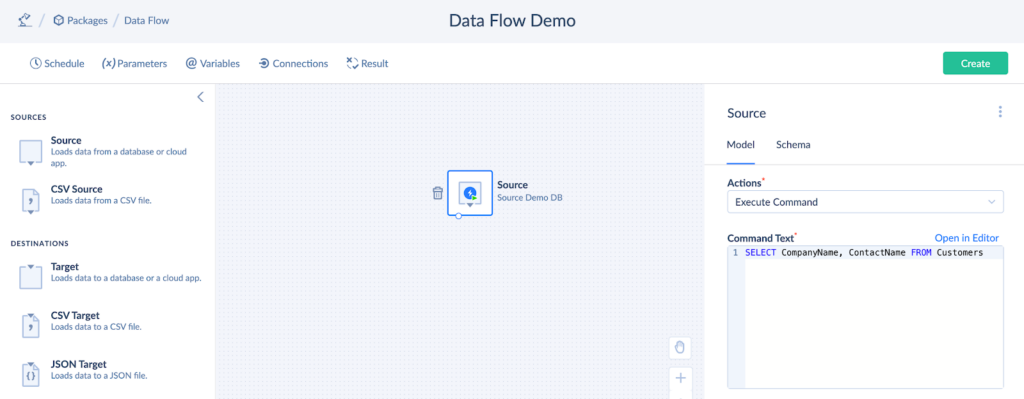
- Check the output results by clicking on the output arrow.
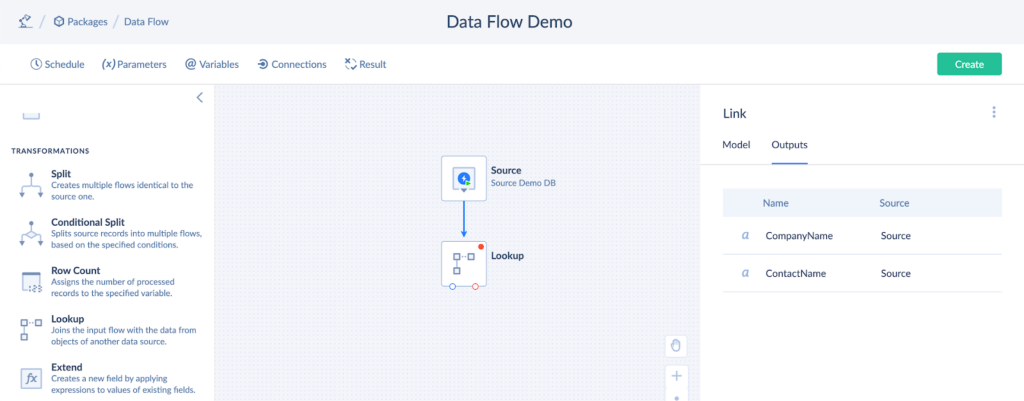
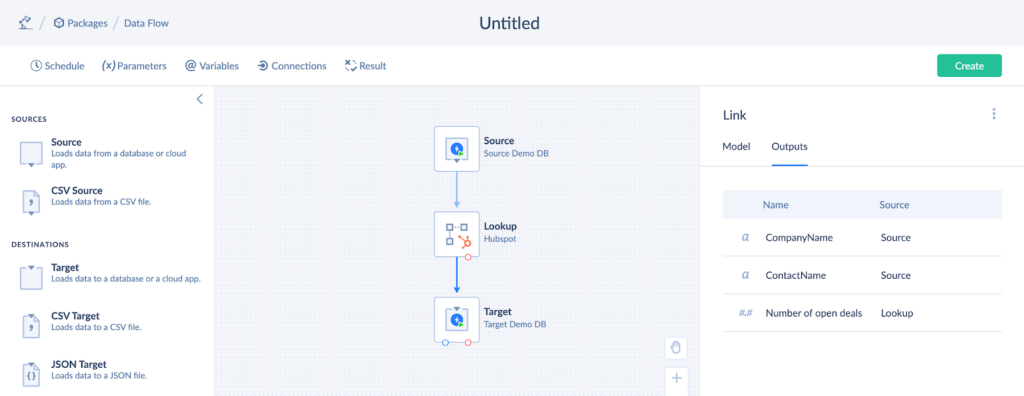
Lookup Setup
The Lookup component aims to match the records in different data systems. It adds columns of the matched records to the scope.
In our case, the source output consists of two columns: CustomerName and ContactName. Let’s add the Number Of Opened Deals column from the Companies table in HubSpot to the scope with the help of the Lookup component.
- Click the Lookup component on the left panel and drag it to the diagram.
- Choose HubSpot from the Connection dropdown list.
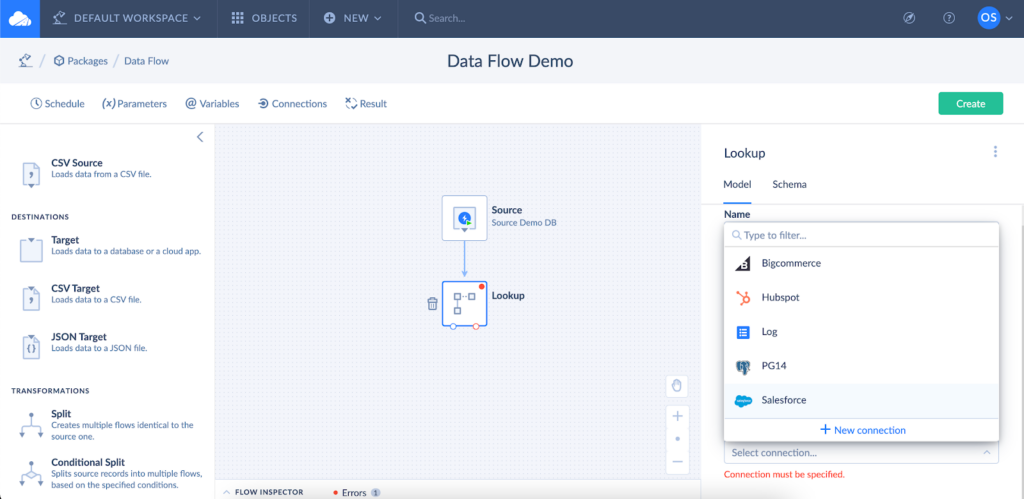
- Choose Lookup from the Actions dropdown list.
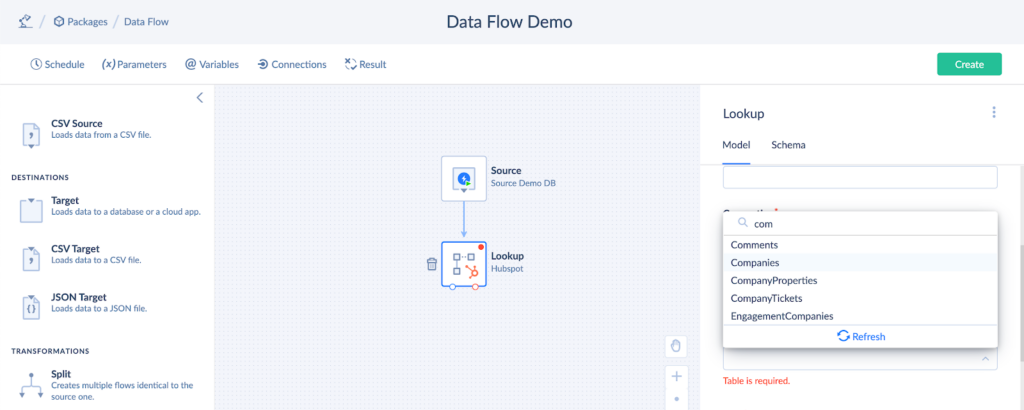
- Select the table under the Table dropdown list. The Number Of Opened Deals column is stored in the Companies table.
- Select the Company name in the Keys field.
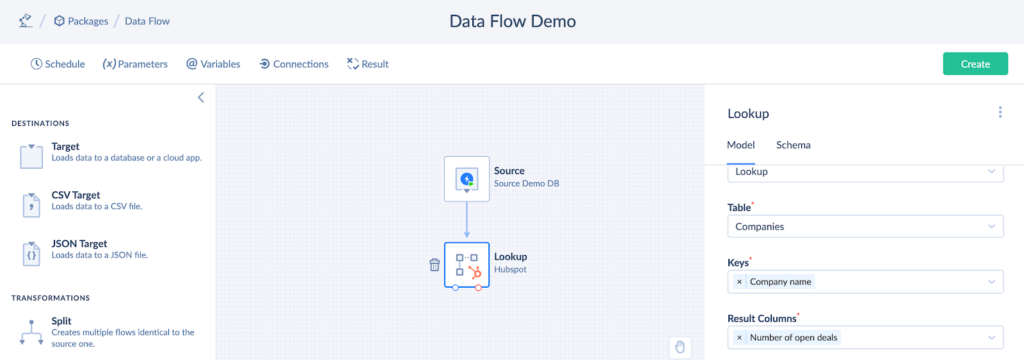
- Select the Number Of Opened Deals column from the Result Columns dropdown list. It will be added to the output results.
- Open Parameters to map keys. In this example, we map the Company name in HubSpot to the CompanyName in the source database.
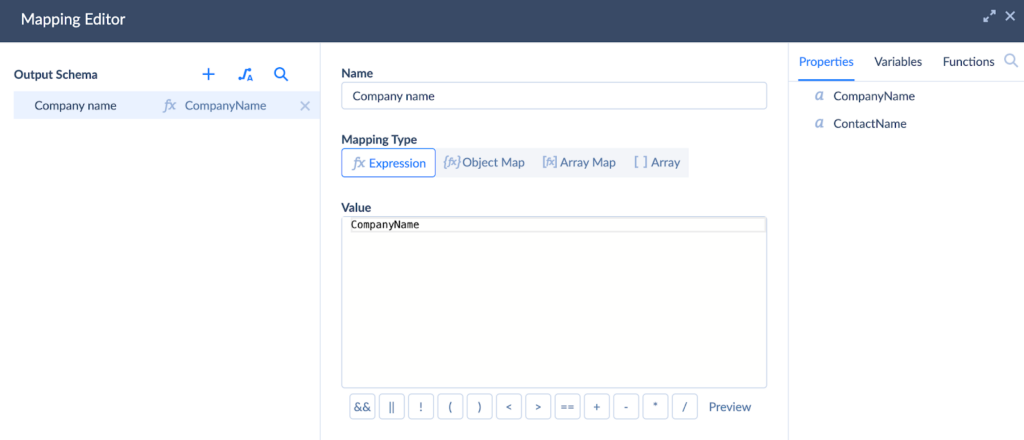
- Click on the output arrow to check the changes in the output results.
Target Setup
The target component defines the system to where you want to load your data.
- Click Target on the left panel and drag it to the diagram.
- Select the data system from the Connection dropdown on the right panel.
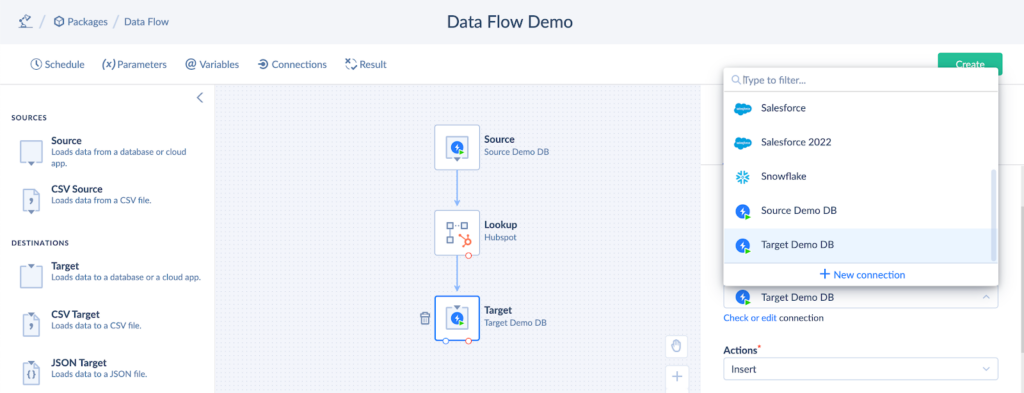
- Select the DML operation (INSERT, UPDATE, DELETE, UPSERT) from the Actions dropdown list.
- Select the Contact table to load data.
- In the Parameters field, map the Lookup output columns with the Contact table columns.
Case Studies of Data Pipelines in Action
In general, data pipelines can be of various complexities. While some may contain 2-3 elements, others may comprise 10+ components. Skyvia is the data integration tool that effectively interconnects all these components. In fact, Skyvia appears in the center of the pipelines and coordinates data flows in a pipeline like a heart coordinates blood fluxes in the cardiovascular system.
Let’s look at several practical use cases where Skyvia was chosen as a data pipeline tool for dataflow management.
Enhanced Inventory Management at Redmond Inc.
The main challenge of Redmond Inc. was to synchronize the information on inventory stocks between Shopify and their internal ERP system. What’s more, they needed to obtain a unified view of orders and inventory stocks.
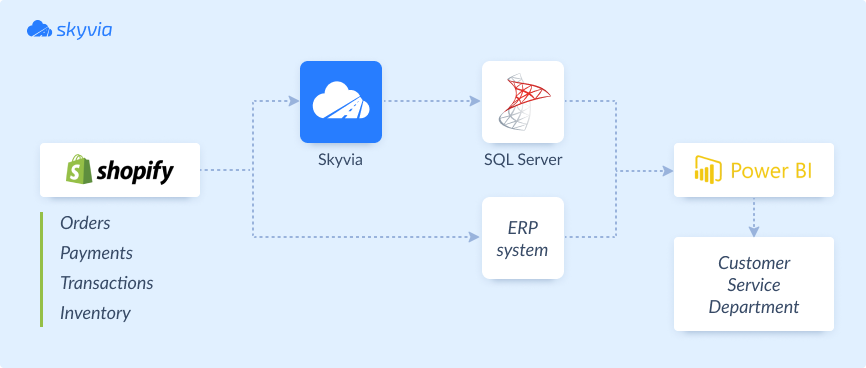
Thanks to Skyvia’s implementation, the company has improved operational management. They also enhanced customer satisfaction since the Customer Service department obtained a complete overview of stock items.
Optimized Workflow at FieldAx
This company is a leading provider of training services, which faced the challenge of managing a geographically dispersed workforce one day. It became demanding to coordinate assignments and track the progress of employees in different counties. What’s more, it was rather expensive to buy licenses for each technician, which often caused budget constraints.

In response to these challenges, FieldAx imported installation details to a local database (MySQL) instead of purchasing individual licenses. Once the data was in place, Skyvia seamlessly synchronized it with the FieldAx software’s corresponding fields, such as technician names, job numbers, and job statuses. Overall, the collaboration between FieldAx and Skyvia has yielded transformative results for the company, enabling them to streamline job management processes while reducing costs significantly.
Automated Data Analytics Pipeline at TitanHQ
This company is a leading SaaS cybersecurity platform delivering a layered security solution to prevent user data vulnerability. Their management team wanted to obtain a 360-degree view of their customers, but that wasn’t easy since data was dispersed across different systems (data warehouse, Sugar CRM, Maxio, ticketing and payment services, etc.
With Skyvia, TitanHQ engineers built data pipelines to gather data from CRM, payment, and ticketing systems into the Snowflake data warehouse. Then, this data was prepared and sent to Power BI to generate dashboards that provided the management team with valuable insights into their customer base.
Conclusion
Data pipeline tools can be of different types and for different purposes. In this article, we have explained the differences between them and have given some hints on when each of them will be the most appropriate. To help you choose the right solution for your data needs, we have also presented popular services for data pipeline management along with their features, advantages, and drawbacks.
We have also presented some real-life examples of how to use such tools to increase the effectiveness of data management within an organization with Skyvia. This platform provides various data integration scenarios suitable for various cases. What’s more, it offers regular scheduling options for automated data flows. Feel free to use Skyvia to organize your data and extract its value.
FAQ for Data Pipeline Tools

Which tool is used for data pipelines?
Skyvia is the data integration tool used to build and manage data pipelines. It links data from databases, CRM systems, e-commerce platforms, and other applications. In total, Skyvia supports 200+ data sources from which you can extract data and load data.
Is data pipeline the same as ETL?
Both data pipelines and ETL processes move data between various systems. In particular, ETL is a subtype of a data pipeline that performs the collection, transformation, and loading of data. Meanwhile, data pipelines in their generalized form also include other stages, such as sending data to end users, which means it’s a more ample process with more stages except for data extraction, transformation, and transfer.
What are the main differences between open-source and commercial data pipelines?
Open-source solutions are free to use, while licensed software is available at a certain price. Open-source tools can be customized, so they provide more flexibility for businesses, while commercial options have a predefined set of tools, as a rule. Open-source tools don’t provide support, so users have to rely on the community in case of issues, while commercial tools provide support teams usually accessible via chat, phone, or email to help users resolve their data integration issues.
