

What’s your first impression of a data pipeline? Maybe you think it’s like oil pipelines with those huge pipes transporting oil to the refinery.
Well, data is the new oil, and it’s expanding. Here’s why: machine learning, for example, feeds on data, and a recent study reveals that this market will grow from $15.50 billion in 2021 to $152.24 billion in 2028. That’s a lot of money! And that’s only about machine learning.
Whether it’s machine learning or data science, you need data pipelines first. But what are data pipelines? And how does it all work? That’s the focal point of this article.
Table of contents
- What Is a Data Pipeline?
- Data Pipeline Architecture
- Data Pipeline Components
- Data Pipeline Processing
- Types of Data Pipelines: Examples and Use Cases
- Data Pipeline vs. ETL
- Building Data Pipelines Using Skyvia – Two Approaches
- Conclusion
What Is a Data Pipeline?
Data pipeline definition as seen in other articles is a series of steps that moves data from the source to the destination. But for starters, this can lead to confusion. While oil in an oil refinery moves oil, data does not move. Moving requires a change of position from point A to point B. Imagine how disastrous this can be when data disappears from the source after moving it to another database for analysis.
Data does not move from the source. A copy is made instead. And from there, it is processed within a chain of tasks. You can say that the copy is the one that moves. You’ll realize this when you build your own data pipeline. So, what really is a data pipeline?
Data pipeline controls the flow of data from one or more sources into the destination through a series of steps. Business rules define how data will flow within the pipeline. Sources can be one or more relational and/or non-relational databases. Or it can also be from social media, devices, and more. Then, from these sources, you get a copy of the data. Then, you either transform it into the desired format or not. And finally, you store it in the destination.
After it’s done, the resulting data can now be used by another system. It can be another transactional system. Or, it’s a data warehouse where key decisions come through a report.
Data pipelines in business can help accelerate digital transformation by processing data for data science and machine learning initiatives.

Data Pipeline Architecture
In its simplest form, a data pipeline architecture involves data sources, the processing steps, and the destination.
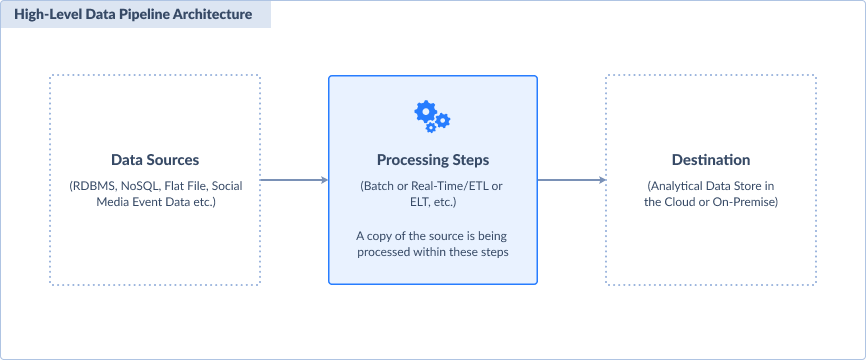
A small-scale data pipeline may use scheduled batch processing. One example is a scheduled dump of a CSV file to a relational database. Another is processing data into a small data warehouse.
But when big data is involved, you need a more robust architecture. One such architecture is Lambda Architecture. It uses both batch and real-time processing in 2 different paths. See it on the screenshot below.
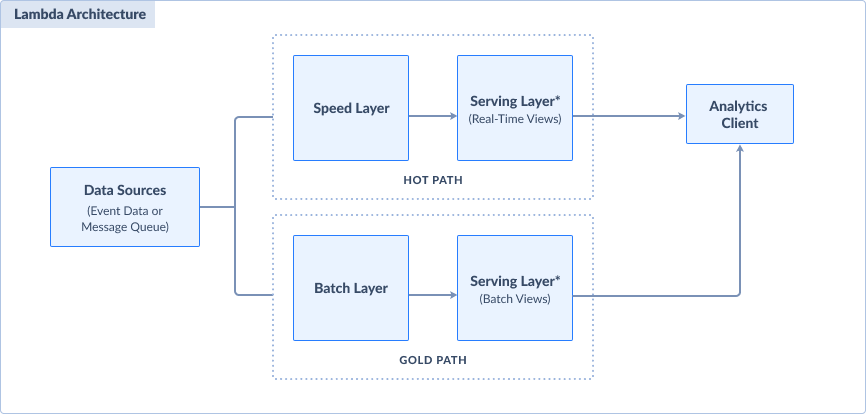
The Lambda architecture fixes a traditional approach to get insights that are several hours old. With this, users have the option to have insights from both real-time and batch data. It uses a very fast data source from streaming data or event streaming. Then, data is processed from these 2 paths:
- Batch layer (cold path) that processes all incoming data in batches. This produces a more accurate view of data for a given period.
- Speed layer (hot path) that processes data as they come in real-time. But this sacrifices accuracy in favor of low latency.
Both these processing layers have serving layers. Serving layers provide processed views of the data for data analytics and reporting. It is also the destination.

Data Pipeline Components
Basically, there are 3 data pipeline components like the one on the first picture. Let’s describe each of them.
Destination
This is the target of the whole process. You start here when designing your own data pipelines. Data marts, data warehouses, and data lakes are possible targets. It can also be a copy of data from another system. And then, this will be consumed by analytics clients or another transactional system. How fast data reaches the destination will affect your hardware and software choices.
Data source or origin
Now, where will the needed data come from? This is your next concern for your pipeline design. You need at least 1 data source. But sometimes it’s more. So, you need to answer this: can the current data sources provide every type of data you need for the destination? If not, you need to discuss it with the users.
Processing steps
Here, you need to figure out the data pipeline steps from the origin to the destination. See the next section for more details.
Data Pipeline Processing
Data pipeline processing involves processing steps. It controls how data will flow along the pipeline. Each step has an input that can be an output of the previous step. If it’s the first step, the input will come from the origin. The last step involves storing the result to the destination. Meanwhile, the pipeline process includes these components:
- Workflow or control flow. If the tool you use has a graphical view of the pipeline, you will see a data processing workflow. This is in the form of shapes and arrows that shows each step going to the next. So, Workflow defines the dependencies of each task.
- Data Flow. One of the tasks in a Workflow can be Data Flow. A data flow defines the location of data, the schema, the fields, and their data types. It can also involve combining 2 or more data sets, sorting, summarizing, and more. Transformation also occurs here. Some of them are combining 2 data fields into 1 or computing a formula and storing the result in a new data field.
- Storage. Sometimes, data needs to be stored before it’s processed further in the pipeline. One example is getting data from 2 different systems into a staging area. Then, from there you can fill a data warehouse.
- Logging and monitoring. For each step, logs are stored for monitoring. Detailed logs are useful in the event of failure to see which task failed and why.
Your requirements and budget will dictate your technology choices to build and process your data pipelines.
Types of Data Pipelines: Examples and Use Cases
Next, let’s dig into data pipeline types, use cases, and pipeline business examples.
Batch
You can process volumes of data in batches from the origin for a specific period. A batch pipeline is also done at regular intervals, like daily at 3:00 AM or every 15th of the month. It is best for business decisions that can wait until the process is done.
USE CASES:
- Data integration between 2 or more systems
- Building a data warehouse for monthly reports and analysis
Example: Bakewell Cookshop integrates retail shop data with BigCommerce using Skyvia. You can check out the case study here.
Cloud
To avoid infrastructure costs and management, an organization may opt for a cloud solution. Cloud data pipelines include some or all of these:
- Storage;
- Pipeline services, like ETL or ELT;
- Servers and other compute resources.
USE CASES:
- The same use cases for batch and real-time data pipelines. But infrastructure and services use the cloud in part or whole.
Example: See an actual example using Skyvia in the next section of this article.
Real-Time
Real-time data pipelines solve the problem of old data in reports. Here, processing happens as the data becomes available. It is best for critical systems with a high amount of data where businesses need to react quickly.
USE CASES:
- Real-time reporting and analysis;
- Streaming data from IoT devices;
- Streaming data from app usage.
Example: Keystone Data Pipeline from Netflix. Read about the Netflix data pipeline from here.
Open Source
If your company finds commercial pipeline tools to be expensive, you can use open-source alternatives.
USE CASES:
- The same use cases for batch and real-time but use open-source data pipeline tools.
Example: LinkedIn’s Air Traffic Controller (ATC) uses open-source tools like Apache Samza and Kafka. Read the case study here.
Data Pipeline vs. ETL
What’s the difference between data pipeline and ETL?
Data pipeline is a general term to which Extract, Transform, Load (ETL) belongs. So, you can say that ETL is a data pipeline. Another data pipeline is ELT or Extract, Load, Transform. But you can’t say that data pipelines are purely ETL.
Also, ETL is a time-consuming batch operation. But a data pipeline can be both real-time and batch operation.
Finally, ETL always ends by loading to a destination. But a data pipeline does not always end with loading. ELT is one example where loading is the second stage, not the last. So, you can’t use data pipeline and ETL interchangeably.

Building Data Pipelines Using Skyvia – Two Approaches
Skyvia allows building data pipelines of various complexity. In this article, we will consider two approaches — easy and complex, and you can choose the one you need for your work.
Easy Approach
This approach allows you to build less complex scenarios. You probably often searched for in the Internet or asked yourself a question, “How do I build a data pipeline with minimum manual efforts, avoiding infrastructure costs and management?” With Replication tool offered by Skyvia, you can do it in three easy steps.
Why exactly a replication? Replication can be a perfect option when you need to move your data from a cloud app or database to another location for storage and analysis. Here are these 3 easy steps on how you can build a data pipeline from scratch but beforehand sign in to Skyvia.

STEP 1: CREATING CONNECTION TO CLOUD APP AND DATA WAREHOUSE
First, we create a source Salesforce connection. We select it among the list of data sources supported by Skyvia. In the opened connection window, we specify environment, select authentication type and sign in to Salesforce. Second, we create a target BigQuery connection almost in the same way.
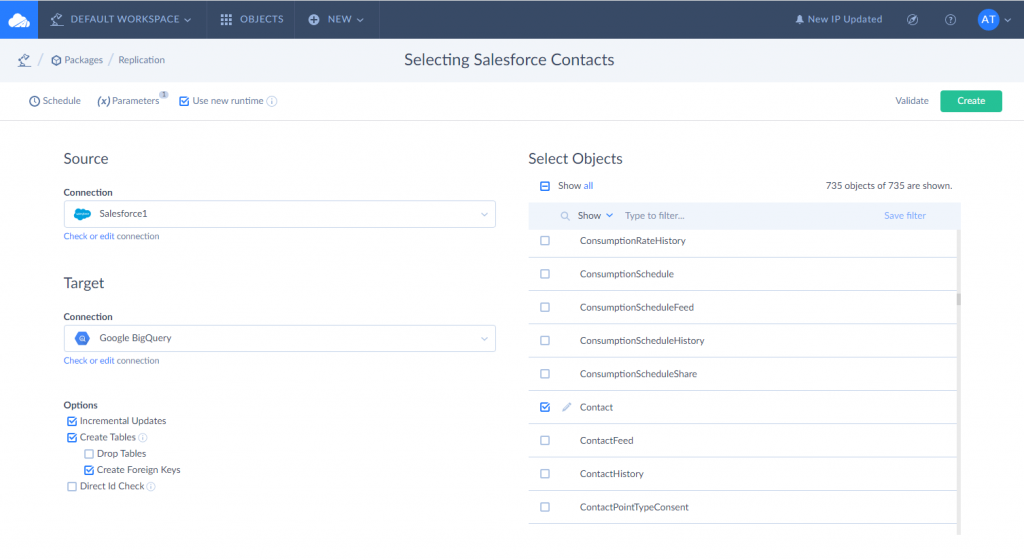
STEP 2: SELECTING SALESFORCE OBJECTS TO COPY TO BIGQUERY
First, select created Salesforce connection as source and Google BigQuery as target. Second, select Salesforce objects you want to copy to BigQuery. Please note that you can configure filter settings for each of the objects you replicate.
STEP 3: AUTOMATING A DATA PIPELINE
This feature might be useful if you want to configure data loading operations to run repeatedly on certain days, at certain hours, etc. The activated data pipeline scheduler will greately minimize your manual labor. What is also important is that Skyvia does part of the job for you.
Once the package is scheduled, the automated data coping starts. If any error occurs, you will be notified about it.
Complex Approach
Now, let us consider a more complex approach. For complex scenarios, Skyvia offers Data flow. It allows you to integrate multiple data sources and enables advanced data transformations while loading data. It can be used in the scenarios when data replication is not enough:
- when you need to load data into multiple sources at once;
- when you need complex, multistage transformations, like lookup by an expression;
- when you need to obtain data from one data source, enrich them with data from another one and finally load into the third one.
Imagine we have a Mailchimp subscriber list and the database table with the list of contacts and their Mailchimp statistics. New subscribers are added to the list, and statistics for existing ones is also updated. In our example, we need to add new subscribers to the database table and keep existing records in the table up-to-date, avoiding duplicated records.
For this, we will create a data flow that checks if a record from source is already present in the target. If the record is present, it will be updated with data from the source. If there is no such record in target, it will be inserted.
HOW TO BUILD A DATA PIPELINE
To create a data pipeline, select a Data Flow package and configure its settings.

Drag components to the diagram one after another, set their properties and connect them on the diagram. The first component we add is a source. The source component will query data from Mailchimp. If you don’t know a Mailchimp list ID for example, you can either get it in the Mailchimp itself or get it with the Skyvia Query tool.
Next we add a lookup component to check if there are matching records in target. Then we add a conditional split component that helps to split records that have a match in the target table and records with no match found. You can perform UPDATE for the records with a match, and INSERT — for records without a match, etc. Afterwards, we add targets, one target is for inserting records, another — for updating. We repeat the steps until we configure the entire data flow. Finally, we add the row count components to count successfully processed rows and error ones. You can read in detail how to set up each of the components in our documentation.
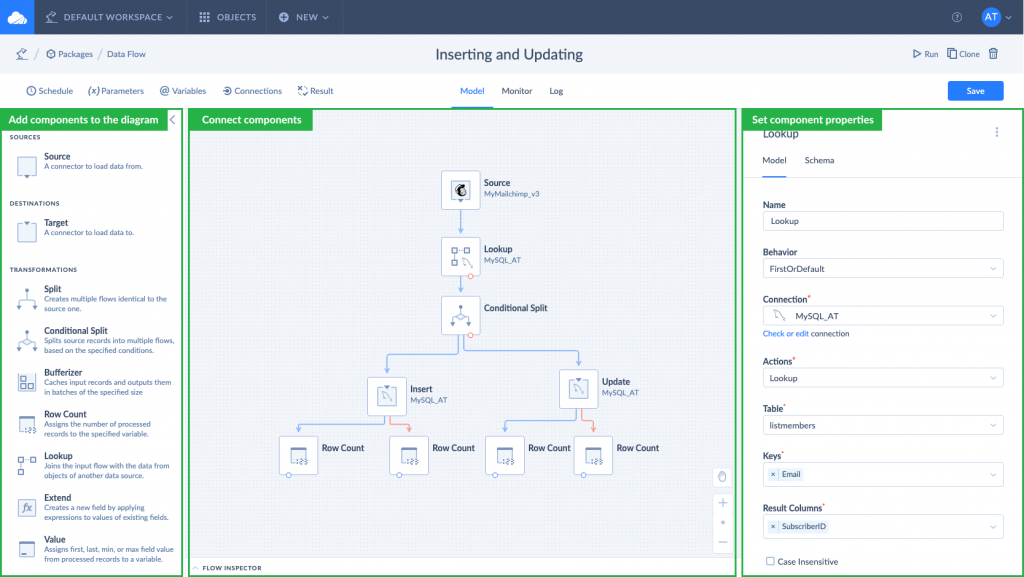
When everything is ready, you can proceed further to schedule a package for automatic execution.
Conclusion
Data pipelines are interesting, aren’t they? So, learn as much as you can to get an exciting job that deals with this.
Do you find this helpful? Please share this article through social media channels.

{kind=link}
{kind=link}