

Companies must be able to measure their performance and develop new strategies to keep up with the competitive business environment. However, significant shifts in digital analytics in the last ten years have led to new crucial challenges shaping how data works today. The first is the rise of cloud technology, and the second is the massive scale of data applied globally. That’s how the concept of the modern data stack appeared.
This article focuses on the meaning of a modern data stack and how to build a modern data stack within broad product offerings in the data analytics space. Here’s what we cover in this article:
Table of contents
- What is Modern Data Stack?
- Modern Data Stack Architecture
- Advantages of Using a Modern Data Stack
- Modern vs. Traditional Data Stack
- Modern Data Stack Tools in 2026
- Build a Modern Data Stack in 30 minutes
- Examples of Applying Modern Data Stack
- Key takeaways
What is Modern Data Stack?
Any business has two main goals: earn more and spend less. Having implemented a modern data stack, a business of any size can make data-driven decisions to reach its goals and evolve faster than its competitors, who still run their business operations in Excel.
Dmitry Alasania, Head of Product Growth at Skyvia
When talking about the modern data stack in a business context, it includes technologies that help companies use data for decision-making. It’s basically the same thing data engineers were already doing, but now using new, cloud-based technologies to create applications that ingest massive amounts of data, run massive data analytics and use those results to generate insights that have never been possible.
As such, the definition of a modern data stack cannot be clearly stated since every business tries to adapt modern technologies to their requirements. However, there are definite features of the modern data stack that identify it:
- It’s cloud-based, requires very little maintenance, is easy to install, and can scale quickly with little effort.
- It can be used by small and medium-sized data teams, as it has a lot of out-of-the-box functionality and doesn’t rely on the number of data professionals.
- It offers a lot of integration opportunities for creating a comprehensive data ecosystem.
Overall, the modern data stack centerpiece is about democratizing data usage: making data more accessible, covering different dimensions of business, improving analytics capabilities, and simplifying the infrastructure.

Modern Data Stack Architecture
Being an all-in-one data integration solution, Skyvia is a Swiss knife for building a strong data architecture without the need to hire a set of tools with different UI-s, functionalities, and billings that need to be managed by a dedicated team.
Dmitry Alasania, Head of Product Growth at Skyvia
Over the past five years, the amount of data processed has increased so much (up to 2025, global data creation is projected to grow to more than 180 zettabytes) that it has become practically unmanageable for small data teams, as they have to work with the growing number of different and disparate data sources.
The age of tribal knowledge is already over: the possibility of simply asking a colleague what kind of data is stored in the dataset is no longer available. Employees now need tools to manage and process data at a scale, from operational analytics and monitoring to data visualization and high-speed accessibility. Accordingly, the Modern Data Stack architecture must meet such requirements.
The commonly agreed categories of MDS architecture are:
- Data ingestion. Usually, data is collected from 1st and 3rd party sources and used to build a single source of truth.
- Data storage. For storing data, it’s better to have two options: a data lake to keep historical data and a data warehouse for interpretation and processing.
- Data transformation. Data is transformed (from compliance of field formats in different data sources to complex data validation), cleaned, etc.
- Business intelligence. Services and platforms used for reporting, analytics, and visualization.
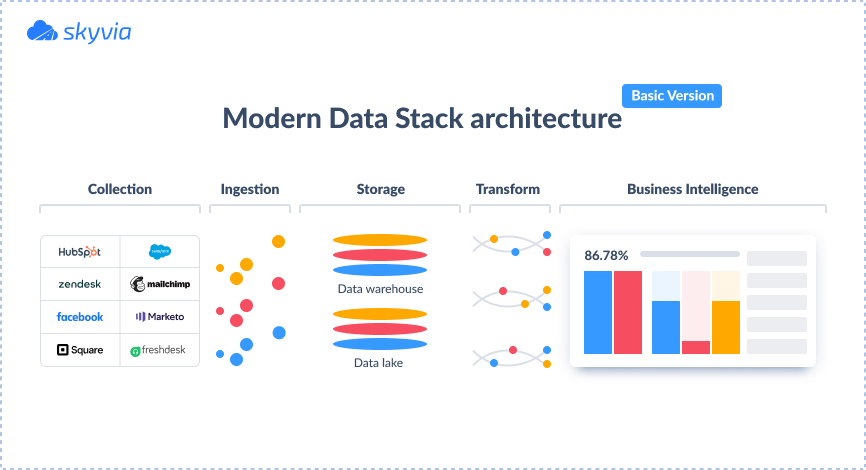
However, it’s an incomplete version that doesn’t fully serve the needs of product and growth teams. A mature MDS should also include:
- Data science. For extracting insights from structured and unstructured data.
- Reverse ETL. For activating data by sending it back to business applications from a DWH.
- Data orchestration. For organizing a large amount of data, which is critical when the modern data stack has just been established. Once the system is up and running, data orchestration becomes a number one priority.
Data quality and governance are also critical, especially when you’ve launched the system and have a large amount of data. Once the system is up and running, data quality will become your number one priority.
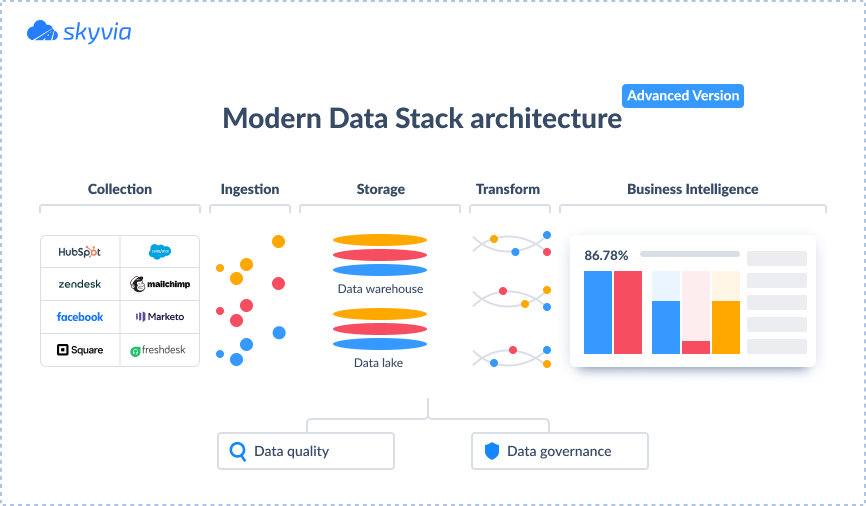
To summarize, a modern data stack architecture must be designed to make the organization’s work with big data efficient: extract the insights from the data and then act upon them in new ways.
Advantages of Using a Modern Data Stack
Switching to a modern data stack might take some time and effort. Anyway, the result pays it off – the MDS brings millions of advantages in a longer perspective, and we explore some of those.
- Optimized Costs. As a modern data stack is deployed in the cloud, there is no need to invest in the maintenance of the on-premises hardware. Spending for IT and engineering teams decreases as everything is set up faster and easier.
- Flexible Scalability. Cloud-based solutions ensure a high degree of scalability, so businesses allocate storage and computing power according to their needs. Getting more or less cloud resources is possible at any time to match the current workload.
- High Customizability. Modern data stack keeps modularity in mind – ensuring compatibility of its components. This means businesses are flexible in picking up tools for data intelligence, data transformation, and other processes without worrying about how to colligate them.
- Superior Data Governance. At any stage of the lifecycle, a modern data stack ensures superior data governance.
- Real-Time Data Processing. An MDS may comprise technologies that support real-time data processing and analytics.
- Big Data Support. Owing to the distributed architecture of the cloud solutions included in an MDS, storing and processing large amounts of data is no longer rocket science.
Modern vs. Traditional Data Stack
If the advantages of MDS don’t seem convincing enough, let’s have a look at how it differs from the traditional data stack. Such a comparison helps businesses decide whether they really need it or if they’re good to go with the traditional one.
| Traditional Data Stack | Modern Data Stack |
|---|---|
| Hosted on-premises | Hosted in the cloud |
| Has coupled structure | Has modular structure |
| Complex setup requiring large IT teams | Less time on technical configuration |
| Requires serious technical background | Suitable for users without extensive technical background |
| Contains traditional RDBMS | Works with RDBMS as well as big data, unstructured data |
Modern Data Stack Tools in 2026
Every year, the number of tools on the data/AI landscape increases rapidly as market leaders and a new generation of data startups enrich their product offerings. As seen on the annual map by Matt Turcks, there are literally myriads of various products in each category, so how can you choose the best tools for your modern data stack?

It takes a lot of planning to get a clean and neat data stack, as every tool and application should be flexible and work harmoniously with each other. Companies are embracing the use of microservices and REST APIs that break apart the entire data architecture into more manageable pieces, allowing businesses to choose the right tools for separate problems.
Each component should be self-reliant enough to be swapped out independently of the other. It shouldn’t take a Ph.D. to understand what it does, so you can change it for another that works better for you, saving time and money.
While data architectures vary by company, there still are the core components used in almost all modern data stacks.
Data Ingestion
Ensuring that all the teams in a company use the same data and operate within a single source of truth is one of the essential features. Data ingestion is a process of taking data from one place and moving it into a different place to make it available for further manipulation and analysis.
Popular options: Stitch, Fivetran, Skyvia.
Data Warehouse
Data volumes continue to grow, and, as a result, companies mainly orchestrate various tools and frameworks based on relational databases. Meanwhile, NoSQL databases are ideal for storing unstructured data; with some effort, they can be deployed in hybrid environments. However, these databases lack compatibility with most tools used in such environments.
As a result, companies are shifting to cloud data warehouse solutions to overcome these limitations.
Popular options: Azure, BigQuery, Snowflake, Redshift.
ETL Data Transformation
Data transformation is about changing data from one structure or format to another structure or format. These steps are crucial in data integration since they prepare data for further analysis, visualization, and reporting. It’s done using extract, transform, and load (ETL) techniques.
Popular options: dbt, Skyvia, Improvado.
Reverse ETL
Reverse ETL tools construct a data pipeline, where a DWH is a source and a business app is a target. They extract data from a data warehouse, transform it to match the format of the destination platform, and load it there. That way the operational teams obtain the data they need right in the business applications of interest, and can work with it onwards.
Popular options: Polytomic, Skyvia, Census.
Data Orchestration
Data orchestration tools automate data collection from various sources by configuring multiple data streams. They also consolidate data in the target platform for its further use in analysis or forecasting.
Popular options: Prefect, Skyvia, Apache Airflow.
Business Intelligence
Business intelligence tools are in charge of analyzing data and then presenting it to users in an easy-to-understand manner. They transform data into visual elements such as charts, graphs, and tables.
Almost all business intelligence tools are capable of helping non-technical users understand and analyze data without the need for any programming knowledge.
Popular options: Tableau, Power BI, Google Data Studio.
Data Science
Similarly to BI tools, data science applications analyze data and extract valuable insights from it. What makes them different from BI solutions is that data science tools predict and forecast the future of business based on the already existing data.
Popular options: Apache Spark, Project Jupyter, SAS.
While choosing the modern data stack tools, consider the following moments to ensure that your stack is future-proof:
- Services should be flexible enough to adapt quickly to new platforms, tools, or technologies.
- Product is capable of scaling with large volumes of data.
- The customer support team provides a fast response to customer inquiries and issues.
- Governed data should be accessible by all solutions, consumable by every tool that uses it, and not disrupt when one tool is swapped for another.
- Reasonable and flexible pricing plans that can be changed according to business goals.
- You need no special qualifications to get started working with the services.
Build a Modern Data Stack in 30 minutes
Advanced data tooling historically has been a costly endeavor. But thanks to the latest cloud computing innovations, it’s easier than ever to set up a data stack and use it to power real-time analytics solutions.
Regardless of your business size, it’s possible to implement a cloud-based warehouse with data from multiple sources connected to an analytics/business intelligence (BI) platform that’s up and running fast.
The foundation of your modern data stack is built on three pillars: a cloud-based warehouse, data pipelines, and an analytics platform.
Step 1. Choose a cloud-based data warehouse
If you want to store and process data efficiently, you need a cloud-based warehouse — the foundation of a modern data stack. With cloud-based solutions, businesses will have fewer data infrastructure and management costs, as well as the ability to seamlessly access data from any device.
As the need to manage the data becomes more complex, it’s only natural that organizations spend more time trying to manage this environment. Today, cloud-based services can handle performance and scaling details in a variety of ways, through an administrative interface, with few requirements from the engineering team.
What to consider?
- Easy to set up and maintain
- Existing technology stack
- Uses plain SQL
- A strong ecosystem
- Cost and cost control
Popular options: Azure, BigQuery, Snowflake, Redshift.
Step 2. Integrate data from all of your applications
You should find a data pipeline management tool that provides scalable data loading options, can capture data from various systems (e.g., CRM, billing systems, inbound marketing platforms, etc.), and store diverse data streams in the data warehouse of choice.
What to consider?
- Connection to all data sources business needs
- How reliable it is
- Data extraction at the frequency of business needs
- Uses plain SQL
- Cost and cost control
Since Skyvia meets all these requirements, let’s see how it can help businesses of all sizes in covering their needs while creating a Modern Data Stack.
Skyvia is an all-in-оne, cloud-based platform for data integration that performs different integration techniques and supports a broad set of integrations, including over 200 cloud applications and the most widely used databases and cloud data warehouses.
It’s flexible enough to support a wide range of data integration scenarios, it includes cloud application data import and export functions (ETL, ELT, Reverse ETL), database import and export, one-direction and bi-directional synchronization.
Skyvia offers business solutions for all sizes of businesses: its pay-as-you-go pricing and scaling capabilities support businesses upon evolvement. You can begin applying Skyvia as a startup with just a few gigabytes of data, and it can be further adapted as the team collects terabytes of data. Whether it’s a small or medium-sized business or a larger one, Skyvia has the solution for you.
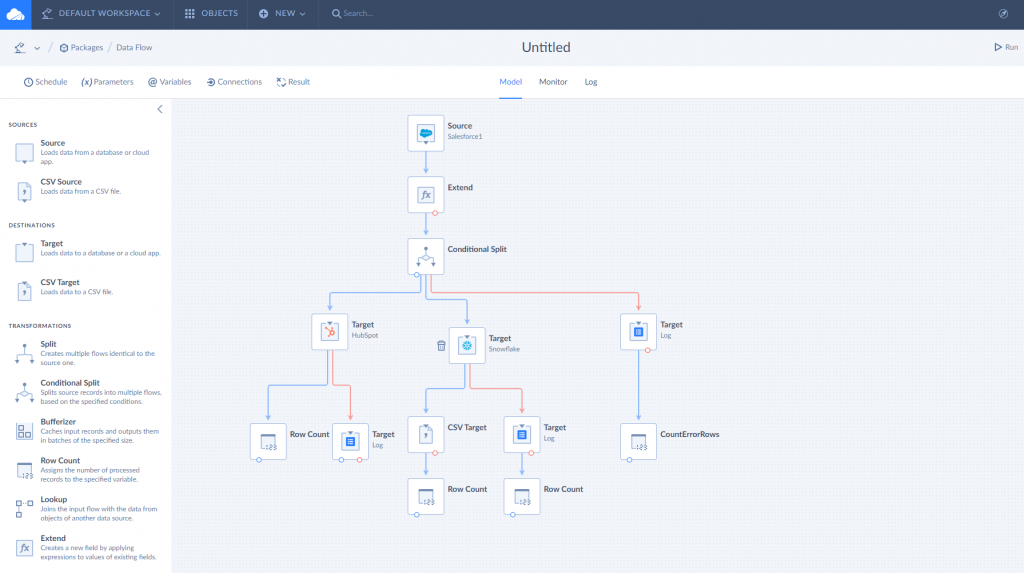
Sometimes, more often than we all would like, real-life integration scenarios are complex and require a more flexible tool. Skyvia offers Data Flow and Control Flow features that are applied for such complicated business cases as:
- Complex, multistage transformations.
- Running integrations in a specific order.
- Obtaining data from one data source, enriching it with data from another one, and finally load into the third source.
- Performing pre- and post-integration tasks.

Popular options: Skyvia, Stitch,and best ETL tools in 2026.
Step 3. Analyze the data
Now that the data is available (extracted, loaded, and transformed), you need a tool to analyze it. While choosing the proper tool, keep in mind that self-service analytics and business intelligence (BI) tools let business users work directly with data and gain insight. The difference between showing and seeing data cannot be overstated, as visual presentation is a real superpower. In a nutshell, dashboards are as useful for managers as control panels are for drivers.
Today’s BI tools help non-technical users explore data without needing to know SQL. It frees business users from depending on developers and analysts and encourages everyone to explore and learn from data.
What to consider?
- Ease of use and scalability
- Vendor ecosystem
- Cost
- Deliver results quickly
- Uses plain SQL
- Easy to share
Popular options: Tableau, Power BI, Looker, etc.
Examples of Applying Modern Data Stack
Thanks to the modularity of the modern data stack, it assures a kaleidoscope of tool composition options. Here we would mention only some examples of such combinations in applying the MDS across industries:
- Analytics team using Skyvia + SQL Server + PowerBI.
In this case, Skyvia is used for data ingestion, transformation, and loading in SQL Server. As SQL Server goes under the Microsoft license, it perfectly coordinates with PowerBI for analytics and reporting. - Product growth team using Snowflake + Skyvia + HubSpot.
In this case, Snowflake accumulates data from multiple data sources (Microsoft Dynamics, Shopify, Dropbox). After transforming data into a unified format, Skyvia applies reverse ETL to move it to HubSpot. Marketing and product growth teams have a unified view of the customer base, which provides insights into customer behavior and preferences, allowing them to customize marketing and ad campaigns, improve retention rates, and so on.
The contents of a data stack may vary across the companies depending on the industry of operation. Some businesses would prefer a data warehouse (Snowflake, Amazon Redshift, Google BigQuery), while others would need a data lake (Amazon S3) for storage. Depending on the data flow, some companies might select ETL tools (Skyvia, Talend) for data ingestion and transformation, while others might require real-time data processing tools (Apache Kafka). Those who need deep analysis of the incoming streams would benefit from data intelligence and data science applications (Looker, Tableau).
Key takeaways
As data itself is turning into the product, there’s a shift in how companies run their data functions. The world of business has never been as digital or cloud-focused as it is today, meaning that people can finally reach their desires in working with data together with their ability to work with data. Moreover, the human dimension has also changed a lot as there are now more and more data-literate people.
Obviously, these shifts in the digital landscape open up extensive opportunities for businesses. Can Modern Data Stack become a lingua franca on how data is transformed, accessed, and queried? Is it bending the curve? With modern data architecture, companies can quickly build a real-time data stack and get it up and running. Among the reasons for applying it, we can mention such wishes as:
- Reducing engineering time spent on maintaining the data analytics services.
- Outgrowing of manual reporting throughout businesses.
- Better integration of the data from multiple systems.
- High costs of analytics platform.
Modern Data Stack provides businesses with a bias for action. Creating the modern data stack enables organizations to devote more time to analyzing their data and less time engineering their data processing pipelines.
Since inaccurate or out-of-date data can cause companies to miss opportunities, waste money, or incur unnecessary risk, we recommend using flexible platforms with lots of features like Skyvia. It’s flexible and robust enough to handle answers to complex business questions.

