

Summary
- Google BigQuery is a serverless data warehouse that can store large amounts of structured and semi-structured data.
- ETL (Extract, Transform, Load) is essential for preparing data for analysis, ensuring accuracy and consistency.
- The ELT (Extract, Load, Transform) approach allows for faster data processing and is increasingly used with BigQuery.
- When selecting an ETL tool for BigQuery, consider factors such as available connectors, ease of use, scalability, and security.
- Skyvia is highlighted as a top ETL tool for BigQuery due to its user-friendly interface and extensive connector options.
Google BigQuery has become a leading solution for storing and processing big data. Since it doesn’t generate data by itself but collects it from other sources, you will need a decent ETL tool to extract, transform, and load data into a data warehouse. Without proper ETL solutions, BigQuery may end up processing inaccurate or inconsistent data, leading to unreliable business insights.
In this article, we observe a number of ETL tools for BigQuery. We also explore the functionality and specifics of each ETL tool and help you select the right one for your particular business case.
Table of Contents
- What Is Google BigQuery?
- What Is ETL?
- What Is ELT?
- Selection criteria for the best BigQuery ETL solution
- Top 10 Google BigQuery ETL Tools
- Conclusion
- FAQ
What Is Google BigQuery?
BigQuery is a serverless data warehouse included in the Google Cloud Platform. It can store large amounts of structured and semi-structured data coming from different sources. This data warehouse is widely used by data scientists and data analysts working in different industries since it provides a uniform way to work both with structured and unstructured data. BigQuery also offers robust security and high availability that grants 99,99% uptime SLA.
Google BigQuery integrates with the machine learning module and analytics engine right within the Google Cloud Platform itself. This ensures the processing of large data sets, allowing users to make forecasts and get instant insights into business process improvements.
What Is ETL?
ETL is a well-known approach to moving data, which originated in the 1970s. It involves a three-step process: data extraction from source systems, transformation (cleansing, filtering, organization, etc.), and loading into the destination system.
BigQuery with ETL is a win-win mix for preparing data for analysis beforehand. Since the transformation step takes place before the actual data loading in a data warehouse, the data arrives normalized and ready for use. Using ETL processes with BigQuery is a great way to reduce time to insights and spend less time on data organization within a data warehouse.
What Is ELT?
The ELT approach is also commonly used to load data into Google BigQuery in the contemporary data integration landscape since it can handle large data sets and ensure high loading speed. The ELT has the same stages as ETL, though the transformation occurs at different moments of time. With ELT, data is transformed and processed on the data warehouse side using such tools as dbt, for instance, which makes this approach faster and more adapted to the current data volumes. Here are some other benefits of ELT over ETL:
- Better scalability
- Support of unstructured data
- More flexibility for data analysis
- Easy detection of data inconsistencies
In this article, we’ll use the unified term ‘ETL tool’ to describe data integration services that support both ETL and ELT approaches in data integration.
Selection criteria for the best BigQuery ETL solution
With dozens of options for BigQuery ETL, it might seem challenging to choose the right tool. Before making the final decision, you need to think of the integration scenarios and data sources involved. Consider these criteria to select the appropriate ETL tool.
- Pool of available connectors. First, decide which services you need to transfer data to BigQuery. See whether these tools that interest you are on the list of pre-built connectors for simplified data integration. Explore whether there is an ability to create new connectors.
- Data transformations. The transformation of data is the core module of the ETL process. Explore the transformation capabilities of a tool and decide how they match your needs for organizing and preprocessing data.
- Ease of use. To build ETL and ELT pipelines easily and quickly, it’s necessary to select a data integration tool that guarantees ease of use. See whether a data integration platform has an intuitive interface and allows you to create data pipelines without coding.
- Scalability. Ensure the tool can handle growing data volumes and complex workflows without compromising performance.
- Security. Data protection is the paramount duty of any digital solution. Explore whether an ETL tool corresponds to modern security standards and protocols and whether it’s compliant with data protection regulations, such as GDPR.
- Support and Documentation. Evaluate the availability of customer support, community resources, and comprehensive documentation for troubleshooting and learning.
- Pricing. Carefully inspect the pricing plans of the ETL tools of your interest. Decide which ones correspond to your data coverage, connectors of interest, and other useful features. See how the price meets your budget expectations.
Top 10 Google BigQuery ETL Tools
In this section, we provide a comprehensive list of ETL tools for BigQuery. You will also discover key features, limitations, pricing, and common use cases for each of these services. Let’s start with the comparison table.
| Platform | G2 Rating | Key features | Pricing |
|---|---|---|---|
| Skyvia | 4.8 out of 5 | – 200+ sources – Powerful transformation capabilities – Detailed logs of errors | – A free plan is available – Price starts at $79/mo |
| Google Cloud Data Fusion | 5.0 out of 5 | – 150+ pre-built connectors – Limited custom transformations | – Three editions available – Price starts at $0.35 per instance/hour |
| Dataddo | 4.7 out of 5 | – 300+ connectors – Zero-code UI – Gaps in documentation | – A free tier with a limit of 3 data flows – Price starts from $99/month |
| Hevo Data | 4.4 out of 5 | – Over 150 supported connectors – Requires Python knowledge – Supports reverse ETL | – Free plan with 50 free connectors – Three pricing plans available |
| Integrate.io | 4.3 out of 5 | – 150+ supported connectors – No-coding visual pipeline designer – On-premises connectors are supported in a $25000-plan or higher | – A free trial period – Pricing plans start at $15,000 per year |
| Talend | 4.0 out of 5 | – Over 1000 supported connectors – Extendable using Python | – Pricing isn’t publicly available; you need to contact the sales |
| Fivetran | 4.2 out of 5 | – 300+ connectors supported – Custom connector creation is available – Post-load data transformation via SQL | – A trial period is available – Several pricing tiers with different features |
| Stitch | 4.4 out of 5 | – No-coding integration configuration – Extensible via REST API – Limited transformation features | – A free trial period – Pricing plans start at $100 per month for 5 million records |
| Apache Spark | 4.2 out of 5 | – Supports different programming languages – Requires coding skills – No dedicated technical support | – Available for free |
| Keboola | 4.7 out of 5 | – Pre-built connectors for data sources – Programming language is required to perform data transformations | – A free tier with a limit – Custom pricing |
1. Skyvia
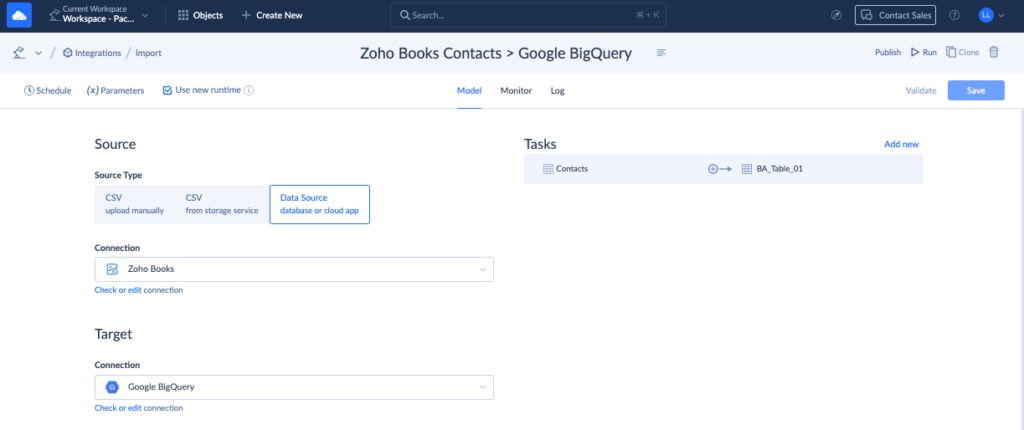
Skyvia is a powerful cloud data platform that solves data integration tasks without coding. It offers tools for different use cases and supports all major cloud applications, databases, and data warehouses.
Skyvia offers such data integration tools:
- Replication tool is a wizard-based ELT solution designed for fast and simple data copy to BigQuery (or another data warehouse) and keeping it up-to-date.
- Import tool is a wizard-based solution suitable for creating ETL and Reverse ETL tasks using a convenient, user-friendly interface.
- Data Flow is a visual data pipeline designer used for advanced ETL scenarios. It allows you to move data across multiple data sources and build complex multistage transformations.
Reviews
G2 Rating: 4.8 out of 5 (based on 200+ reviews).
Key Features
- Intuitive GUI that makes Skyvia easy to set up and use.
- Connectivity with 200+ sources.
- A variety of tools for multiple data integration scenarios.
- Support of ETL, Reverse ETL, and ELT pipelines.
- Powerful transformation capabilities.
- Detailed logs of errors.
- Email notifications are sent to signal integration status, limits exceeded, etc.
Limitations
- Limited integration capabilities compared to tools for data integration that support coding.
- Features are limited in the Free plan.
Pricing
Skyvia has several different pricing plan tiers for different data volumes and feature sets. The pricing plan doesn’t depend on the number of users or connectors used or the number of created integrations – these numbers are unlimited in any plan. A free plan is also available, but it includes limited ETL features and tools.
- Basic plan starts at $79/month.
- Standard plan starts at $79/month.
- Professional plan starts at $199/month.
- The price for the Enterprise plan is custom.
Best Suited for
Skyvia is suitable for companies of all sizes that are looking for a cloud-based platform for ETL, ELT, and Reverse ETL with minimal coding requirements. Its affordability and ease of use make Skyvia an excellent choice for businesses that need to connect SaaS apps, cloud services, and databases efficiently.

2. Google Cloud Data Fusion
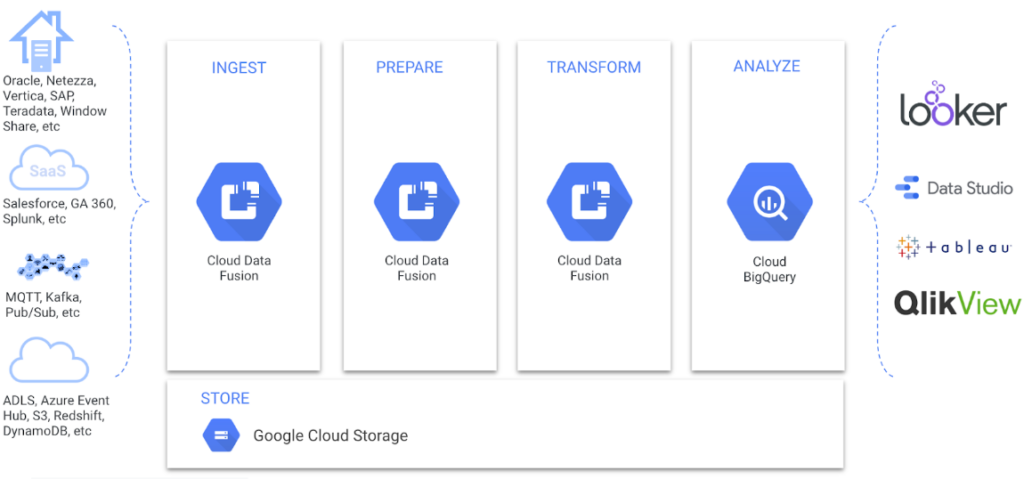
Data Fusion is a product on Google Cloud that is designed for ordinary data integrations and transformations. It offers a visual no-code interface for deploying code-free ETL pipelines.
This tool can extract data from various cloud and on-premises sources and load it to BigQuery. Data Fusion also has a number of pre-configured transformations suitable for both batch and real-time processing.
Reviews
G2 Rating: 5.0 out of 5 (based on 2 reviews).
Key features
- Centralized management of data pipelines.
- Graphic UI promotes reduced complexity of ETL pipeline deployment.
- Support of 150+ pre-built connectors and transformations.
Limitations
- The graphic user interface is not adapted for creating complex data pipelines.
- Limited custom transformations.
- Less control over infrastructure.
- Issues with data inaccuracy.
Pricing
Data Fusion comes in three editions:
- The Developer plan starts at $0.35 per instance/hour.
- The Basic plan starts at $1.80 per instance/hour.
- The Enterprise plan starts at $4.20 per instance/hour.
Best Suited for
Google Cloud Data Fusion is a good choice for companies that require a fully managed and scalable solution for complex data integration. It performs well at integrating data across hybrid and multi-cloud environments. Google Data Fusion supports advanced use cases such as big data processing and real-time analytics, which makes it a good choice for cloud-native teams handling diverse data workflows.
3. Dataddo
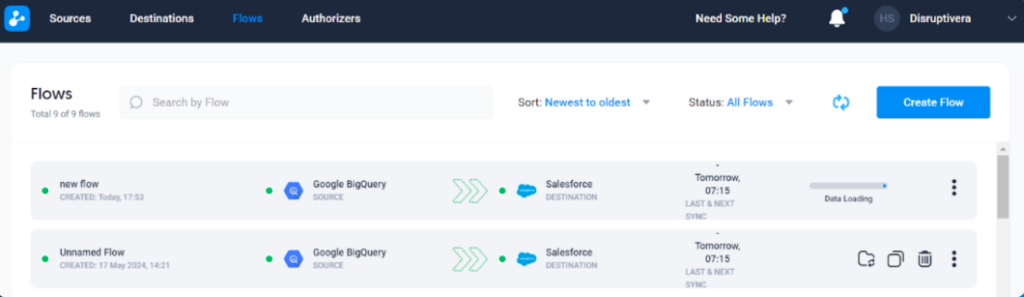
Dataddo is a no-code data integration platform for creating ETL, ELT, and Reverse ETL pipelines. This tool primarily focuses on sending data from cloud-based sources to databases, data warehouses, and BI tools.
Dataddo allows users to implement data pipelines both for real-time and batch processing. You can also automate the extraction and loading of data by selecting the regular update intervals.
Reviews
G2 Rating: 4.7 out of 5 (based on 180+ reviews).
Key features
- Zero-code UI for building and deploying data pipelines.
- 300+ connectors for both source and destination applications.
- Testing of data models before sending data to BI apps.
Limitations
- Gaps in documentation.
- Sync frequency needs to be improved.
- Not suitable for complex data pipelines.
Pricing
Dataddo comes in four editions:
- A free tier with a limit of 3 data flows.
- Data to Dashboards allows users to load data in BI and visualization tools. The price starts from $99/month and depends further on the number of needed data flows.
- Data Anywhere allows users to load in any available destination. The price starts from $99/month and depends further on the number of needed data flows.
- Headless Data Integration for custom integrations.
Best Suited for
Dataddo is best suited for business teams in marketing, sales, and operations that need to connect data from SaaS tools like HubSpot or Salesforce to analytics platforms. Its no-code approach and focus on flexibility make it ideal for non-technical users who aim to create lightweight, analytics-ready pipelines for dashboards and reports with minimal IT involvement.
4. Hevo Data
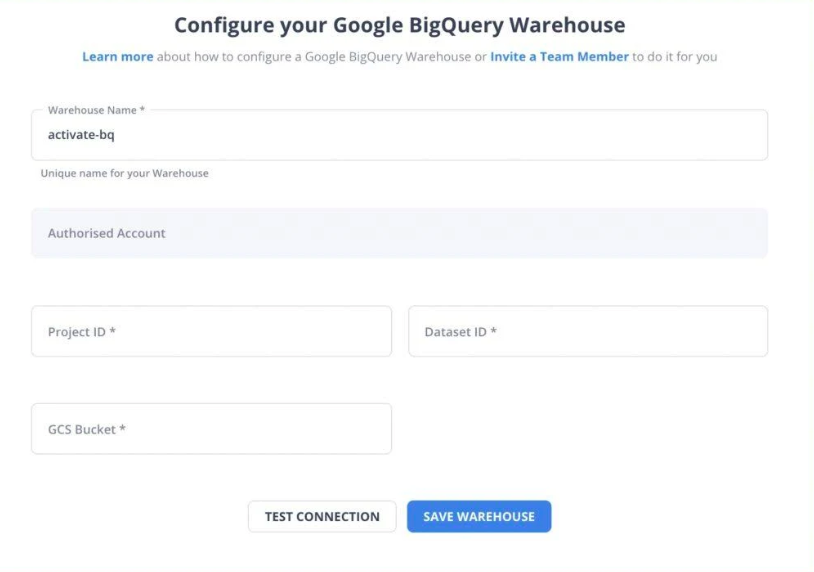
Hevo Data is an end-to-end data pipeline platform that allows the quick loading of data from different data sources to a data warehouse. Hevo positions itself as an ELT tool and includes transformation features. It consists of both visually configurable transformation blocks and Python code-based transformations.
Hevo Data can also automatically detect and map the source schema to the destination. It can also handle schema drift, signaling that the data structure changes on the source. All this tends to reduce the manual input for schema management.
Reviews
G2 Rating: 4.4 out of 5 (based on 200+ reviews).
Key features
- Over 150 supported connectors.
- Near-real-time data loading to some destinations.
- Ability to schedule data loading to other sources.
- Supports reverse ETL from BigQuery.
Limitations
- Requires Python knowledge for advanced data transformations.
- Personal addresses, such as Gmail or Outlook, are not allowed.
- Only 50+ free connectors.
- Data from BigQuery can only be loaded to cloud data warehouses and relational databases.
Pricing
Hevo Data pricing plans differ in support options and the number of events (new or modified records). There are three pricing plans available:
- Free plan with 50 free connectors, 1000000 events, and email support.
- Starter plan with up to 100 mln events, all the supported connectors, and 24×7 live chat support added.
- Custom plan if you have even higher needs.
Best Suited for
Hevo Data is a good choice for fast-growing companies that need real-time, automated pipelines for synchronizing operational data with cloud warehouses. It’s optimized for handling large volumes of structured and semi-structured data, which makes it ideal for companies that scale their analytics infrastructure and aim to quickly implement ELT workflows with minimal setup.
5. Integrate.io
Integrate.io is a no-code data pipeline platform. It supports ETL, reverse ETL, ELT, CDC, API generation, etc. It allows visually designing data pipelines on a diagram by dragging and connecting components – sources, transformations, and destinations – without coding.
At the same time, Integrate.io offers advanced customization options for development. It allows for pipeline design for batch and real-time data pipelines, applying the needed transformations on the go.
Reviews
G2 Rating: 4.3 out of 5 (based on 200+ reviews).
Key features
- 150+ supported connectors.
- No-coding visual pipeline designer.
- ETL, reverse ETL, ELT, CDC, etc. tools.
Limitations
- Available connectors are more focused on the e-commerce use cases.
- Cannot synchronize the data in real-time.
- On-premises connectors are supported in a $25000-plan or higher.
Pricing
Pricing plans start at $15,000 per year. This only includes two connectors and daily scheduling and limits the number of concurrently running packages to three. Additional clusters can be purchased at extra cost for a greater number of concurrently running packages.
The next pricing tier starts at $25000, including on-premises connectors, 99.5% SLA, and other features. There is also the custom Enterprise plan with a negotiable price.
Integrate.io also provides a free trial period.
Best Suited for
Integrate.io is a good option for e-commerce and retail businesses that require a low-code platform for data migration and transformation. Its drag-and-drop interface and pre-built connectors to Shopify, Salesforce, and other platforms, make it a top choice for teams focused on customer analytics to obtain better marketing and operational insights.
6. Talend
Talend offers several different products for performing ETL tasks. It has an open-source Talend Data Studio as well as paid ETL services – Talend Data Fabric. The Talend Data Fabric includes the Talend Studio, Stitch, Talend Big Data, Management Console, API Services, Data Inventory, Pipeline Designer, Data Preparation, and Data Stewardship.
Talend Solutions supports over 1000 connectors and offers a Talend Component Kit to add custom connectors. There are pre-built integration templates and various components to ease data-related processes.
Reviews
G2 Rating: 4.0 out of 5 (based on 65 reviews).
Key Features
- Over 1000 supported connectors.
- Open-source tool available.
- Extendable using Python.
Limitations
- Talend Data Fabric is costly.
- Pricing isn’t publicly available; you need to contact the sales.
Pricing
Talend pricing isn’t publicly available. You need to contact sales to discuss pricing. However, Talend offers a free trial. You can also use their open-source Talend Data Studio for free.
Best Suited for
Talend is best suited for mid-to-large enterprises requiring robust integration and governance capabilities. Talend’s strengths come from its open-source roots and enterprise-grade features, which makes it perfect for managing complex ETL workflows, ensuring data quality, and complying with regulations in industries like healthcare, finance, and manufacturing.
7. Fivetran
Fivetran is an automated data movement platform that moves data between different sources using API interfaces. It allows business users to create and deploy data-driven reports and dashboards based on data from their primary data sources.
Fivetran relies on automation to effectively handle schema changes, significantly minimizing manual input. This makes it a popular choice for streamlined data replication using the ELT approach.
Reviews
G2 Rating: 4.2 out of 5 (based on 380+ reviews).
Key Features
- 300+ connectors supported.
- Custom connector creation is available.
- Streaming data loading support.
- Post-load data transformation via SQL.
Limitations
- No data loading to cloud apps.
- No sync schedule by a fixed time.
- No data transformations are available before sending data to the warehouse; they are only applied afterward.
Pricing
Fivetran pricing is mostly volume-based and feature-based. There are several pricing tiers with different features available, and for each tier, the monthly quote depends on the number of records loaded per month. The more records you load, the less your cost per row for the next rows. A trial period is available for several pricing plans.
Best Suited for
Fivetran is good for organizations seeking a hands-off approach to ELT pipelines that prioritize reliability and scalability. It automatically adjusts to schema changes in source systems, making it ideal for teams that want effortless maintenance and continuous data replication to cloud warehouses like Snowflake, BigQuery, or Redshift.
8. Stitch

Stitch is a popular ETL tool to help you load data from various cloud apps and databases to cloud data warehouses and databases. It was acquired by Talend in 2018. After that, it continues to operate as an independent unit.
Stitch supports over 130 connectors to cloud apps, databases, and file storage.
Reviews
G2 Rating: 4.4 out of 5 (based on 60+ reviews).
Key Features
- No-coding integration configuration.
- Extensible via REST API.
- Enterprise-grade security and data compliance.
- Integration with Singer open-source framework.
Limitations
- Limited transformation features.
- It supports ETL in BigQuery but not from BigQuery.
Pricing
Stitch pricing plans start at $100 per month for 5 million records. The number of records per month can be customized. The high-tier pricing plans offer more features and a larger amount of rows. Stitch also offers a free trial period.
Best Suited for
Stitch is suitable startups and small teams seeking an affordable, straightforward ELT tool to move data from popular sources like MySQL, MongoDB, or Stripe into analytics warehouses. Its simplicity and transparent pricing make it ideal for companies starting their data integration journey or testing out analytics use cases.
9. Apache Spark
Apache Spark is an open-source data transformation engine. It allows batch data transfer, data analysis with ANSI SQL queries, performing Exploratory Data Analysis (EDA) with huge data volumes, machine learning, etc.
Apache Spark supports different file formats and databases via JDBC and has a number of third-party connectors, including connectors to Google BigQuery, Snowflake, etc.
Reviews
G2 Rating: 4.2 out of 5 (based on 40+ reviews).
Key Features
- Support both structured and unstructured data.
- Supports different programming languages.
Limitations
- Requires coding skills.
- No dedicated technical support.
Pricing
This is an open-source solution available for free.
Best Suited for
Apach Spark is good for large organizations handling massive datasets and real-time data stream processing. It also supports machine learning and advanced analytics workflows, which makes Apache Spark indispensable for data engineering teams working on big data applications.
10. Keboola
Keboola is a self-service data management platform suitable for designing ELT pipelines. It also has data transformation and orchestration features for organizing data on the go.
Keboola offers powerful automation features for data transfer scheduling and management. This allows businesses to prioritize their mission-critical tasks and minimize manual intervention.
Reviews
G2 Rating: 4.7 out of 5 (based on 90+ reviews).
Key Features
- Many pre-built connectors for data sources.
- Centralized management of data pipelines.
- Scalable data pipelines handling large data volumes.
- AI-driven data management tasks automation.
Limitations
- Programming language is required to perform data transformations.
- Error messages aren’t self-descriptive.
Pricing
Keboola offers a free tier with a limit of 120 minutes of computational time for the first month and 60 minutes for subsequent months. In general, it offers custom pricing, which depends on the individual needs of each business.
Best Suited for
Keboola is suitable for companies with data-heavy operations that need an all-in-one solution for extraction, transformation, and orchestration. With strong collaborative tools, built-in data governance, and modular features, Keboola helps teams involved in complex analytics workflows that span multiple departments or involve diverse data sources.
Conclusion
In today’s fast-paced business environment, companies face an overwhelming amount of data that needs to be harnessed effectively to gain a competitive edge. ETL tools are crucial in solving this challenge by automating and simplifying data integration tasks, reducing manual intervention, and ensuring data quality and consistency. In this article, we delve into the world of ETL tools designed to enhance your experience with Google BigQuery, a popular and powerful analytics platform.
Among various noteworthy BigQuery ETL tools, Skyvia stands out as a superior choice. It offers advanced data integration features, a user-friendly interface, a wide range of available connectors, and a generous free plan for beginners to explore.

FAQ for BigQuery ETL Tools

How to Transfer Data from BigQuery?
There are different ways of transferring data from BigQuery, starting from API integrations to ETL tools. If you decide to use Skyvia, setting up the data integration scenario will take several minutes. Select the data integration tool, set BigQuery as a source, set the required destination, apply the transformation on data if needed, set scheduling for automated data loading, and run the integration.
What Data Can Be Extracted from BigQuery?
BigQuery supports semi-structured data (XML, JSON, and Avro files) and structured data organized in tables with definite data types. It also supports geospatial, time-series, and machine-learning data. Data that can be extracted from BigQuery also largely depends on the destination app and its supported data types.
What Is the Difference between ETL and ELT?
Both ETL and ELT aim to extract and load data to the destination, though the transformation stage takes place at different periods of time. With ETL, data is transformed before being transferred to the destination. With ELT, data is transformed on the destination side. Here are some other key differences between ETL and ELT.
| ELT | ETL |
|---|---|
| ELT is mostly used for loading data into a cloud data warehouse or a data lake. | ETL doesn’t impose limitations on the destination – data can be loaded into any supported source. |
| ELT works with structured, semi-structured, and unstructured data. | ETL supports structured data. |
| Transformations on the destination side usually require programming skills. | Transformations are made after data extraction and before its loading to the destination. |
