

Every day, the world generates enough data to fill every iPhone on the planet twice. And most of it is stuck in silos – a limbo for data, including CRMs, ad platforms, spreadsheets, and more.
That’s where ETL tools step in. They collect your data from everywhere, clean it up, and prepare it for action. In this guide, we’re breaking it all down –
- What does ETL really mean today?
- Why has it become mission-critical?
- And how to choose the right tool for your stack from a curated list of 25+ contenders.
You’ll also get a side-by-side comparison table and a quick “build vs. buy” decision playbook. So, let’s turn your data swamp into something you can swim in – or better yet, sail.
Table of contents
- What Are ETL Tools?
- ETL in 3 steps
- Benefits of a Dedicated ETL Tool
- ETL vs ELT
- Different Types of ETL Tools
- List of Best ETL Tools in 2026
- Top ETL Tools at a Glance
- How to Choose the Right ETL Tool: A Buyer’s Guide
- Conclusion
What Are ETL Tools?
ETL (Extract, Transform, Load) tools pull information from scattered sources (databases, APIs, files living in weird places), transform the mess into structure, then deliver it to warehouses (DWH) or databases ready for analysis.
Using these tools, teams can avoid manual CSV struggles and custom scripts that mysteriously break. ETL tools run reliably without constant attention, monitoring data flows, catching errors before they cascade, testing integrity, and compensating when source systems experience problems.
ETL in 3 steps
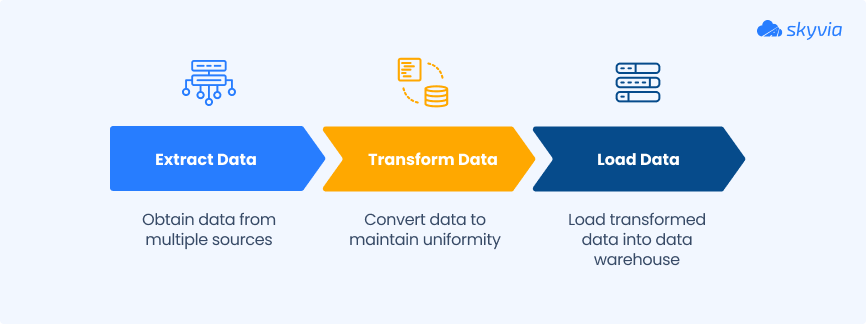
Step 1: Extract
Imagine a journalist collecting interviews, facts, and figures from various sources, literally everywhere they can reach for useful insights.
ETL tools do the same, automatically gathering data from wherever it lives, whether it is structured or unstructured.
Step 2: Transform
Next, just as an editor digs into messy drafts, fixes what’s broken, and shapes everything until it flows, ETL does refinement for data in much the same way. Raw information arrives full of duplicates, gaps, and formats that don’t play nice together.
Transformations clean the house: deduplication tosses the copies, joins related pieces together, while splits break apart what doesn’t belong, and summarization collapses mountains of detail into something your brain can process.
Step 3: Load
Finally, the finished article is getting published in a newspaper or online. In the data world, this means loading the prepared data into a DWH or business intelligence system, where it’s ready to drive decisions, fuel reports, or power machine learning models.
It can be loaded either all at once, which is commonly referred to as a full load, or at regular intervals, i.e., an incremental load.
Example: An e-commerce company handles different tools to stay effective. Manual consolidation will mean endless hours of matching records across systems that weren’t built to cooperate – the exact definition of work that shouldn’t exist anymore.
Skyvia allows them to synchronize Zoho CRM and Shopify to kill discrepancies, maintain data consistency across systems, and efficiently process large volumes during peak hours. That approach removes delays and ensures smooth operations that handle high transaction volumes without interruptions.

Benefits of a Dedicated ETL Tool
Data floods arrive from applications, hardware sensors, mysterious spreadsheets, etc. It happens simultaneously and relentlessly. The knee-jerk reaction is writing scripts and crossing fingers. It may be functional until your data triples, something breaks on weekends, or compliance officers request lineage documentation that doesn’t exist.
Purpose-built ETL tools solve this: extracting from any source, transforming methodically, and loading dependably without requiring someone on-call perpetually. Here’s why teams replace homegrown attempts:
- Automation and time saving
ETL tools run the repetitive jobs for you, pulling data, cleaning it, loading it, and doing it again tomorrow without a reminder: less manual drudgery, more time for actual thinking.
- Improved data quality and reliability
No more mystery nulls or mismatched field types. ETL platforms validate, clean, and standardize your data before it ever touches a dashboard, so your insights don’t come with asterisks.
- Scalability for growing data volumes
Whether today’s load is 10,000 rows or 10 million, ETL tools flex with the flow, especially cloud systems that scale without you hunting for more hardware.
- Better security and governance
Audit logs, lineage tracking, and access controls, all the things that keep compliance teams calm and guarantee no one asks, “Where did this number come from?” during a board meeting.
- Faster time to actionable insights
Instead of waiting days for someone to clean up a CSV, data is already transformed, validated, and dashboard-ready, which means decisions happen faster and with fewer “let me double-check that.”
ETL vs ELT
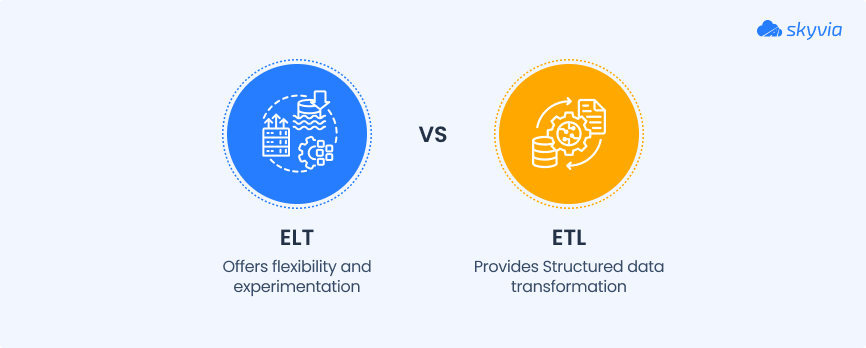
- ETL processes data before it lands anywhere.
- ELT dumps it into storage first, then transforms it.
That sequencing shift isn’t cosmetic – it changes architecture, tooling, and what each approach handles well. Organizations rarely go all-in on one method. They mix and match, running ETL for certain datasets and ELT for others as circumstances dictate. The ability to toggle between them turns out to matter quite a bit. Only imagine adapting one more tool when you sporadically need to shift the L and T sequence.
- Choose ETL if you need to apply complex transformations, clean and validate insights before loading them into your destination, or if your storage system can’t handle heavy processing tasks. It’s perfect for smaller datasets or when working with legacy systems.
- Choose ELT if you’re dealing with large volumes of information, cloud-based systems, or need faster loading with transformations happening after the data is loaded. ELT is often more scalable and efficient for modern insights environments.
ELT (Extract-Load-Transform)
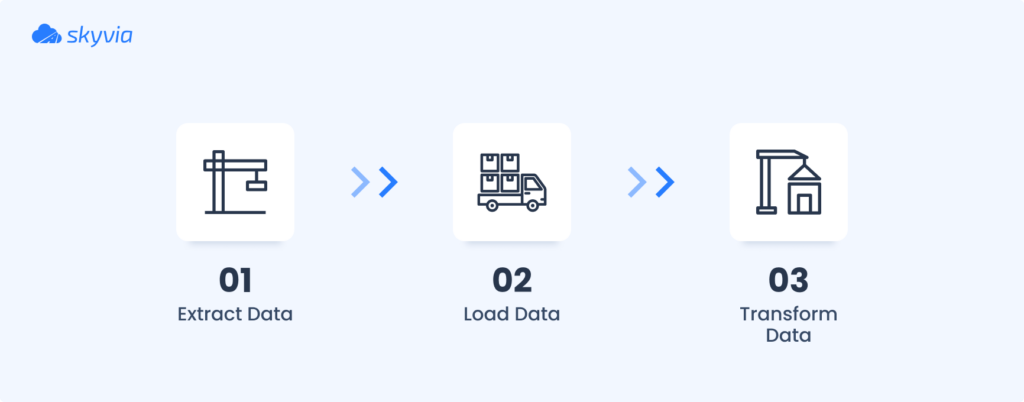
Data is extracted from the source system and loaded directly into the target system (typically a warehouse) without prior transformation.
Once it’s loaded, transformations are applied within the DWH. This method allows users to store raw, untransformed information in the DWH, which is more flexible for experiments with different transformation strategies as needed.
Pros
- Since data is loaded directly into the DWH before transformation, the loading process is typically faster, making it ideal for large datasets.
- Storing raw information gives you the flexibility to apply different transformation strategies as you go, enabling more dynamic and ad-hoc transformations.
- ELT is well-suited for cloud-based data warehouses and is designed to handle large-scale transformations efficiently.
- By separating the extraction and loading processes from the transformation, automation becomes easier. You don’t need to worry about transforming insights in real-time.
- With modern cloud DWHs offering scalable compute resources, ELT can be more cost-effective for businesses with high volumes of data.
Cons
- Raw data is a storage hog. Your warehouse capacity needs to balloon, and so will the bill attached to it.
- Untransformed data is basically a privacy incident waiting to happen, especially in industries where regulators don’t mess around with compliance violations.
- Loading runs quickly, but then transformations might bottleneck everything downstream, killing performance when dashboards need answers now.
- Managing and cleaning raw data becomes messier when the transformation logic is complicated or applied inconsistently across different pipelines.
- Heavy transformations demand serious compute power, whether you’re running cloud warehouses or on-prem systems, pushing operational costs higher than anticipated.
Different Types of ETL Tools
There are various ETL solutions available on the market, and they can be categorized based on their usage and cost.
Among the different types of ETL systems are the following:
Cloud-based ETL tools
They are like rideshare apps: you don’t need to own a car or worry about maintenance. Press a button and boom – your data gets its own chauffeur. Skyvia, Fivetran, or Stitch are the drivers who know the city, adjust when routes get clogged, and have standing accounts with every (or almost every) cloud service in town, so you’re never fumbling for credentials.
Example:
An online retailer runs Skyvia to grab customer clicks and purchases, twist them into analysis-ready shape, and land everything in a cloud warehouse while the team’s doing literally anything else.
Oh, wait, traffic doubles because of flash sale chaos? The pipeline stretches to handle it, in the same way rideshare platforms magically find more cars when half the city decides to go out at once.
Open-source ETL tools
Think of them as a community bike workshop. You get the basic tools and blueprints for free and can customize your bike (data pipeline) however you like. You might spend three hours hunting for the right sprocket, but what you roll out on is unmistakably yours. Talend Open Studio and Pentaho Data Integration capture that energy.
Example:
A startup grabs Talend Open Studio to siphon sales data off its e-commerce platform, twist it into shapes its accounting software understands, then drop it into a cloud database.
As the business morphs and new systems crop up, they just bolt on custom connectors – the same way you’d swap out bike gears when your daily commute suddenly includes a mountain.
Enterprise software tools
Imagine a train so long you can’t see both ends, hauling containers across time zones. That’s the league Informatica PowerCenter and Oracle Data Integrator play in – industrial-strength platforms for massive organizations moving data by the truckload (or trainload) between sprawling, tangled systems. They’re overpowered on purpose, fast, and loaded with enterprise features because quarterly reports depend on pipelines firing flawlessly.
Example:
A global bank uses Informatica PowerCenter to integrate customer transactions from dozens of countries.
The tool’s parallel processing and automated failure detection ensure that even if one “car” (data source) has an issue, the rest of the train continues to move, and issues are flagged for quick repair.
Reverse-ETL tools
Reverse ETL sends warehouse data back into circulation, pushing it out to CRMs, marketing automation, customer support tools – anywhere your business teams are trying to get work done. It’s the inverse of standard ETL, where data flows toward the warehouse and parks there.
Tools like Hightouch, Census, Polytomic, Rudderstack, and Grouparoo do the heavy lifting: yank clean data from the warehouse, morph it to fit whatever weird API spec your operational system demands, shove it into places where it becomes actions instead of rotting in tables nobody outside the data team touches.
Example:
Imagine a marketing team identifying high-value customer segments in their data warehouse. With reverse ETL, these segments are automatically synced to their email marketing platform.
When a customer makes a new purchase, the warehouse updates, and the marketing system instantly stops sending them retargeting ads.
Real-Time ETL tools
These are like an airport’s air traffic control tower. Tools like Skyvia, Integrate.io, SAP Data Services, and Rivery monitor, process, and direct streams of incoming and outgoing flights (data) in real time. Unlike batch ETL, which processes data in scheduled intervals, real-time ETL handles data the moment it “takes off” or “lands,” ensuring immediate visibility and action.
This approach is crucial for scenarios where delays could result in missed opportunities or increased risks, such as fraud detection, stock trading, or real-time customer analytics.
Example:
Imagine an e-commerce giant when their biggest promo goes live and the internet collectively loses it. Orders pile up, carts fill and empty, and support requests multiply faster than anyone can answer them. Real-time ETL grabs every transaction, every click, every payment attempt as it’s happening across web storefronts, mobile apps, checkout systems.
That firehose of chaos becomes clarity instantly: warehouses watch inventory drain in real time and adjust, fraud systems flag suspicious patterns before bad actors finish typing their credit card numbers, support agents see order status evolving live instead of telling customers “our system’s delayed, check back later.”
Custom ETL tools
Some organizations build ETL solutions to meet their exact needs. These are often scripts or in-house platforms, perfect for unique requirements or when off-the-shelf tools just won’t do.
Example:
A logistics company with legacy systems writes custom Python scripts to extract shipment data, transform it for modern analytics, and load it into a new dashboard. This approach gives them complete control but requires skilled developers to maintain and upgrade as new needs arise.
List of Best ETL Tools in 2026
The market is full of options, which makes the tyranny of choice paralyzing. On this list, you will get a detailed deconstruction of every tool, all the features, best use cases, and all the pros and cons that lie under the surface.
We hope your mug with coffee is deep enough, so let’s start.
Top No-Code & Low-Code Tools
When you’re too busy with all the other tasks related to your data, low-code ETL tools are a very promising solution.
They don’t put too much pressure on you with all those SQL commands; instead, they have a few buttons and a visual interface that can make things a bit easier for both the analytic team and business users.
Skyvia

G2 / Capterra Rating
- G2 – 4.8/5 based on 270 reviews.
- Capterra – 4.8/5 based on 106 reviews.
Best for
- When the plan is to consolidate various sources into a central warehouse, that becomes the foundation for all your analytics and BI work.
- When you’re responsible for various cloud applications and need pipelines, backups, and integrations to work smoothly, but don’t have resources for custom development.
- Teams handling reverse ETL to push warehouse data back into CRMs, marketing platforms, and ERP systems.
- Companies need more than just data movement. ETL, backups, and API creation in one platform beats coordinating three separate tools.
- If limited engineering support is your constraint, and moderate data volumes are your reality. Something that works simply often beats something that works perfectly.
Brief Description
Skyvia is a versatile cloud-based SaaS (Software as a Service) platform that offers integration, replication, synchronization, cloud backup, data flow, and control flow (the last two for advanced data workflows) solutions without requiring specialist knowledge or complex setup.
It supports over 200 connectors, making it easy to integrate data from various cloud applications, databases, file storage services, and cloud DWHs.
Key Features
- Automated synchronization, migration, and replication ensure your data flows continue uninterrupted with minimal setup and supervision.
- Change Data Capture (CDC) syncs transactional data by catching updates as they happen.
- Data gets filtered, mapped, and transformed during transit. Analytics receive consistent, reliable inputs rather than compatibility puzzles.
- The platform combines industry-compliant security with cloud flexibility. Your data stays protected without creating bottlenecks.
- REST API creation, custom query support, and real-time access provide the tools to build integrations that truly fit your workflow.
- MCP (Model Context Protocol) Server allows AI tools like chatbots and large language models to discover, query, and perform actions on business data using natural language without API or schema management by users.
Pricing
Skyvia offers several flexible pricing plans tailored to your specific features and usage requirements.
A free plan with limited features and usage makes it ideal for small projects or testing purposes. Paid plans start from $79/month and scale depending on the number of integrations, data volume, and advanced features required (e.g., API access, custom connectors, etc.).

Strengths & Limitations
Pros:
- Free trials and plans are available to test features before committing.
- A no-code, intuitive interface and easy setup simplify complex tasks like data transformations and queries for both technical and non-technical users.
- Scheduled package runs and automatic monitoring for smooth, continuous operations.
- Failure alerts and detailed logs ensure users stay on top of their integrations and troubleshoot issues quickly.
Cons:
- Limited functionality on the free plan, with some features and connectors restricted.
- Might not be suitable for highly complex custom integrations or very specific data processing requirements.
- Not enough video tutorials.
Fivetran

G2 / Capterra Rating
- G2 – 4.2/5 based on 445 reviews.
- Capterra – 4.4/5 based on 25 reviews.
Best for
- Mid-market and enterprise teams (500+) where data sources have multiplied faster than the ability to connect them manually. Startups can start small, but costs climb with volume.
- Data engineers and analysts who’d rather focus on insights than on keeping pipelines alive.
- Companies that lose money or opportunities when data lags.
Brief Description
Fivetran is designed for seamless data extraction, transformation, and loading with minimal setup and ongoing maintenance. It’s particularly known for its ability to handle high-volume, high-frequency data transfers.
Key Features
- Extracts from 700+ sources and loads into your warehouse with minimal setup. It just runs reliably after that.
- CDC keeps transactional data synced efficiently. Current insights without constant manual syncing.
- When automation handles the pipeline work, analytics teams can concentrate on tracking marketing, analyzing sales, and reporting on operations.
Pricing
Fivetran offers custom pricing, with costs based on the volume of data and connectors in use. The base plan starts at $1,000/month and can increase depending on the data usage and specific needs. For detailed pricing, contact Fivetran directly for a personalized quote.
Strengths & Limitations
Pros:
- Automatic schema migrations and incremental data loading ensure up-to-date data.
- Only minimal maintenance is required. Fivetran takes care of data pipeline management.
- Fast setup with no code needed, making it ideal for non-technical users.
- Scalable and can handle high-frequency data transfers for large datasets.
Cons:
- It is expensive compared to some other ETL tools, especially at scale.
- Limited transformation capabilities compared to more advanced ETL tools.
- Data source restrictions: not all platforms are supported.
- It can be difficult to troubleshoot in case of issues with data sync.
Stitch

G2 / Capterra Rating
- G2 – 4.4/5 based on 68 reviews.
- Capterra – 4.3/5 based on 4 reviews.
Best for
- Data and analytics engineers who need extensible pipelines and custom integrations. Business users expecting no-code interfaces and built-in transformations should skip this one.
- When transformation lives elsewhere, the tool handles reliable ingestion with incremental updates and automated schemas.
- The pay-as-you-go approach appeals to teams wanting solid integration without betting the budget.
Brief Description
Stitch is a cloud-based ETL service that simplifies data integration and transfer between various data sources and destinations. It’s easy to use and provides pre-built connectors for over 130 platforms, making it easy to extract, transform, and load data with minimal configuration.
Stitch offers automated, reliable data pipelines with built-in scheduling, allowing businesses to focus on analytics while it shoulders the burden.
Key Features
- Stitch lives, breathes, and scales in cloud environments.
- CDC acts as a smart gatekeeper, syncing only the records that have actually shifted, no wasted motion.
- Instead of cramming transformation into every stage, Stitch extracts and lands your data first. It’s like downloading files before editing them, less friction, faster results.
- The Import API serves as your escape hatch for custom or niche data feeds, letting you bring in real-time streams or scheduled batches when standard connectors fall short.
Pricing
Stitch offers a free plan with basic functionality for small datasets. Paid plans start at $100/month and increase depending on the data processed and the number of connectors used.
Pricing is based on the number of rows synced per month, and additional features, such as advanced connectors or support, are available with higher-tier plans.
Strengths & Limitations
Pros:
- 140+ pre-built connectors, simplifying integration with a wide range of platforms.
- Automated scheduling of data pipelines reduces the manual work for data engineers.
- A scalable solution for both small businesses and larger enterprises with growing data requirements.
- An easy-to-use interface with a straightforward setup process and minimal technical requirements.
- Real-time data replication for most sources, ensuring up-to-date data in DWHs.
Cons:
- Limited transformation capabilities compared to some other ETL platforms.
- Stitch is cloud-based only, which may not be suitable for some organizations.
- It can get expensive as the data volume grows or when using premium connectors.
- Basic error handling is available, but some users report limited troubleshooting options when data fails to sync.
Integrate.io

G2 / Capterra Rating
- G2 – 4.3/5 based on 208 reviews.
- Capterra – 4.6/5 based on 17 reviews.
Best for
- Mid-sized to large enterprises and rapidly growing companies where “muscular” data integration isn’t optional.
- Organizations that push through digital transformation and demand real-time or near-real-time replication.
- Data engineers, analytics pros, and integration experts who build automated, high-performance pipelines.
- Teams managing operational or reverse ETL to sync data back into CRMs, marketing platforms, and ERP systems.
Brief Description
Integrate.io is a cloud-based ETL system that supports a wide range of integrations, from cloud sources, SaaS apps, and databases to DWHs, making it a versatile choice for businesses looking to streamline their data workflows. It also provides real-time data processing and automated scheduling, enabling companies to ensure their data is always up-to-date for analytics.
Key Features
- 150+ connectors out of the gate that link to SaaS tools, cloud platforms, files, databases, and REST APIs.
- Rapid incremental replication delivers near real-time freshness through rapid syncing.
- Low-code drag-and-drop interface means less typing, more building.
Pricing
Custom pricing is based on the size of the data and the specific features required. It typically starts from around $99/month for small to medium businesses and increases based on the number of data sources, destinations, and advanced features like real-time processing.
Strengths & Limitations
Pros:
- It is easy for non-technical users to build and manage data pipelines.
- Scalable for businesses of all sizes, with support for real-time data processing.
- Automated scheduling of ETL processes reduces manual intervention and improves efficiency.
Cons:
- It can become expensive at scale, especially with high data volumes or large numbers of integrations.
- Limited transformation options for complex data manipulations compared to more advanced tools.
- It may require additional configuration for specific connectors, particularly for non-standard data sources.
- It is not as flexible as some open-source alternatives regarding custom integrations.
Hevo Data

G2 / Capterra Rating
- G2 – 4.4/5 based on 270 reviews.
- Capterra – 4.7/5 based on 109 reviews.
Best for
- Companies operating in real-time, or close enough, where stale data kills momentum and slows everything down.
- Teams that are tired of writing code and want workflows running on autopilot without constant tweaking.
- Organizations powering analytics and dashboards that need data flowing fast, with minimal lag gumming up the works.
- Anyone after a solution that gets out of the way once it’s set up, staying reliable without eating engineering time every week.
Brief Description
Hevo Data operates in the cloud without asking you to code, automating the entire process of moving data across sources and destinations. It tackles both real-time streams and batch loads, while keeping data moving fast.
Key Features
- 150+ connectors plug into major platforms, providing wide coverage that handles most integration scenarios out of the gate.
- CDC-driven replication powers both real-time and batch syncing, delivering updates almost instantly so data doesn’t sit around getting stale.
- Transformations happen post-load, giving you room to process and refine data after it lands, with flexibility that adapts to how users work.
- Managed SaaS with auto-scaling means infrastructure adjusts itself as data grows, so you’re not constantly tweaking capacity.
- Error handling and schema evolution are baked in, catching problems before they cascade and rolling with schema changes without breaking everything.
Pricing
Hevo offers a free plan, limited to 1 million events (updates, inserts, and deletes). Paid plans with more features and fewer restrictions start at $239 per month.
Strengths & Limitations
Pros:
- Non-technical users can jump in because pipeline building doesn’t require engineering expertise or coding knowledge.
- Real-time streaming combined with CDC keeps data moving fast, delivering near-instant updates when freshness matters most.
- Fewer maintenance headaches and less time spent on operational upkeep with managed infrastructure that scales itself.
- Flexibility around transformations fits different workflow styles.
Cons:
- Costs can scale up with high data volumes or lots of connectors in play, making it pricey for larger operations.
- Customization feels constrained next to open-source alternatives or fully custom solutions.
- Power users might bump into feature restrictions that feel limiting compared to building ETL pipelines manually with complete control.
Rivery

G2 / Capterra Rating
- G2 – 4.7/5 based on 120 reviews.
- Capterra – 5/5 based on 12 reviews.
Best for
- Companies that are ready to trade in that clunky data setup for something cloud-native.
- Pushing around datasets that demand automated ELT and CDC that can pull their weight.
- Use cases that involve bulk data transfers, batch jobs, or real-time syncing to keep analytics current.
Brief Description
Rivery is a cloud-native platform that grabs data from APIs, databases, and SaaS applications, works its transformation magic, and delivers everything to your cloud data warehouses or lakes like a well-trained retriever. With an arsenal of 200+ native connectors and AI support, it turns custom script reality into something both your technical team and business users can build sturdy pipelines without coding themselves into a corner.
Key Features
- Full-stack data movement, whether you need ELT, ETL, batch jobs, streaming, or CDC for those “I need it now” moments.
- Users can roll their own connectors via REST API, complete with authentication guards, rate limiting, and pagination that works.
- Cloud-native infrastructure built to scale harder than your dataset growth, no matter how aggressive it gets.
- Plays well with BI tools and keeps your data governance game tight without the headaches.
- Transformation capabilities that handle most scenarios, though the wild stuff might need backup dancers.
Pricing
Rivery charges via RPUs (Rivery Pricing Units) based on what you’re actually using. The starter tier is roughly $0.75 per RPU. Professional bumps to about $1.20 per RPU, while Enterprise goes custom through sales.
Strengths & Limitations
Pros:
- Supports every processing paradigm you’ve heard of – ELT, ETL, batch, streaming, CDC.
- Data engineers can dive deep, business users can stay in the shallow end, everyone’s happy.
- Lives in the Boomi ecosystem, inheriting all those enterprise features and AI capabilities without the integration struggles.
- Orchestration runs itself; minimal hand-holding required.
Cons:
- Despite no-code ETL interfaces, initial setup and complex pipeline configurations may require significant technical expertise.
- Real-time data syncing can hit speed bumps, which is a problem when your reporting needs to be actually real-time.
- Transformation capabilities work for the straightforward stuff, but need backup for anything truly complex.
- No on-premises or private cloud deployment options.
- Especially for API-based connectors, schema changes are not always well handled, creating maintenance overhead.
Matillion

G2 / Capterra Rating
- G2 – 4.4/5 based on 81 reviews.
- Capterra – 4.3/5 based on 111 reviews.
Best for
- Enterprises that run big analytics operations on cloud warehouses.
- Teams that like keeping things visual with drag-and-drop but sometimes need to dive into Python, SQL, or Bash scripting for the tricky bits.
- Organizations that push transformations down to the warehouse level.
- Data engineers and analysts who manage workflows that stretch across multiple pipelines and environments.
Brief Description
Matillion is low-code when you need speed, and complete code when you require power. The visual interface covers most data pipeline scenarios. Its cloud-native architecture scales naturally. Enterprise requirements, like version control, audit logs, job orchestration, and proper security, come standard instead of costing extra.
Key Features
- 150+ pre-built connectors for sources and cloud warehouses.
- Visual pipeline builder with high-code extensibility.
- Batch loads + CDC for up-to-date data.
- Built-in orchestration and scheduling for multi-step workflows.
- Secure by design: LDAP/Active Directory, SSL, granular access control.
- Version control and shared repos for team collaboration.
- Reverse ETL to send processed data back to business apps.
Pricing
Starts around $1,000/month, based on a credit model. Includes prepaid credits with additional billed pay-as-you-go. Free trial available. No free tier.
Strengths & Limitations
Pros:
- Complex transformation logic doesn’t force you into simplified workarounds.
- Enterprise security is already built in.
- Complex, multi-step pipelines spanning teams and time zones run reliably. Built to handle real organizational scale and complexity.
- The platform supports hybrid approaches naturally. You can start with low-code components when they fit, drop into high-code when they don’t.
Cons:
- Price tag lands in the enterprise bracket, which is not ideal for side projects or small ops teams.
- The learning curve might feel steep if your team’s used to drag-and-drop-only tools.
- Real-time streaming and super-low-latency use cases aren’t its strongest suit.
- Complex pipelines can burn through credits quickly without careful workload planning.
- On-prem databases require extra configuration and don’t perform as smoothly as cloud connectors.
Leading Enterprise Platforms
Large organizations face numerous challenges when it comes to handling data, and finding a tool that can scale up, even if it’s already operating on an industrial scale, is one of them. Here are some reliable options:
Microsoft SQL Server Integration Services (SSIS)
 home page")
G2 / Capterra Rating
- G2 – 4.4/5 based on 2250 reviews.
- Capterra – 4.6/5 based on 1963 reviews.
Best for
- Organizations that are already married to Microsoft – SQL Server, Azure, the whole family.
- Enterprises that want to shove mountains of data between databases, warehouses, and analytics platforms without losing their minds.
- Teams running the same data workflows on repeat – migrations, audits, compliance stuff that never ends.
- Data engineers who love getting into the weeds with error handling, dependency chains, and trigger logic.
- Hybrid setups where on-prem SQL databases and Azure cloud services need to play nice together.
Brief Description
If your data infrastructure runs on Microsoft, SSIS is the dependable workhorse pulling the load behind the scenes. It’s part of the SQL Server suite and brings a visual drag-and-drop studio for building ETL workflows.
With SQL Server Data Tools (SSDT), developers can design everything from basic imports to complex transformations, automate scheduling, and even hook workflows into Azure Data Factory for hybrid cloud orchestration.
Key Features
- Visual ETL designer through SSDT with drag-and-drop components and templates that save time.
- Incremental loads and CDC support so you’re not reprocessing everything from scratch every single time.
- Parallel and distributed execution that speeds things up when data volumes get serious.
- Error handling, event triggers, and conditional logic that give you real control over what happens when things go sideways.
- Logging, auditing, and performance tuning are built right in instead of bolted on as an afterthought.
Pricing
How much SSIS costs depends entirely on where it lives. Running it on Azure? You’re paying for Azure-SSIS Integration Runtime through Data Factory, with prices tied to VM configuration – A, D, or E series options with different cores, RAM, and storage typically run $600 to north of $1,200 per month per node. Azure Hybrid Benefit can knock that down if you qualify. Going on-prem? SSIS ships with SQL Server licensing, so you’re really just paying for SQL Server edition and core counts.
Strengths & Limitations
Pros:
- Microsoft ecosystem integration makes adoption frictionless for SQL Server-dominated enterprises.
- Visual development environment substantially reduces ETL pipeline development and debugging cycles.
- Performance scales well through native parallelism and intelligent memory utilization.
- Extensive community knowledge base, documentation library, and Microsoft enterprise support.
- Natural Azure integration simplifies hybrid deployment models and cloud transformation initiatives.
Cons:
- Licensing bills rack up fast once you’re buying enterprise cores or running hybrid deployments.
- Locked into Windows and Microsoft infrastructure.
- Fine-tuning packages and managing dependencies at scale requires real expertise, not just following tutorials.
- Streaming or real-time event handling isn’t in its DNA.
- Developer experience shows its age compared to cloud-native tools that started fresh this decade.
Informatica PowerCenter

G2 / Capterra Rating
- G2 – 4.4/5 based on 85 reviews.
- Capterra – n/a.
Best for
- Enterprises where vast volumes of data flow from messy sources into workflows that absolutely cannot break.
- Companies with mixed infrastructure: cloud platforms for modern apps, legacy systems still running core operations.
- Regulated industries with no wiggle room.
Brief Description
Informatica PowerCenter is the heavyweight of the ETL world – built for scale, packed with features, and battle-tested in environments where failure isn’t an option. It’s built around a visual workflow designer but backed by a mature engine that supports complex transformations, multi-node execution, and enterprise governance.
Key Features
- Drag-and-drop pipeline design plus reusable transformations and mappings.
- Built-in data quality, validation, and cleansing options.
- Enterprise-grade metadata management, lineage, and governance.
- Grid-based parallel processing for huge datasets.
- Role-based access, encryption support, and auditing baked in.
- Real-time data movement via PowerExchange extensions.
- Hybrid deployment across on-prem systems and cloud platforms.
Pricing
Informatica PowerCenter offers custom pricing based on the deployment size, number of users, and the required features. The pricing can be higher, making it more suitable for large enterprises with complex data integration needs. For detailed pricing, contact Informatica directly to receive a tailored quote for your business needs.
Strengths & Limitations
Pros:
- Advanced data transformation capabilities for sophisticated data processing and cleansing.
- Comprehensive monitoring and debugging tools to ensure smooth operations.
- Supports many data sources, including cloud, on-premise, and hybrid environments.
- Strong data governance features help ensure compliance with regulations.
Cons:
- It is expensive, particularly for small businesses or those with budget constraints.
- Requires specialized knowledge for setup, maintenance, and complex transformations.
- A complex user interface might be challenging for new users or non-technical teams.
- Performance can suffer when handling very large datasets without sufficient hardware.
Talend

G2 / Capterra Rating
- G2 – 4.4/5 based on 68 reviews.
- Capterra – n/a.
Best for
- Large organizations that want data integration, quality, governance, and delivery managed together instead of coordinating between disconnected tools.
- Teams using AI for data work, automating tedious tasks, predicting quality issues, and improving checks beyond static rule sets.
- Companies with sophisticated data architecture.
Brief Description
The Talend platform handles integration, transformation, API flows, quality management, and governance from a single platform. Now part of Qlik, the emphasis is on delivering compliant, real-time-ready data that’s been properly curated, not just shuttled between systems. It works equally well for straightforward cloud pipelines or complex hybrid architectures spanning multiple locations.
Key Features
- 1,000+ ready-to-use connectors.
- ETL and ELT workflow options are built through drag-and-drop visual design or custom coding.
- Data quality toolkit bundled in handles profiling, standardization, enrichment, and validation.
- AI-powered pipeline guidance and predictive analytics remove optimization guesswork.
- Metadata management plus lineage tracking alongside fully governed Master Data Management.
- Collaboration features and reusable components through Talend Studio and Cloud.
Pricing
Starting at roughly $4,800 per user annually, Talend’s base plans sound straightforward until you realize costs bend around several factors. Talend Cloud, Data Fabric, Stitch (their stripped-down cloud version), and Enterprise setups all price differently depending on how you deploy, what you’re building, and which features can solve your problems. However, a free trial is available to let you explore before committing to anything serious.
Strengths & Limitations
Pros:
- An all-in-one platform that covers not just ETL but APIs, quality, governance, and MDM.
- Hybrid flexibility: deploy entirely cloud, entirely on-prem, or mix and match.
- AI and ML help automate mappings, flag anomalies, and suggest transformations.
- Cooperates smoothly with modern data lakes and big data frameworks like Spark.
- Tight integration with Qlik enhances analytics, cataloging, and business access.
Cons:
- A wide feature scope means a steeper learning curve, which might not be ideal for quick DIY projects.
- Pricing climbs quickly if you need full governance or real-time bundles.
- Interface is powerful but not as immediately intuitive as newer low-code competitors.
- Running complex transformations at scale may require tuning and heavy infrastructure.
- Setup, administration, and orchestration usually need skilled IT or engineering resources.
Oracle Data Integrator (ODI)
 home page")
G2 / Capterra Rating
- G2 – 4/5 based on 19 reviews.
- Capterra – 4.4/5 based on 20 reviews.
Best for
- Enterprises that move massive datasets across mixed tech stacks: legacy databases, modern cloud apps, and everything in between.
- Teams that build large-scale data warehouses or lakes.
- Organizations in need of ELT-first architecture to offload processing to powerful target systems like Oracle DB, Snowflake, or Exadata.
- IT departments that are already entrenched in the Oracle ecosystem or managing SOA-based data services.
Brief Description
This integration tool supports ETL and ELT processes across various data sources. It provides an open, standards-based approach to integrate data from multiple databases, cloud applications, and other sources into Oracle databases and other platforms.
ODI offers high-performance transformations, real-time integration, and advanced data quality capabilities. Large enterprises widely use it for data migration, warehousing, and real-time analytics.
Key Features
- An ELT architecture that pushes transformation workloads to the target environment for maximum efficiency.
- Knowledge Modules (KMs) – reusable templates that automate mappings, integrations, and error handling.
- Real-time CDC for incremental data sync with minimal lag.
- Centralized web-based console for orchestrating workflows and monitoring performance.
- Built-in integration with Oracle SOA Suite to enable service-based data APIs.
Pricing
ODI offers custom pricing based on deployment size and business needs. The cost will typically include both licensing and support fees. For the most accurate pricing, it’s best to contact Oracle directly or visit their website to request a quote tailored to your organization’s needs.
Strengths & Limitations
Pros:
- High-performance ETL and ELT processing, especially with large datasets.
- Support for a wide range of data sources, including databases, cloud services, and big data platforms.
- Advanced data transformation capabilities that allow complex data manipulation.
- Comprehensive data quality features to ensure clean, reliable data.
Cons:
- Requires Oracle infrastructure, making it less suitable for non-Oracle environments.
- Complex setup and management typically require technical expertise and specialized knowledge.
- Higher cost compared to some open-source and cloud-based ETL tools.
- Limited community support compared to other, more widely adopted tools.
IBM InfoSphere DataStage

G2 / Capterra Rating
- G2 – 4/5 based on 70 reviews.
- Capterra – 4.5/5 based on 2 reviews.
Best for
- Enterprises running ETL/ELT at a serious scale and need parallel processing power that won’t buckle under pressure.
- Organizations that manage technology across generations: mainframes that predate the internet, on-prem databases, modern cloud platforms, and everything awkwardly bridging the gaps.
- Businesses that are already committed to IBM.
- Complex scenarios requiring hybrid or multi-cloud architectures that handle both batch processing and real-time data movement without one sabotaging the other.
Brief Description
IBM InfoSphere DataStage is the ETL tool built for terabytes moving across systems in parallel, transformations that need to track lineage, and hit SLAs without breaking governance rules.
Key Features
- Parallel processing engine spreads workloads across nodes for serious speed.
- Visual job designer makes complex workflows manageable.
- Deep connectivity spans the entire data landscape: databases, SaaS platforms, cloud services, flat files, etc.
- Metadata tracking follows lineage and schema changes across jobs, providing visibility that prevents mystery failures.
- Unified environment handles both batch and real-time processing.
- Enterprise orchestration through job monitoring and scheduling.
Pricing
DataStage pricing is pure enterprise territory – custom quotes only. Licensing comes as either perpetual or multi-year subscriptions bundled with the InfoSphere suite, depending on what makes sense for your procurement process.
Strengths & Limitations
Pros:
- Performance stays strong when data grows aggressively.
- Metadata-first architecture means compliance needs, audit trails, and governance controls that work naturally instead of feeling bolted on because regulations changed.
- QualityStage, Master Data Management, and governance platforms connect seamlessly when you’re already living in IBM’s data stack.
- Architecture supports scale-out MPP or scale-up SMP. Your infrastructure reality determines what makes sense, not platform limitations.
Cons:
- The learning curve is genuinely steep; this isn’t something business analysts pick up over lunch. You will need experienced ETL engineers on staff.
- It’s built for organizations where cost isn’t the primary concern.
- Deployment and tuning take real effort to get performance where it should be. Don’t expect to install it and have everything work optimally from day one.
- Documentation gets dense, and troubleshooting complex issues often requires reaching out to IBM support rather than solving it yourself quickly.
SAP Data Services

G2 / Capterra Rating
- G2 – 4.7/5 based on 10 reviews.
- Capterra – 4.6/5 based on 9 reviews.
Best for
- Companies that love and already use everything SAP.
- Organizations that need ETL with data cleansing and quality checks.
- When on-prem SAP handles core processes while cloud services manage analytics, CRM, and marketing, integration between both is critical.
- Teams where analytics and BI platforms depend on receiving standardized, trusted data that doesn’t require validation at every step.
Brief Description
IT is a data integration platform covering ETL, quality management, and governance within SAP’s ecosystem. It moves data but emphasizes ensuring that data is clean, standardized, and compliant before delivery to warehouses, SAP systems, or analytics tools. Most valuable for SAP-centric organizations needing tight integration and reliable data flows connecting SAP applications with broader business intelligence and analytics infrastructure.
Key Features
- Quality tools catch issues early: validation happens automatically, messy fields get scrubbed clean, incomplete records fill in gaps, and duplicates disappear before wreaking havoc downstream.
- Batch or real-time? Pick whichever fits the moment.
- Job scheduling and event triggers.
- Transformation rules stay put in a central repository, so teams stop accidentally inventing their own versions of the same logic and producing reports that never align.
- Disparate data gets parsed into structured formats instead of languishing as unreadable blobs your systems can’t touch.
Pricing
You’re looking at roughly $10 000 per year to get started with SAP Data Services base packages, but that number shifts as usage grows, data volumes increase, and connector needs expand. Enterprise licensing and cloud subscription options are on the table, though you’ll need to work through SAP’s sales team to access them. Maintenance and support costs hit annually as well, usually structured as a percentage of your licensing fees, adding another layer to the total cost of ownership beyond the initial package price.
Strengths & Limitations
Pros:
- SAP integration runs deeper here than anywhere else.
- ETL plus data quality in one platform cuts tool sprawl and strengthens governance.
- Works with structured databases and unstructured text equally well, which helps when workflows need to parse emails, server logs, or document content.
- Pipelines handle massive data volumes without performance degradation or unexpected failures disrupting operations.
- Centralized metadata and rule management keep transformation logic aligned across teams, preventing accidental inconsistencies that produce conflicting outputs.
Cons:
- Teams without SAP experience face a steeper learning curve than with more general-purpose integration platforms.
- Higher pricing puts it beyond reach for many mid-sized companies.
- SAP Data Services shows its age in flexibility for API-driven integrations.
- Hard to justify without SAP infrastructure. Paying premium prices for deep SAP integration doesn’t make sense when your systems don’t revolve around SAP products.
Qlik Replicate (formerly Attunity)

G2 / Capterra Rating
- G2 – 4.3/5 based on 110 reviews.
- Capterra – 5/5 based on 2 reviews.
Best for
- Enterprises syncing data in real-time across multi-cloud, on-premises, and hybrid environments.
- Data teams that are moving volumes so high, they make Black Friday traffic look tame.
- Companies that build lightning-fast CDC pipelines for analytics, operational dashboards, and keeping disaster recovery plans battle-ready.
- IT teams who believe life’s too short for hand-rolled replication code and unplanned outages.
Brief Description
Qlik Replicate functions as express shipping for enterprise data, getting information where it needs to go quickly and reliably, no coding involved. CDC technology powers synchronization, keeping source and target systems aligned in near real-time, which proves valuable for real-time analytics, cloud migrations, and replicating data across different platforms.
Key Features
- CDC-driven replication delivers real-time sync with lag times that won’t make you wait around.
- Works everywhere from vintage legacy systems to the latest cloud hotspots.
- Automated schema evolution rolls with the punches when your data models shift gears.
- Visual pipeline designer puts power in your hands.
- The transformation engine and smart filters ensure only the data that matters makes the cut.
- Distributed architecture scales out across multiple servers and parallel tasks, like cloning your best performer.
Pricing
Plan on shelling out around $1K monthly to get in the door with a basic setup, but think of that as the opening act, not the headliner. Your actual costs scale up as your data volume grows and you start plugging in more endpoints, kind of like how streaming subscriptions quietly multiply.
Strengths & Limitations
Pros:
- The unified web console serves up monitoring and alerting that keep you ahead of trouble.
- Zero-downtime upgrades mean your production environment keeps humming while you level up.
- It handles data volumes that would make other tools cry uncle, assuming you’ve tuned things properly.
- No need to worry about what comes after data structure changes, thanks to the automated schema.
Cons:
- Crank up the volume on an improperly sized system, and bottlenecks will appear like spoilers on opening weekend.
- The pricing can hit smaller teams like an unexpected plot twist.
- Multi-source merge replication doesn’t come pre-installed, so you’ll need to improvise.
- And if you’re dealing with niche or brand-new data sources, prepare for some DIY action with custom connectors and workarounds.
Best Cloud-Native Solutions
Going to the cloud can sometimes resolve many of your problems. It’s a great way to start from a clean slate, when there’s lots of data already piled up in every corner of your office servers. If you already live there, these tools will feel even more natural and graceful.
AWS Glue

G2 / Capterra Rating
- G2 – 4.3/5 based on 194 reviews.
- Capterra – 4.1/5 based on 10 reviews.
Best for
- Teams focused on serverless data pipelines.
- Data engineers who want auto-discovery and auto-scaling ETL.
- Organizations deeply embedded in AWS infrastructure (S3, Redshift, Athena, you know the cast).
- Companies that build out data lakes, warehouses, or lakehouse architectures in cloud environments discover a natural ally that fits their infrastructure goals.
- Use cases centered on batch processing, metadata management, or jobs that fire off based on specific events rather than constant streaming.
Brief Description
AWS Glue takes the grunt work out of data integration by doing what Amazon does best – hiding complexity. No servers to provision, no clusters to tune. Feed it your source data, tell it where things need to land, and walk away.
Key Features
- ETL scripts basically write themselves through schema detection and automatic cataloging.
- Spark execution happens serverless, meaning AWS does the job: spins things up when you need them, scales when traffic hits, tears down when the party’s over.
- Scheduling and dependencies are already handled, so you’re not playing Tetris with job timing or drawing dependency graphs that look like conspiracy theories.
- Code in Python or Scala, depending on what clicks for your team or what the situation calls for.
- CloudWatch consolidates your monitoring and metrics into one feed instead of making you check five different apps like some kind of digital nomad.
Pricing
Glue meters your usage down to the second using Data Processing Units – each DPU serves up approximately four vCPUs and 16 GB RAM for about $0.44/hour. Also, no free trial exists. Just remember: with incredible processing power comes great monthly statements.
Strengths & Limitations
Pros:
- Zero infrastructure management – just write jobs and run.
- Deep AWS integration keeps data gravity low and pipelines fast.
- Automatic data cataloging removes repetitive ETL plumbing.
- Scales up (or down) automatically with job demand.
- Flexible orchestration: cron jobs, triggers, events, API calls.
Cons:
- Cross-account integration still requires manual API intervention for certain configurations, undermining the fully-managed promise.
- AWS ecosystem dependency is absolute. Glue operates exclusively within Amazon’s infrastructure, making multi-cloud or hybrid deployments impractical.
- Niche connectors frequently require custom engineering effort.
- Logging access remains restricted: system driver logs unavailable, certain GlueContext operations constrained, job bookmark functionality limited.
- Table optimization tools face scaling boundaries: compaction features don’t extend reliably across accounts, regions, or all storage class and table type combinations.
Azure Data Factory

G2 / Capterra Rating
- G2 – 4.6/5 based on 86 reviews.
- Capterra – 4.4/5 based on 5 reviews.
Best for
- Enterprises that stitch together ETL/ELT pipelines across hybrid or cloud setups within the Azure ecosystem.
- Teams that juggle data sources from on-prem servers, SaaS platforms, and multiple clouds.
- Analysts who drag legacy data warehouses into the 21st century.
- Organizations that crave low-code simplicity that doesn’t box them into cookie-cutter solutions when custom pipelines call.
Brief Description
Azure Data Factory (ADF) is Microsoft’s go-to data wrangler for the cloud age. It lets you bring together data pipelines from all corners of your tech stack without lifting a finger to spin up infrastructure. ADF gives you drag-and-drop data flows when you want it simple, and code-first activity support when you need more control. It scales automatically, runs on demand, and plugs in neatly with Azure’s analytics tools like Synapse, Databricks, and Power BI.
Key Features
- 90+ pre-stocked connectors (databases, SaaS, files, cloud, on-premises).
- Visual drag-and-drop or code-based prep (Spark, .NET, Python, custom recipes welcome).
- Multiple modes: instant, scheduled, or chain-reaction style.
- Built-in “taste tester” for schema changes (won’t let format shifts ruin the integration).
- Secure delivery service for hybrid ingredients via self-hosted integration runtime.
- Smart timer with alerts and automatic recovery if something burns.
Pricing
Pricing is consumption-based: you pay for what you run – pipeline orchestrations, data movement, and Spark-based data flows all add to the bill. There’s a free tier for light usage, but once your jobs hit enterprise volume or frequency, expect costs tied to processed data, compute time, and pipeline run counts.
Strengths & Limitations
Pros:
- Azure integration is so seamless that it’s almost telepathic.
- Business users can build pipelines themselves without summoning the dev team.
- Auto-scales without you lifting a finger or losing sleep over servers.
- Handles even Frankenstein data setup – old servers, new clouds, random SaaS apps nobody remembers buying.
Cons:
- Built for batches, not instant gratification – real-time streaming needs you to tag in Event Hubs or Stream Analytics.
- Complex tasks might force you to roll up your sleeves and code anyway.
- Multi-step pipeline debugging is like untangling earbuds after they’ve been in your pocket for a week.
- Azure newbies will hit a learning curve that feels steeper than it should.
Estuary
G2 / Capterra Rating
G2 – 4.8/5 based on 26 reviews
Best for
- Teams that want one platform for CDC, streaming, and batch instead of juggling separate ETL, ELT, and streaming tools
- Companies that care about fresh data for analytics and AI, but still need cost control and predictable pricing
- Engineering and analytics teams that want low code setup plus deep configuration when needed
- Organizations that need flexible deployment options, including cloud, private deployment, and bring your own cloud
Brief Description
Estuary is a right time data platform that unifies CDC, streaming, batch, and ETL pipelines in a single system. Right time means you can choose when data moves, from sub second streaming to near real time to classic batch, without changing tools. Estuary captures events from databases, SaaS tools, and queues, keeps schemas in sync, and continuously lands data in warehouses, lakehouses, and operational systems for analytics, operations, and AI.
With more than 200 prebuilt connectors and Kafka API compatibility, teams can build pipelines in minutes, plug into existing ecosystems, and retire a lot of custom code and fragile jobs.
Key Features
- 200+ real time and batch connectors for databases, SaaS apps, warehouses, and event streams, with automated schema evolution and CDC support
- Right time engine that supports sub second streaming, scheduled syncs, and bulk loads in one platform
- Exactly once semantics for many destinations, with strong guarantees around ordering, idempotency, and recovery
- Kafka compatible API that lets teams consume collections as topics without operating Kafka clusters
- Flexible deployment models: fully managed cloud, private deployment, or bring your own cloud, so data can stay inside your network perimeter
- Built in transformations and SQL derivations for shaping data in flight
- Detailed observability, including task level metrics and logs, to keep pipelines predictable at scale
Pricing
Estuary uses simple, usage based pricing. Data movement is priced at 0.50 USD per GB, with a free tier that includes up to 10 GB of data per month so teams can build and validate pipelines before committing. Additional costs can include connector task hours and optional private or BYOC deployment fees for enterprises that need full network isolation and dedicated infrastructure.
Strengths & Limitations
Pros:
- Unified platform for CDC, streaming, and batch reduces tool sprawl and orchestration complexity
- Predictable, transparent pricing and a generous free tier make it easier to control TCO compared with many legacy ETL tools
- Strong customer support and Slack based collaboration are highlighted repeatedly in user reviews
- Flexible deployment options (cloud, private, BYOC) fit strict security and compliance requirements
- Real time performance that can replace slower batch oriented tools like traditional ETL or replication platforms
Cons:
- UI and configuration model have a learning curve for purely non technical users compared with the simplest no code tools
- Connector catalog is growing fast but still smaller than the largest, oldest incumbents in the ETL space
Google Cloud Dataflow

G2 / Capterra Rating
- G2 – 4.2/5 based on 44 reviews.
- Capterra – 4.3/5 based on 3 reviews.
Best for
- Teams that build real-time and batch pipelines and would prefer servers stay off their to-do list.
- Companies that are already living in GCP’s world for analytics, ML experiments, or event-driven stuff.
- Developers who are tired of maintaining separate codebases for streams versus batches (Apache Beam lovers, pull up a chair).
- The cases where auto-scaling, zero-touch infrastructure, and deep Google service connections aren’t optional extras.
Brief Description
Google Cloud Dataflow is what you’d get if batch and streaming ETL had a highly productive, no-maintenance child. It runs Apache Beam pipelines on fully managed infrastructure, auto-scales when traffic spikes, and plugs into BigQuery, Pub/Sub, and the rest of Google’s data family without any messy configurations. All of that without spinning up clusters or patching anything – just write your logic and let Dataflow do its thing.
Key Features
- Both streaming and batch? Apache Beam SDK’s got you covered with one programming model.
- Serverless and auto-scaling – basically runs itself while you focus on actual work.
- Real-time dashboards let you peek under the hood with job visualizations, logs, and performance metrics.
- Windowing and triggers give you control over event-time processing that’s actually sophisticated.
- CMEK (Customer-Managed Encryption Keys) and IAM (Identity and Access Management) support.
- Pipeline health gets monitored automatically, with built-in optimizations fixing issues you didn’t even know existed.
Pricing
Pricing follows the “pay for what you burn” rule. You’re billed for the vCPU time, memory used, and data shuffled, and no upfront licensing drama. With committed-use discounts available, it can be cost-effective, but watch out: 24/7 streaming jobs will rack up the bill if you don’t tune for efficiency.
Strengths & Limitations
Pros:
- One tool tackles streaming and batch.
- Meshes perfectly with BigQuery for dashboards that pulse with real-time data or datasets primed for machine learning.
- Self-adjusting capacity means pipelines cruise along smoothly without hand-cranked scaling tweaks.
- Checkpoints and recovery mechanisms catch you when things stumble.
- The billing model cuts you slack when traffic ebbs and flows unpredictably.
Cons:
- Round-the-clock streaming can drain your budget. Also, beware data-heavy joins and groupings; they can trigger cost spikes that sneak up on you.
- Apache Beam throws you into the deep end – there’s no shallow entry point.
- Hunting down issues with late data or dodgy pipeline stages demands some black-belt-level troubleshooting.
- Stepping outside Google’s playground? Good luck – the fence is pretty high.
Google Cloud Data Fusion

G2 / Capterra Rating
- G2 – 5/5 based on 2 reviews.
- Capterra – n/a.
Best for
- Teams that are tired of hand-coding every data pipeline and ready to drag-and-drop their way to ETL bliss.
- Organizations that build data lakes or warehouses in BigQuery and want pipelines that plug right in.
- Hybrid data scenarios blending on-prem, SaaS, and GCP-native sources.
- Real-time and batch data ingestion for things like fraud detection, recommendation engines, or IoT sensors.
Brief Description
Google Cloud Data Fusion is what you might call the “point-and-click” ETL platform for the Google Cloud universe. It pairs a visual designer with pre-built connectors to help teams stand up secure, cloud-scale data pipelines without digging into code unless they want to. Behind the curtain, it spins up managed Dataproc clusters (managed compute clusters running Spark, Hadoop, Flink, Presto, and similar frameworks) to handle the heavy lifting, so you’re never stuck maintaining a runaway Spark job.
Key Features
- Drag-and-drop visual pipeline builder (zero code required).
- 50+ native connectors including BigQuery, Cloud Storage, Pub/Sub, and more.
- ETL, ELT, batch, and streaming all under one roof.
- Real-time monitoring, logging, and alerting.
- Support for custom plugins, REST APIs, and Airflow integration.
- Multi-user workspace for collaborative development.
Pricing
Pricing is split into two meters: the Data Fusion instance itself and the compute resources it spins up under the hood. You can dip your toes in with the Developer edition at $0.35/hour (up to 2 pipelines), move to Basic at $1.80/hour (unlimited pipelines + 120 free hours/month), or go full enterprise at $4.20/hour with all the bells and whistles. Underlying Dataproc job costs apply, so mind those clusters when dealing with monster datasets.
Strengths & Limitations
Pros:
- Democratizes data engineering – analysts and SQL professionals can build pipelines without knowing Spark.
- Deeply integrated with Google Cloud, from storage to analytics to security.
- Flexible pricing tiers and free hours offer breathing room for smaller teams.
- Visual interface speeds up prototyping and shortens onboarding time.
- Serverless automation = no servers to patch, scale, or reboot.
- Plays well with Airflow, APIs, and custom code if you need more control.
- Solid for data lake modernization, cloud migration, and pipeline replatforming.
Cons:
- Not ideal if your use case demands heavy custom-coded transformations or exotic data logic.
- Pipeline steps within a sub-flow don’t parallelize, which can bog down high-complexity workflows.
- Error debugging sometimes feels like reading tea leaves in a Spark log.
- Dataproc costs can sneak up on teams processing huge datasets without tuning pipelines.
- Visual-first design trades off fine-grained control, especially compared to full-code frameworks like Beam or Spark.
dbt (Data Build Tool)
 home page")
G2 / Capterra Rating
- G2 – 4.7/5 based on 183 reviews.
- Capterra – 4.8/5 based on 4 reviews.
Best for
- Teams that live in the modern data stack and are ready to treat analytics like software.
- Data engineers and analysts who want to turn SQL into a first-class citizen in pipelines.
- Organizations that need to transform raw warehouse data into clean, trustworthy BI models.
- Fast-moving teams that need version control, CI/CD, and data testing baked into workflows.
Brief Description
In dbt, SQL meets software engineering, plain and simple. Your select statements get the Jinja (web template engine for the Python programming language) treatment for templating flexibility. You get pipelines that run production workloads directly inside Snowflake, BigQuery, Redshift, or Databricks. Dependencies flow through DAGs instead of being held together with high hopes of every team member and duct tape. Documentation appears on its own. And those data models you’re shipping? They come armed with tests and version control, ready to earn trust.
Key Features
- SQL-based data transformation using modular models.
- Directed Acyclic Graph (DAG) built automatically from model dependencies.
- Built-in testing for schema, data expectations, and freshness.
- Auto-generated docs + data lineage diagrams (yes, guilt-free documentation).
- Incremental models to avoid full table rebuilds.
- Git + CI/CD integration for proper versioning and deployments.
- Jinja templating & macros for reusable logic.
- Environment support: dev, staging, prod, or however you slice it.
- Hooks and extensibility for advanced workflows and scripts.
Pricing
There’s a free open-source version (dbt Core) for solo devs or small teams who want to run things from the command line. If you want more, dbt Starter steps in at $100 per month per user. Enterprise plans are quote-based and include SSO, audit logs, and other “grown-up table” perks.
Strengths & Limitations
Pros:
- Transforms SQL pipelines from “mysterious spaghetti” into reproducible, well-tested code.
- Makes data pipelines feel like software: version control, PRs, CI tests, the works.
- Auto-docs and lineage answer “where did this number come from?” without Slack archaeology.
- Promotes reusable logic, modularity, and clean warehouse environments.
- Plays well with ingestion/orchestration tools like Airbyte, Fivetran, Airflow, and Prefect.
- Scales from one analyst to 100-person data teams without losing composure.
Cons:
- Doesn’t handle ingestion or extraction on its own. You will need to pair it with something more.
- Requires SQL fluency (and a little Jinja), so it’s not a “click and forget” solution.
- Processing and performance depend entirely on your warehouse configurations (so, budget wisely).
- Doesn’t natively orchestrate external jobs (though you can pair it with Airflow, Dagster, or dbt Cloud jobs).
Powerful Open-Source & Developer Tools
Many companies skip this category entirely due to the belief that there’s no such thing as a free lunch. Sometimes, open-source tools, when backed with creativity and your own ability to adjust, can cover all of the data needs.
Airbyte

G2 / Capterra Rating
- G2 – 4.4/5 based on 67 reviews.
- Capterra – n/a.
Best for
- Teams that drown in SaaS apps and need one pipeline to rule them all.
- Hybrid or air-gapped deployments where “cloud-only” tools can’t legally enter the building.
- Data engineers who want full control over connectors, configs, and pipelines.
- Use cases involving CDC-powered syncs for fast-refresh dashboards or machine learning models.
Brief Description
Airbyte is an open-source integration platform that executes automated ELT pipelines, along with monitoring their logs. It focuses on providing a flexible and scalable solution, making it easy to integrate with a variety of cloud applications, databases, and DWHs. It also offers automatic schema migrations, ensuring that your data pipelines are always up-to-date without manual intervention.
Key Features
- Over 600 source and destination connectors.
- CDC for low-latency, incremental syncs
- Hybrid, self-hosted, air-gapped, and cloud SaaS deployment models.
- dbt integration for downstream transformations in-warehouse.
- API, UI, Terraform provider, and Python SDK for flexible orchestration.
- Enterprise security: SSO, RBAC, SOC2-aligned controls, encrypted secrets.
- Built-in monitoring and logging (hook into Datadog, Prometheus, etc.).
Pricing
Airbyte offers free open-source access and enterprise-level features with premium support and additional capabilities. It provides custom pricing based on organizations’ business requirements and usage for advanced features and dedicated support.
Strengths & Limitations
Pros:
- A wildly extensive connector library allows you to connect to almost anything.
- Freedom to deploy your way: cloud, Kubernetes, local VM, or on-prem.
- CDC support keeps your dashboards fresh without crushing your database.
- Easy to fork, tweak, or build your own connector without begging support.
- Strong user and partner ecosystem keeps improving connectors and docs.
- Zero lock-in with open-source licensing; you can bring your pipelines when you leave.
Cons:
- Self-hosting Airbyte means you’re also hosting its logs, scaling, and upgrades.
- Community-built connectors vary in polish; some assembly may be required.
- Transformation occurs downstream, so you’ll pair it with dbt or a similar tool.
- SaaS pricing scales with sync volume; it can climb fast without guardrails.
- Not a great fit if you’re looking for a fully unified ETL and transformation tool in one box.
Meltano

G2 / Capterra Rating
- G2 – 4.9/5 based on 7 reviews.
- Capterra – n/a.
Best for
- Data engineers who enjoy tinkering, extending, and building their stack around open standards, such as Singer and dbt.
- Hybrid setups that need both batch and real-time ELT without getting boxed into a SaaS platform.
- Organizations that are fed up with vendor lock-in and looking for full ownership of code, infrastructure, and workflows.
Brief Description
Meltano happens when data engineering crashes into DevOps territory. Pipelines become code-versioned, deployed, and treated like real software instead of fragile scripts living in someone’s local folder.
Key Features
- Plugin-based ELT architecture: extractors, loaders, transformers, and orchestration plugins.
- Built-in support for Singer taps/targets – hundreds of connectors, community-driven.
- dbt native for in-warehouse transformations (Jinja + SQL, no reinventing wheels).
- CLI-first experience + web UI for pipeline visibility and management.
- Integrates with Airflow, Prefect, Dagster, and more for serious orchestration.
- Full Git integration: version control your pipelines like application code.
- Supports both batch and streaming data workflows.
- Active open-source community shipping updates constantly.
Pricing
The core platform lives in the open-source world – completely free if you’re willing to host it yourself. Teams craving managed services or enterprise-grade hand-holding can hammer out custom commercial deals.
Strengths & Limitations
Pros:
- Zero license costs and no vendor lock-in; run it your way, forever.
- Treats pipelines like code: reusable, testable, deployable, reviewable.
- Hugely customizable thanks to the plugin architecture and open standards.
- Plays nice with modern stack favorites like dbt, Airflow, and BigQuery.
- Ideal for hybrid or regulated environments where hosted tools aren’t allowed.
- Strong community support and quick iteration on new connectors/features.
Cons:
- Not exactly “plug-and-play.” You’re expected to know your way around configuring files.
- More DevOps overhead than fully managed cloud tools (you own the infrastructure).
- Learning curve can be steep if you’re used to drag-and-drop ETL GUIs.
- Community-led connectors vary in maturity; some assembly may be required.
Singer

G2 / Capterra Rating
- G2 – n/a.
- Capterra – n/a.
Best for
- Data engineers who build modular ELT pipelines where swapping sources and destinations is a must.
- Teams that want reusable, open-source connectors instead of vendor-locked GUIs.
- Companies with niche or internal systems that require custom connector development.
- Modern data stacks to avoid overpaying for full-fledged platforms when all they need is rock-solid extract-and-load.
Brief Description
Singer is a Python-based open-source tool that allows data extraction from different sources and consolidation to multiple destinations. Instead of being a complete ETL tool itself, it focuses on offering standardized connectors called “Taps” (for extracting data) and “Targets” (for loading data).
Key Features
- Modular approach: one tap + one target = one clean data pipeline.
- JSON schema messaging for universal compatibility.
- 350+ community-built taps and targets, or build your own with simple SDKs.
- Works with any orchestrator (Airflow, Dagster, Cron, etc.).
- Active, evolving ecosystem thanks to community and open standards.
Pricing
Singer is completely free and open-source, with no licensing fees or subscription costs. However, if you require additional enterprise-level support or features, you may need to integrate it with other tools or services that come at a cost.
Strengths & Limitations
Pros:
- An affordable option for businesses due to its open-source nature.
- Modular design with reusable “Taps” and “Targets” for flexible data integration.
- Customizable connectors to create your own sources and targets as needed.
- Active community and extensive documentation for support.
- Supports a wide range of sources and destinations, making seamless integrations possible even for companies with niche data needs.
Cons:
- It requires development expertise, as it’s primarily designed for developers and data engineers.
- Limited built-in transformation capabilities; users need to build their own logic or integrate with other tools for transformations.
- It is not a fully managed solution, so it requires more effort in setup and maintenance compared to cloud-based ETL platforms.
- Lack of a native UI, as it’s a code-first platform, there’s no easy drag-and-drop interface for non-technical users.
Apache Airflow

G2 / Capterra Rating
- G2 – 4.4/5 based on 115 reviews.
- Capterra – 4.6/5 based on 11 reviews.
Best for
- Data engineering teams that hunt for one dashboard to rule them all.
- Companies that run complex ETL/ELT choreography across different cloud providers and database engines.
- Developers who live in code.
- ML teams that work with model training, scoring, and deployment on repeat and need reliable scheduling.
Brief Description
Apache Airflow makes certain that every step in your data workflow happens in the right sequence. Its library is borderline absurd.
Operators and plugins exist for databases, cloud platforms, APIs, machine learning tools; basically anything you’d want to talk to. Additionally, there are community-built connectors for tasks you may not have even known existed.
Key Features
- Workflows exist in Python, and DAGs shift dynamically when your code tells them to.
- Tasks get distributed across team members, scaling horizontally so pipelines keep pace with growing workloads.
- The web UI centralizes monitoring, log inspection, and debugging instead of scattering them across terminals.
- Scheduling adapts: failed tasks retry automatically, dependencies get respected, SLAs stay front and center.
- Every task leaves a trace in the metadata database, building audit trails and preserving state over time.
- Plays well with GCP, AWS, Azure, Databricks, and most other platforms you’d want to touch.
Pricing
Airflow is free and open-source, but running it isn’t costless: you’ll need to host it yourself or choose a managed version like Astronomer, Google Cloud Composer, or AWS Managed Workflows, each billed by resource usage and orchestration scale.
Strengths & Limitations
Pros:
- You can orchestrate database queries, container workloads, machine learning jobs, basically anything.
- Retry logic responds when things stumble, and alerts surface issues before they snowball out of control.
- Fits naturally alongside modern tools – dbt for transformations, Spark for processing, Kafka for streaming, etc.
Cons:
- Not a beginner-friendly option. You’ll need Python chops and infrastructure savvy.
- Setup and maintenance can be heavy without a managed version.
- UI is functional but less slick than newer SaaS alternatives.
- Metadata DB and scheduler tuning are needed for very large workloads.
- Primarily designed for batch orchestration, not native streaming pipelines.
Pentaho Data Integration (Kettle)

G2 / Capterra Rating
- G2 – 4.3/5 based on 17 reviews.
- Capterra – n/a.
Best for
- Data teams that want to design complex ETL pipelines visually.
- Enterprises in need of a battle-tested solution for both batch and near real-time data movement.
- Organizations that combine analytics and integration under one roof, from ingestion to dashboards.
- Teams that need deep data cleansing and transformation before feeding their BI layer.
- Companies that prefer the flexibility of open source with enterprise-grade support on demand.
Brief Description
Pentaho Data Integration – Kettle to anyone who’s used it more than once – brings visual simplicity to data chaos: drag, drop, connect, and suddenly you’ve got pipelines running without writing novel-length scripts. Things click especially well with the Pentaho Analytics suite. Integration and insights stop being divorced processes and become part of the same workflow.
Key Features
- Visual ETL designer uses drag-and-drop simplicity, with orchestration managing dependencies and workflows that repeat without rebuilding.
- Connectors span 100+ options: databases of every flavor, APIs, cloud storage providers, and big data platforms.
- Batch jobs and streaming pipelines both run here, so real-time data doesn’t force you onto a different stack.
- Transformations handle structured formats, such as JSON, XML, and CSV, as well as more complex unstructured data, right out of the gate.
- High-volume workloads get managed through parallelization, clustering, and partitioning instead of grinding to a halt.
- The plugin system lets you script custom logic or extend functionality when the out-of-the-box stuff isn’t enough.
Pricing
Community Edition doesn’t charge admission – open source all the way, ideal for smaller setups or trial runs. Other editions (Standard, Premium, and Enterprise) open doors to more features, but you will need to talk to sales to learn the numbers.
Strengths & Limitations
Pros:
- Visual interface that bridges the gap between engineers and analysts.
- Runs wherever you need it (on-prem, cloud, hybrid) without throwing a fit about deployment models.
- Pentaho analytics stack integration turns reporting pipelines into smooth operators instead of Rube Goldberg machines.
- Since it’s an open-source tool, you become a part of a massive community that’s actually helpful when you’re stuck.
Cons:
- GUI-based tools can feel sluggish or heavy for very large or deeply nested jobs.
- Requires careful tuning to hit peak performance on clustered setups.
- The learning curve can surprise new users because “drag-and-drop” doesn’t mean “instant mastery” here.
- Cloud-native capabilities lag behind newer SaaS-first ETL platforms.
- Some connectors and plugins may need manual setup or scripting for advanced scenarios.
Apache NiFi

G2 / Capterra Rating
- G2 – 4.2/5 based on 25 reviews.
- Capterra – 4/5 based on 3 reviews.
Best for
- Teams that have to handle continuous data floods from various sources and want immediate control over routing and transformations.
- Companies stuck making ancient on-prem systems, modern clouds, and edge infrastructure cooperate like they’re old friends.
- Finance, healthcare, and government organizations where compliance demands complete data lineage and won’t take “probably” for an answer.
- Data engineers who won’t compromise on scalability or governance.
- Distributed environments where data crosses networks or hops between data centers, and security can’t be an afterthought.
Brief Description
Apache NiFi is the air traffic controller of data movement that keeps hundreds of data “flights” moving safely between systems, transforming and routing them as needed. Born out of the NSA’s Niagarafiles project, it’s designed for secure, traceable, and flexible dataflow management.
Using its visual interface, teams can drag and drop processors that fetch, transform, and deliver data across complex infrastructures, all without writing a single line of code.
Key Features
- Visual canvas loaded with 300+ components that already know how to pull data in, mess with it, and send it out.
- It handles real-time streams and batch jobs without complaining.
- Every byte gets a travel diary through Data Provenance.
- The protocol buffet includes HTTP, FTP, Kafka, MQTT, HDFS, S3, and many more protocols that nobody remembers.
- High availability through clustering means your flows continue to run even when hardware issues occur.
Pricing
It’s completely open source and free, licensed under Apache 2.0. The real cost lies in the infrastructure required to host NiFi clusters and maintain uptime.
Strengths & Limitations
Pros:
- Intuitive, visual flow design makes complex data movement easy to map and manage.
- Complete data lineage and provenance are a compliance dream for regulated sectors.
- Powerful security model for multi-tenant and sensitive environments.
- Handles messy, heterogeneous integrations (IoT, mainframes, APIs, and cloud) in one canvas.
- Scales horizontally and runs reliably in clustered setups.
- Huge open-source community and frequent updates from Apache contributors.
Cons:
- Running large, high-volume clusters can be an infrastructure-heavy and resource-intensive endeavor.
- Advanced features (e.g., dynamic flow templates, parameter contexts) require deep configuration knowledge.
- Version control isn’t native. Collaboration and CI/CD integration require extra tooling, such as NiFi Registry.
- More focused on data routing and mediation than profound transformation logic.
- Complex flows can become visually cluttered, making governance tricky at enterprise scale.
Top ETL Tools at a Glance
| Tool and Its Rating | Best For (Primary Use Case) | Ease of Use | Connectors | Pricing Model |
|---|---|---|---|---|
| Skyvia G2 4.8 / Capterra 4.8 | Businesses consolidating data across cloud apps, databases, and DWHs; teams needing integration, backup, and API tools in one platform without heavy coding | No-Code / Low-Code | 200+ | Freemium + Tiered Plans (from $79/mo) |
| Airbyte G2 4.4 / Capterra n/a. | Broad ELT pipelines with flexible deployment (cloud/self-hosted) | Low-Code to Developer | 300+ | Open-source core + SaaS usage-based |
| dbt G2 4.7 / Capterra 4.8 | Transformations inside cloud data warehouses (SQL-first) | Developer-Focused (SQL/Jinja) | N/A (warehouse-native) | Freemium (Core) + Cloud tiers |
| Meltano G2 4.9 / Capterra n/a. | Open-source DataOps (ELT + orchestration + plugins) | Low-Code to Developer | Hundreds (via Singer taps) | Open-source core, enterprise support |
| Apache Airflow G2 4.4 / Capterra 4.6/ | Workflow orchestration for complex data pipelines | Developer-Focused (Python) | Broad (via operators) | Open-source, infra cost |
| Apache NiFi G2 4.2 / Capterra 4/5 | Real-time and batch data flow automation and routing | Low-Code to Developer | 300+ processors | Open-source, infra cost |
| Pentaho Data Integration (PDI) G2 4.3 / Capterra n/a | Visual ETL for data integration + analytics workflows | No-Code / Visual | 100+ sources & targets | Community + Enterprise subscription |
| Estuary G2 4.8 | Right-time CDC, streaming, and batch pipelines; unified ETL+ELT | Low-Code + Developer | 200+ | Usage-based (0.50/GB) + free tier (10GB) |
| Microsoft SSIS G2 4.4 / Capterra 4.6 | High-performance ETL within the Microsoft ecosystem | Visual / Developer | Dozens (Microsoft & third-party) | SQL Server licensed per core |
| AWS Glue G2 4.3 / Capterra 4.1 | Serverless ETL for AWS-centric environments | Low-Code to Developer | 70+ | Usage-based (DPU hours) |
| Google Cloud Dataflow G2 4.2 / Capterra 4.3 | Unified batch & stream processing on GCP | Developer-Focused | Via Beam + GCP integrations | Usage-based (vCPU / memory) |
| Google Cloud Data Fusion G2 – 5 / Capterra n/a | Visual ELT builder in the Google Cloud ecosystem | No-Code / Low-Code | 100+ (pre-built connectors) | Hourly instance pricing |
| Informatica PowerCenter G2 4.4 / Capterra n/a | Enterprise-grade ETL for large and complex data landscapes | Developer / Enterprise | 100+ | Custom enterprise licensing |
How to Choose the Right ETL Tool: A Buyer’s Guide
Picking an ETL tool isn’t a spreadsheet battle where the longest feature column wins. You need something that understands your data landscape as it exists today — warts and all — while keeping pace as you evolve.
Success looks like pipelines that nobody thinks about because they’re busy doing their jobs, not ones that consume all your attention.
Let’s explore a practical approach that doesn’t require translating corporate jargon.
Step-by-Step Criteria
Assess Your Data Sources and Destinations
Sketch out your data territory first. Where’s it coming from:
- SaaS subscriptions.
- Legacy databases.
- APIs.
Perhaps Excel spreadsheets, everyone pretends don’t matter.
- And the endpoint
- Warehouse for structure.
- Lake for flexibility.
- Or both because reality is messy.
Look for a tool that seamlessly integrates with your existing ecosystem without requiring custom integration. Split between on-prem infrastructure and cloud services? Connector breadth becomes essential, not extra. Similar to packing the right adapters before crossing borders, discovering your plugs don’t match the sockets after arrival is nobody’s idea of fun.
Define Your Transformation Needs
Be straight with yourself about how wild your data situation is. No rose-tinted glasses here. Some folks just need to polish up tables that are already mostly behaving. Others are rebuilding the entire logic layer from scratch because nothing talks to anything else properly.
Simple cleanup jobs? ELT approaches work great – let the warehouse do the heavy thinking. Complex business rules with calculations that branch in six directions, joins spanning multiple sources, conditionals stacked like Russian dolls? You need a tool that won’t buckle, ideally one that is comfortable with incremental loads and capturing changes as they happen.
Consider Your Team’s Technical Skills
Consider your daily users honestly. If analysts are driving, visual interfaces save them from wrestling with code they’d rather avoid. Engineers at the wheel? They’ll chase tools that embrace code, version everything properly, and slot into CI/CD without friction.
Hybrid tools exist in between – think cars with both automatic and manual modes. Analysts work visually and keep momentum, engineers drop into code when situations get complicated or custom.
Evaluate Scalability and Performance
Your data volumes will grow, and that’s not a possibility; that’s a promise. So choose a tool that can keep up when your nightly jobs turn into near-real-time streams. Look for horizontal scaling, parallelism, and efficient resource management.
Don’t just trust benchmarks – spin up a pilot. How a tool behaves under load will tell you far more than any whitepaper.
Understand the Total Cost of Ownership (TCO)
Factor in:
- Infrastructure costs.
- Hours burned on setup.
- Training that actually sticks.
- Maintenance that never really stops.
Open-source software looks attractive on the balance sheet until you realize it’s basically outsourcing complexity to your own team, which might feel like tight shoes. Managed platforms hit harder on the hourly rate, but save you from those server meltdowns.
What you’re really deciding is whether you want to build and maintain pipelines yourself, or whether you’d rather manage the people doing something more valuable with their time.
Check for Security and Compliance Features
Data security isn’t a feature you shop for; it’s the price of admission:
- Encryption must protect data both when it’s in motion and when it’s at rest.
- Access controls should be granular enough that people only see what they’re supposed to.
- Compliance with GDPR, SOC 2, HIPAA, whatever applies to your world, can’t be negotiable.
- Audit trails and data lineage sound like bonus features until regulators show up asking questions or you’re frantically backtracking a data anomaly through five systems at midnight. Then suddenly they’re the heroes of your story.
Build vs. Buy: When Should You Use a Tool?
Use a Tool When
You need something that works now, scales tomorrow, and doesn’t require reinventing the wheel – connectors ready to go, updates handled for you, support that responds.
Your team would rather spend time extracting insights from data instead of building infrastructure that has already been solved a thousand times over.
Reliability and compliance matter more than having your fingerprints on every function call.
Build Your Own When
Your workflows are too unique for off-the-shelf software – maybe you’re piping telemetry from satellites or handling edge-case regulatory logic.
You’ve got a strong engineering team that treats pipeline management as part of the core product.
Licensing costs make commercial tools a stretch, and you’re willing to invest upfront in exchange for long-term autonomy.
Conclusion
Finding your ETL tool is basically like hiring a new team member. So, it has to inspire confidence and demonstrate potential for growth. The good ones don’t just move bits from point A to point B; they bring clarity to digital chaos and change how you work.
Whether you need something your intern can figure out or something that scales to enterprise madness, the real question is: does it match your speed, your size, and where you’re trying to go?
Look, if constant data pipelines watch isn’t your idea of a good time, why not hand it off to something that just works? Skyvia makes integration feel less like surgery and more like clicking “next” a few times. On top of that, it spoils you with a no-code, visual interface and data that lands where you want it.
Your data’s already screaming insights at you, you’re just not listening yet. Give Skyvia a shot and see what happens when integration stops being your problem.

F.A.Q. for Best ETL Tools

What types of ETL tools are there?
ETL tools include cloud-based (Skyvia, Fivetran), on-premise (Informatica, Talend), and open-source (Apache Nifi, Airbyte), each serving different business requirements for integration, customization, and security.
How do I choose the best ETL software for my business?
Consider data volume, processing needs, and scalability. Cloud-based tools like Skyvia are user-friendly, while on-premise tools like Informatica offer better security control for sensitive industries.
What are the top ETL tools for large-scale data migration?
For large-scale migrations, Informatica PowerCenter and Talend Data Fabric handle high volumes efficiently, while Fivetran and Skyvia are ideal for cloud-based migrations with strong scalability.
What is the difference between batch ETL and real-time ETL tools?
Batch ETL processes data in scheduled intervals, while real-time ETL tools (e.g., Fivetran, Airbyte) offer continuous updates. Choose based on the need for immediate data consistency and speed.
