

Data processing challenges are more complex than ever. These include integrating cloud-native, legacy, and hybrid systems, managing data latency without sacrificing accuracy, and scaling pipelines under tighter budgets and stricter regulations. Does anything here sound familiar?
The path to data processes that keep pace with today’s business starts with understanding the difference between ETL and ELT. This article examines this distinction on many levels, the challenges these methodologies address, and what works best in modern data landscapes. By the end, you will gain some insights on how to transform struggles into strong tactics.
Table of contents
- What Are ETL and ELT?
- Understanding ETL: Extract, Transform, Load
- Understanding ELT: Extract, Load, Transform
- ETL vs ELT: Key Differences Explained
- How to Choose Between ETL and ELT
- Can You Use ETL and ELT Together? (Hybrid Solutions)
- The Future of Data Integration: Beyond ETL and ELT
- Conclusion
What Are ETL and ELT?
A quick tip: the main difference between ETL and ELT lies in when and where the transformation materializes. However, the devil hides in the details.
In ETL (Extract, Transform, Load), data is first extracted from various systems and sent to a separate environment for cleaning, normalization, filtering, and reshaping. The next stop is the target, which is typically a data warehouse or database where the transformed data is loaded and stored for analysis, reporting, and decision-making.
ELT (Extract, Load, Transform) overturns the last two stages. Records are extracted and uploaded into a data warehouse or data lake. Ultimately, transformation occurs within the target system itself. There is no need for a staging area due to the powerful storage capabilities of cloud-native platforms.
Now, let’s go over each approach in more detail.
Understanding ETL: Extract, Transform, Load
Since the 1970s, ETL has been the backbone of enterprise data management. It consists of three distinct steps:
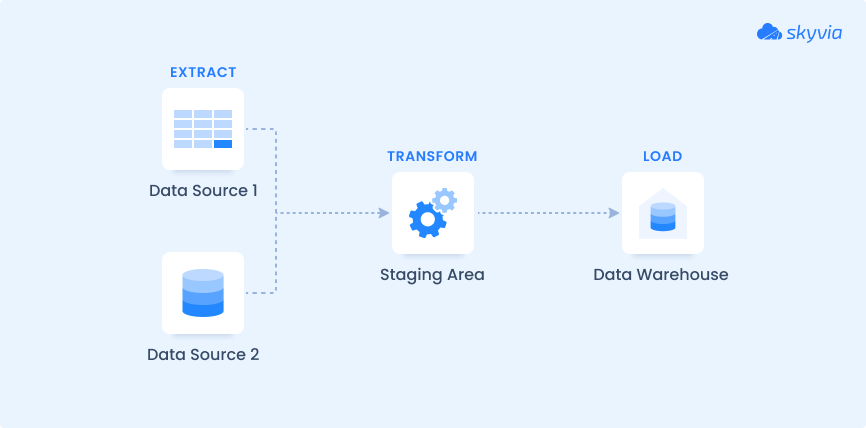
Step 1. Extract: It gathers data from various systems (cloud or on-premises). Extraction frequency depends on technical capabilities and business priorities. It can arise every time a change is made in the source or in batches (full load or incremental load). The input is temporarily isolated from operational systems during processing.
Step 2. Transform: The magic happens here – raw inputs get shaped into a clean, consistent, and usable format. This involves cleansing (removing duplicates and fixing errors), standardization (normalizing formats), merging (combining different systems’ records), filtering, aggregation, and sometimes masking to meet privacy requirements. This stage guarantees that what enters the repository system is trustworthy and ready for analysis.
Step 3. Load: Finally, the transformed records reach the destination either as a full load or incrementally to capture changes. Once loaded, it becomes accessible for the following operations.
The process can change its direction. Reverse ETL is when the source and target switch places: a data warehouse becomes a source. Then, after some transformations, insights are copied back to operational systems.
Advantages of ETL
Newer architectures rise, but benefits of ETL pipelines remain unshakable for many reasons:
- Deliver clean, trustworthy, validated datasets without duplicates and orphaned records that are critical for regulatory compliance and accurate reporting.
- Comply with GDPR, HIPAA, and others and maintain audit trails – a perfect choice for finance, healthcare, and other regulated sectors.
- Excel at handling structured records from enterprise systems, which is still a major part of many organizations’ data ecosystems.
- Its batch-oriented nature fits well with environments where real-time freshness isn’t a must, but thorough, repeatable processing is.
Disadvantages of ETL
Of course, ETL is not without challenges:
- Business fit. It may not be suitable for every business. Even companies within the same industry have unique needs depending on their data stack.
- Infrastructure overhead. While cloud-based ETL reduces some of these challenges, the complexity of configuration, including transformations and dependency management, still applies.
- Data complexity. Sometimes, the volume and variety of modern semi-structured or unstructured datasets can be too much for ETL tools optimized for structured data.
When to Use ETL
Real-World ETL Example
Echo Technology Solutions, a consulting firm specializing in Salesforce services for NGOs, needed to assist one of their clients in synchronizing customer data between Salesforce and SQL Server. The NGO required a real-time data synchronization solution to increase marketing and guarantee system consistency.
For this task, the company adopted Skyvia, a cloud-based ETL tool. This integration simplified procedures, increased data consistency, and significantly reduced manual labor. As a result, operational efficiency improved, allowing the NGO to use accurate, up-to-date data to make better decisions and engage with their customers more effectively.

Understanding ELT: Extract, Load, Transform
ELT is a modern approach that relies on the target system’s computing power to modify records on demand. It is well-suited for handling structured, semi-structured (JSON, XML), and unstructured data efficiently, meeting the needs of real-time analytics, big data processing, and iterative data modeling.
The ELT process unfolds in three distinct, sequential steps:
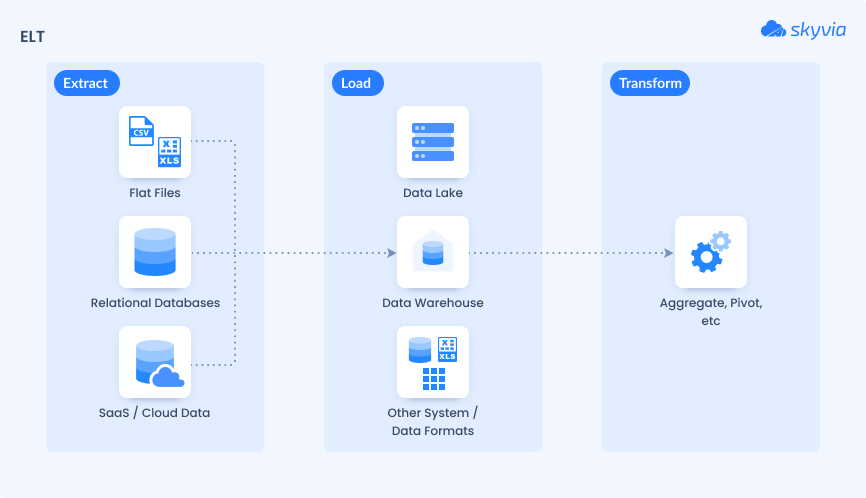
Step 1. Extract: This stage is identical to the first one in ETL – records are copied from the source, but they don’t go to a staging system.
Step 2. Load: It immediately reaches a target – a cloud data warehouse or lake.
Step 3. Transform: Occurs inside the target system, using its processing power to clean, aggregate, reformat, and enrich the data. This can include filtering duplicates, converting data types, applying business logic, and preparing for reporting or machine learning. Transformations can be executed on demand, providing flexibility for multiple analytical use cases.
Advantages of ELT
ELT is designed for modern, cloud-native environments, offering several important advantages:
- Supports near real-time analytics and immediate insights.
- Allows for experimentation, iteration, and the application of multiple transformation logic without re-extracting data, addressing rapidly changing business needs.
- Lowers complexity and operational overhead by combining data processing and storage.
Disadvantages of ELT
Despite its strengths, ELT has some drawbacks, too:
- Performance. ELT requires powerful data warehouses or lakes with sufficient computing resources. With less capable systems, performance bottlenecks quickly integrate into workflows.
- Security and compliance. Loading raw input before cleansing can pose quality and compliance risks if not properly managed. Sensitive information must be protected through masking, anonymization, and strict access controls to ensure governance within the target system.
- Transformation complexity. Advanced SQL skills or specialized tools are frequently needed to handle complex transformations inside the warehouse.
- Cloud-native design. ELT relies on scalable cloud infrastructure, which makes it less suitable for companies using traditional on-premises warehouses with limited scalability.
- Cost. Heavy transformation workloads can increase cloud computing costs, necessitating ongoing monitoring and optimization.
When to Use ELT
Real-World ELT Example
Let’s take a media streaming company that continuously collects a wealth of user interaction information:
- Data is continuously extracted from app logs, social media APIs, and CRM systems.
- All raw inputs are uploaded directly into a cloud data lake (e.g., Google BigQuery, Snowflake) without prior transformation.
- Data engineers use the platform to clean, organize, and enrich the data. They continuously improve analytics pipelines for personalized recommendations and marketing insights.
This ELT approach enables the fast and scalable ingestion of diverse data, as well as flexible, on-demand analytics, supporting real-time decision-making and advanced machine learning.
ETL vs ELT: Key Differences Explained
It’s essential to understand how they differ in terms of process flow and suitability for various data scenarios. For ETL, it is a Schema-on-Write approach, meaning data is transformed before it enters the warehouse to fit the predefined schema. That’s why it is typically used for smaller, structured datasets, as it requires significant processing before loading.
In contrast, ELT uses the Schema-On-Read approach, loading raw data into the destination system first, where transformations occur based on the query. This makes it better suited for handling larger volumes of both structured and unstructured data.
Let’s explain the key differences between ELT and ETL further.
| Criteria | ETL | ELT |
|---|---|---|
| Source | Relational Databases/Flat Files | Relational Databases/Flat Files/Images/Videos |
| Transformation | Occurs before loading | Occurs after loading |
| Destination | Data Warehouses, Data Lakes, and OLTP/Legacy Systems | Data Warehouses/Data Lakes |
| Location/Infrastructure | On-premises Data Centers, Cloud | Mostly cloud |
| Data Size | A few terabytes of data or less | Terabytes of data or more |
| Data Types | Structured data | Structured, unstructured, semi-structured data |
| Storage Requirement | Lower, only needed data will be loaded | Higher, since raw data will be loaded, including unnecessary data |
| Maintenance | High. Modifications required if the source changes or new data requirements arise | Low. New transformations don’t require new ELT pipelines |
| Scalability | Low or on-premise Data Centers | High. Cloud infrastructure can autoscale based on a processing load |
| Compliance with Data Privacy and Security Regulations | Easier to implement by removing or masking sensitive data before loading | Risk of exposing sensitive data because raw data is loaded. The ELT tool should have the means to comply with regulations |
Order of Operations
One of the fundamental distinctions between ETL and ELT lies in the sequence in which data undergoes processing:
ETL follows the order: Extract → Transform → Load.
ELT flips the last two steps, following: Extract → Load → Transform.
Data Storage Requirements
ETL requires a separate staging area to hold raw inputs during cleansing and transformation temporarily. This separation often limits scalability and leads to higher infrastructure and maintenance costs. This approach simplifies compliance by making it easier to apply masking and governance controls to source records before they are sent to the target system.
ELT consolidates both raw and transformed data within a single, scalable, cloud-native platform. Supporting a wide range of data types, this model offers greater flexibility for modern analytics. Being cloud-based, it typically involves lower upfront infrastructure costs. However, ELT requires robust governance and compliance controls within the target system.
Transformation Location
The transformation in ELT happens inside the target system. It doesn’t require a separate processing server or staging area, unlike ETL. Cloud data warehouses and lakes, with their powerful computational capabilities, efficiently handle these transformations.
In ELT, raw data is directly subjected to data cleansing, aggregation, filtering, and other required processes by the target system. This shift to in-platform processing makes it easier to scale operations and adjust transformations in response to evolving business needs.
Speed and Performance
One of ELT’s most notable benefits is its faster performance, particularly in modern cloud systems. Compared to ETL, the data ingestion process is far faster because the data is fed into the target system in its raw form.
By handling transformations at scale, cloud platforms reduce the amount of time required after loading. This speed makes ELT perfect for scenarios that require rapid data ingestion and near-real-time analytics.
Cost and Infrastructure Impact
ELT can be more cost-effective compared to ETL, particularly in cloud-native environments. Since the target system handles transformation, there is no need for additional infrastructure. That reduces both the upfront costs and the complexity of managing separate systems.
Security and Compliance
ELT introduces security and compliance challenges. Unlike ETL, where data is cleansed before loading, ELT loads raw data directly into the target system, exposing sensitive information before transformation.
To mitigate these risks, businesses must implement strong security measures within the target system, including encryption, access control policies, and data masking during transformation. ETL allows compliance checks before loading, while ELT requires businesses to establish strict post-load governance to ensure that sensitive data remains compliant with legal and regulatory standards throughout the transformation process.
How to Choose Between ETL and ELT
Although the goal of both strategies is to compile records from several sources into centralized repositories for analysis, the efficacy of data integration may be impacted by their disparate designs.
Here’s a structured guide to help you select the method that aligns with your needs.
Based on Team Skills & Tech Stack
ETL is ideal when a team is experienced with traditional integration tools and complex transformations outside the target system. It proves to be especially effective in on-premises or hybrid environments where separate transformations occur. It also requires more technical background knowledge to set up and maintain. For activities involving staging and transformation, the team may require external infrastructure, and they must be at ease with advanced data engineering.
Business users benefit from ELT’s ease of use, as it allows for more flexibility and collaboration without requiring extensive technical expertise. ELT’s transformation within the target system makes it easier for data analysts and scientists to collaborate using SQL or cloud-native tools. ELT fits best with teams that have cloud engineering skills and those adopting cloud-first or serverless strategies.
Based on Data Volume and Frequency
Do you work with smaller to moderate datasets (e.g., thousands to low millions of records) where extensive cleansing and validation are necessary before loading? ETL is for you. It works well for batch-oriented workloads where latency is acceptable, such as nightly or weekly data processing.
Do you work with massive, fast-growing datasets and high-frequency or continuous ingestion scenarios? Then, ELT is your fighter. It handles structured, semi-structured, and unstructured data at scale, supporting real-time or near-real-time analytics and IoT or streaming use cases.
Based on Budget & Timeline
Budgets often have the final word when choosing the data integration approach. So, before you start, let’s check how ETL and ELT balance investment with your project’s goals and timeline.
ETL, which requires significant upfront investment in licensed ETL tools, staging servers, and skilled engineers to design and maintain pipelines, is best suited for companies with larger budgets and longer project timelines.
ELT offers cost efficiency by using cloud storage, reducing upfront infrastructure expenses. ELT pipelines are typically faster to implement, enabling quicker time-to-value and easier scaling as data grows. This suits startups, agile teams, or organizations prioritizing speed and cost-effectiveness.
Can You Use ETL and ELT Together? (Hybrid Solutions)
Boundaries between solutions and methodologies often cross paths for better results. Many organizations adopt a hybrid strategy that combines the strengths of both ETL and ELT. This blend allows companies to make their pipelines even more flexible, tailoring them to specific data types, compliance needs, and performance requirements.
The hybrid approach maximizes data quality, scalability, and cost efficiency, customized to each data domain’s needs. Tools like Skyvia simplify the building and management of these hybrid workflows, making them accessible to teams with varied skill sets.
How Companies Blend ETL and ELT
There are a few ways to make these two approaches work together to your project’s benefit:
- Pre-Processing Sensitive Data with ETL
For critical, regulated, or sensitive information, companies apply ETL to cleanse, validate, mask, or anonymize data before loading it into a data warehouse.
- Rapid Ingestion of Raw Data with ELT
Records that are less sensitive or high-volume data are integrated in a raw state directly into a data warehouse or lake to be transformed later.
- Segmented Pipelines by Use Case
Organizations often use ETL for structured, compliance-heavy datasets and ELT for flexible, high-volume analytics, refining both governance and speed.
Tools That Support Hybrid Pipelines
Good news – many modern integration platforms increasingly support both ETL and ELT, allowing seamless hybrid architectures. For example, Skyvia offers ETL via its import scenario (transformations before loading) and ELT via replication (raw records loading with post-load transformation). Additionally, its synchronization capabilities facilitate flexible, bidirectional hybrid workflows, offering the best of both approaches.
When to Use a Hybrid Approach
ELT scalability is advantageous for handling unstructured or high-volume data, while ETL is necessary for managing structured, sensitive information.
- Balancing Speed and Governance
ELT speeds up data ingestion, while ETL preserves reliability and compliance for regulated domains.
- Legacy and Cloud Coexistence
Hybrid models support gradual cloud migration, allowing legacy ETL to run alongside new ELT pipelines.
- Mixed Processing Modes
Batch ETL for periodic reporting + real-time ELT streaming = comprehensive analytics.
- Complex Analytics and Data Science
Curated datasets via ETL complement flexible raw data exploration with ELT for machine learning.
The Future of Data Integration: Beyond ETL and ELT
AI/ML models rapidly change, significantly impacting data landscapes. As a rightful response, ETL and ELT evolve as well. From the current point, the future of data integration promises to be dynamic and automated. It will also require scalable architectures that extend beyond batch processing.
Here are key emerging trends and how modern tools like Skyvia can help you fit into this future:
- Batch processing is giving way to continuous, low-latency pipelines powered by platforms. Streaming ETL allows on-the-fly transformations, which are critical for industries such as finance, e-commerce, and IoT.
- Applying DevOps principles to data workflows, DataOps promotes automation, collaboration, and monitoring, thereby enhancing pipeline reliability and governance.
- Generative AI and machine learning automate schema mapping, anomaly detection, and code generation. This reduces manual effort and improves data quality in real time.
- Combining ETL and ELT pipelines strikes a balance between compliance and scalability. Data virtualization enables querying across diverse sources without data movement, supporting unified analytics.
- Blockchain specialists use the process to clean, organize, and enrich the data, while edge computing supports real-time analysis of IoT data.
Conclusion
The world of business isn’t black and white. Both approaches can work to your benefit, making data integration easier, more flexible, and your daily data workflow friendlier. Platforms like Skyvia support your operations through a visual interface, making what was once intricate and available only to techies accessible to more companies.
Whether it’s ETL you use or ELT, try a smoother way to integrate your data with Skyvia. Getting started is free, and the two-week trial gives you full access to all features, allowing you to explore everything it has to offer.

F.A.Q. for ETL vs ELT

When should I choose ETL over ELT for complex data transformations?
Choose ETL for complex transformations when records need significant cleansing, enrichment, or integration before loading. It’s ideal for structured data and regulated environments where strict governance and data validation are required.
How does the choice between ETL and ELT impact data security and privacy?
ETL enhances data security and privacy by allowing sensitive information to be cleansed or masked before loading, ensuring compliance. ELT, however, may expose raw records before transformation, requiring robust post-load security measures for sensitive information.
