

Managing data today feels like trying to drink from a firehose. Every app, every system, every click generates more, and businesses keep drowning instead of turning it into value.
That’s where two buzzwords show up again and again: data mesh and data lake. Both promise to tame the chaos, but they come at the problem from totally different angles. One leans on decentralization and ownership, the other on centralization and raw scale.
So which one’s right for you?
This guide breaks down the differences, strengths, and trade-offs in plain language.
By the end, you’ll know not just what each term means, but how to decide which approach fits your organization’s goals, team, and future growth.
Table of Contents
- What Is a Data Lake?
- What Is a Data Mesh?
- Head-to-Head: Key Differences at a Glance
- Decision Matrix: Which Architecture is Right for You?
- Real-World Examples: Data Architectures in Action
- Cost Comparison: A Breakdown of Total Cost of Ownership (TCO)
- Security Considerations: Central Fortress vs. Federated Guardrails
- Migration Strategy: How to Evolve from a Data Lake to a Data Mesh
- Can Data Mesh and Data Lake Coexist? The Hybrid Approach
- Role of Skyvia: The Universal Integration Fabric for Any Architecture
- Conclusion
What Is a Data Lake?
It’s a centralized repository that stores vast amounts of raw data in any format: structured (tables), semi-structured (JSON, CSV), or unstructured (text, images, logs).
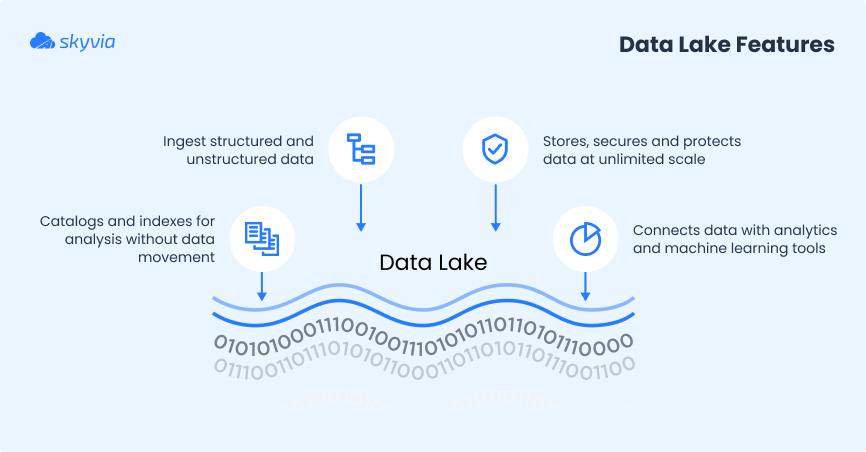
Instead of forcing data into a rigid structure before storage, it uses a schema-on-read approach. You define how the info should be interpreted only when needing to analyze it.
The core idea is simple. Dump everything into one place, keep it accessible, and figure out the structure later. That flexibility makes a data lake a powerful single source of truth for modern organizations. Data scientists can run machine learning on raw logs, analysts can query cleaned-up subsets, and engineers can connect multiple systems without reshaping data first.
In short, a data lake is about
- Scale.
- Flexibility.
- Accessibility.
A home for all data, no matter the shape or source.
Benefits
- Cost-Effective Storage. Cloud object storage is cheap and scales endlessly. You can store petabytes of data without breaking the budget.
- Flexibility with Raw Data. No need to decide upfront how data will be used. Structured, semi-structured, unstructured. It all fits.
- Centralized Analytics Power. With all data in one place, teams can run advanced analytics, machine learning, and BI on top of the same repository.
Challenges
- The “Data Swamp” Risk. Without governance, a data lake can turn into an unsearchable dumping ground where value gets lost.
- Governance Complexity. Managing access, compliance, and metadata across diverse datasets requires careful planning and dedicated tools.
- Potential Bottlenecks. If a central team owns everything, requests pile up, slowing down access and innovation for other departments.
The Data Lake Tool Ecosystem
- Storage: AWS S3, Azure Data Lake Storage (ADLS), Google Cloud Storage.
- Processing: Apache Spark, Databricks.
- Governance: AWS Lake Formation, Azure Purview.
What Is a Data Mesh?
It’s a decentralized data architecture that treats data as a product, owned and managed by the teams closest to it. Instead of pushing everything into one central repository (like a data lake), it distributes responsibility across domains: sales, finance, operations, etc. Each team ensures their data is accurate, accessible, and usable by others.
The concept rests on four core pillars:
- Domain-Oriented Ownership. Data responsibility is shifted to the teams that generate and understand it, reducing bottlenecks at a central IT team.
- Data as a Product. Each dataset is treated like a product, with clear owners, quality standards, and documentation to ensure usability.
- Self-Serve Data Platform. Teams get the infrastructure and tools to easily publish, discover, and consume data products without relying on centralized gatekeepers.
- Federated Computational Governance. A balance of decentralized ownership with centralized standards, like security, compliance, and interoperability, enforced through automation.
In short, a data mesh decentralizes data management while keeping governance consistent, helping large, complex organizations scale data practices without drowning a central team.
Benefits of a Data Mesh
- Scales with Organization Growth. By decentralizing ownership, data mesh avoids bottlenecks that happen when a central team tries to manage everything.
- Domain Expertise Built-In. The teams that create the data also manage it, meaning fewer misinterpretations and higher quality outputs.
- Improved Agility. Teams can publish, consume, and iterate on data products quickly, without waiting for central approvals.
Challenges of a Data Mesh
- Cultural Shift Required. Moving from central ownership to domain-driven responsibility requires new skills, incentives, and a mindset across the company.
- Governance Balance. Too little central oversight leads to chaos, too much reintroduces bottlenecks. Striking the right balance is tricky.
- Not a Fit for Smaller Orgs. If the data volume or team size is limited, a data mesh may add unnecessary complexity compared to simpler centralized models.
The Data Mesh Tool Ecosystem
- Platforms for Self-Serve: Snowflake, Databricks, Google BigQuery.
- Data Product Catalogs: DataHub, Amundsen, Collibra.
- Governance & Security: Immuta, Apache Ranger.
Integration
Whether you choose a data lake or a data mesh, integration is the lifeblood that makes it all work. Data scattered across CRMs, ERPs, SaaS apps, and databases doesn’t magically flow into the lake or mesh. You need reliable pipelines to get it there.
The challenge? In a data lake, you’re funneling everything into one big storage system. In a data mesh, you’re empowering domain teams to:
- Manage their own pipelines.
- Publish their data products.
- Keep them discoverable.
Either way, the tools you use determine whether the system runs smoothly or becomes a tangle of brittle scripts.
That’s where modern integration platforms like Skyvia, Fivetran, Stitch, dbt, Airbyte, etc., become the hero.
They give domain teams self-serve power while still ensuring consistency and governance at the organizational level.
Examples
- Real-time Salesforce integration. See how an ERP automation platform set up seamless, real-time syncing with Salesforce using Skyvia’s automation workflows.
- QuickBooks ↔ SQL integration tutorial. Practical demo of setting up replication from QuickBooks Online to SQL database, all done visually.
- Snowflake and Salesforce sync. Record a flow that moves data effortlessly between Salesforce and Snowflake, with reverse ETL ability.
Why it matters. These tools make integration practical whether you’re pushing data into a central lake or empowering domain teams to share data products in a mesh. Real connections, real-time updates, and none of the traditional script brittleness.
Head-to-Head: Key Differences at a Glance
Both data lakes and data meshes solve the problem of scattered data, but they come from very different philosophies.
Here’s how they stack up when businesses put them side by side.
| Feature | Data Lake | Data Mesh |
|---|---|---|
| Architecture | Centralized Monolith | Decentralized, Distributed |
| Data Ownership | Central IT/Data Team | Decentralized Business Domains |
| Data Vision | Data as a collected asset | Data as a discoverable product |
| Governance | Top-Down, Centralized | Federated, with Global Rules |
| Primary Cost Drivers | Storage, Central Team Headcount | Platform Tooling, Domain Expertise |
| Security Model | Perimeter-based, Central Access | Zero-Trust, Access via Contracts |
| Required Skills | Data Engineering, Central Governance | Product Thinking, Domain Expertise |
| Ideal For | Centralized analytics, R&D | Complex organizations, data products |
Decision Matrix: Which Architecture is Right for You?
Not sure which one fits your company? Here’s a practical way to decide:
| Factor | Choose a Data Lake If… | Choose a Data Mesh If… |
|---|---|---|
| Company Size & Structure | You’re a small-to-medium business or have a centralized structure. | You’re a large, complex enterprise with multiple, distinct business units. |
| Data Maturity | You’re early in the data journey, focusing on consolidation and storage. | You’re mature but hitting scalability bottlenecks with the central team. |
| Strategic Goal | Your priority is low-cost bulk storage for BI and ML exploration. | Your priority is agility, speed to market for data applications, and scaling innovation. |
| Culture & Budget | You have a strong central IT team and a budget focused on infrastructure. | You are ready for organizational change and can invest in a platform team and domain talent. |
Real-World Examples: Data Architectures in Action
Case Study 1: Data Mesh in Retail
A global retailer created domain-owned data pipelines. E.g., e‑commerce and logistics teams managing their own datasets to speed up insights for personalized marketing. They moved from months to weeks in delivering targeted offers.
How Skyvia helps: Domain teams use its no-code integration and replication tools to self-serve their datasets into shared repositories without centralized bottlenecks.
Example
Learn how integration platforms drive flexibility in distributed models.
Case Study 2: Data Lake in SaaS Startup
A B2B SaaS company built a centralized data lake on AWS to unify product usage logs, support tickets, and onboarding stats. The consolidated view led to a 40% reduction in churn once analysts pinpointed key drop-off behaviors.
How Skyvia helps: It automates the ingestion and transformation of raw logs and CRM data into data lakes or warehouses, making cross-system analytics seamless.
Explore how Skyvia streamlines ETL into data repositories.

Cost Comparison: A Breakdown of Total Cost of Ownership (TCO)
Neither a data lake nor a data mesh is “free.” Both come with trade-offs in infrastructure, people, and tools. The real question is where the costs land, central vs. distributed.
Data Lake Costs
- Infrastructure. Primarily cloud storage (e.g., AWS S3, Azure Data Lake Storage, GCS). Storage itself is cheap, but costs scale with data volume and redundancy needs.
- Personnel. A large, specialized engineering team is usually required to manage data ingestion, schema design, and governance.
- Software. Licenses for ETL/ELT tools (Skyvia, Talend, Matillion), data quality platforms, and BI tools (Tableau, Power BI) add up.
Data Mesh Costs
- Infrastructure. More distributed systems across domains. This approach often means higher compute costs, as multiple teams process and serve their own datasets.
- Personnel. A central platform team is needed to maintain the mesh. On top of that, each domain needs skilled data owners, either upskilled staff or new hires.
- Software. Tools for data catalogs (Collibra, Alation), API management (Apigee, Kong), and robust integration platforms (Skyvia, Fivetran, dbt) are essential to keep governance intact.
Quick Cost Comparison Table
| Cost Factor | Data Lake | Data Mesh |
|---|---|---|
| Infrastructure | Low-cost storage, centralized. | Higher compute costs, distributed. |
| Personnel | Centralized data engineering team. | Platform team + domain experts. |
| Software | ETL/ELT + BI tools. | Catalogs, APIs, orchestration. |
| Overall TCO | Cheaper infrastructure, expensive people. | Higher infrastructure + broader talent needs. |
| Fits For | SMBs or companies consolidating data for BI/ML. | Large, complex enterprises scaling data products. |
Security Considerations: Central Fortress vs. Federated Guardrails
When it comes to security, data lakes and data meshes don’t just differ in architecture. They differ in mindset.
- One is about building a fortress around the data.
- The other is about guardrails baked into every product.
Data Lake Security Best Practices (Central Fortress)
In a data lake, the model is: lock it all down at the gates.
- Strong Perimeter Security: Firewalls, VPCs, and IAM rules protect the lake’s entry points.
- Centralized Role-Based Access Control (RBAC): Permissions are managed by a central team to control who can access what.
- Encryption: All data is encrypted at rest and in transit to prevent leaks.
This fortress approach works, but it can create bottlenecks. Every access request routes through the central team.
Data Mesh Security Best Practices (Federated Guardrails)
In a data mesh, the assumption is: trust no one by default.
- Zero-Trust Model: Every data request is authenticated and authorized; no implicit trust between domains.
- Security Embedded in Data Products: Each domain team owns security for its data, applying governance directly at the source.
- Data Contracts (APIs): Access is granted through versioned, auditable contracts, making it clear what’s exposed and under what terms.
- Global Guardrails: Policies like PII masking or GDPR compliance are enforced computationally, across domains, without relying on manual checks.
This method gives organizations more agility but requires strong governance tech to avoid chaos.
Migration Strategy: How to Evolve from a Data Lake to a Data Mesh
Moving from a data lake to a data mesh isn’t a “rip and replace” project. It’s not about tearing down your lake. It’s about evolving it.
Think of the data lake as the first foundation stone. It can become the first managed data product in your mesh. The key is starting small, proving value, and then scaling out.
Step 1: Identify a Pilot Domain
Pick one business-critical domain: sales analytics, supply chain, or customer support. Look for a team that’s motivated and has a clear use case (e.g., reducing reporting time, enabling personalization).
This method will be your test bed for proving the mesh concept.
Step 2: Build the Minimum Viable Self-Serve Platform
Don’t over-engineer. Equip the pilot domain with just enough tools to own its pipeline:
- Integration (Skyvia, Fivetran, Stitch).
- Storage (Snowflake, BigQuery, Redshift).
- Transformation (dbt, Spark).
- Serving (APIs, dashboards, data catalogs).
This way, they can publish data as a product without waiting on central IT.
Step 3: Establish the Federated Governance Council
Now the glue. Create a cross-domain team to set global rules:
- Data product standards (naming, metadata, documentation).
- Security & compliance policies (GDPR, HIPAA, SOC 2).
- SLA expectations (freshness, reliability, access contracts).
Think of it as a constitution for your mesh.
Step 4: Scale and Evangelize
Once the pilot shows value (faster insights, less dependency on central IT), use it as a success story. Evangelize it internally, refine your platform, and onboard new domains one by one. Scaling a mesh is cultural as much as technical.
Can Data Mesh and Data Lake Coexist? The Hybrid Approach
Here’s the good news: you don’t have to pick data mesh vs. data lake and fight it out. In fact, most modern enterprises end up with both.
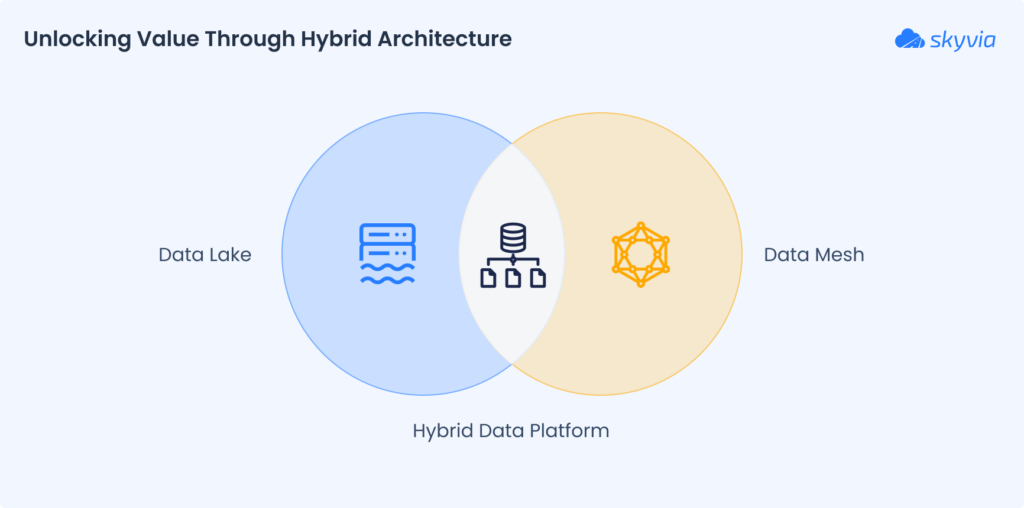
Think of a data mesh as an operating model and a data lake as an infrastructure component. The mesh says who owns what and how data products are managed. The lake remains a powerful, centralized store for massive, raw data.
How they work together:
- A centralized team can manage the data lake as one of the mesh’s official data products.
- Other domains can consume from the lake (e.g., for machine learning) or publish their own curated products.
This hybrid setup means you don’t lose the economies of scale from a lake while still getting the agility of domain-owned data products.
This “best of both worlds” approach:
- Keeps deep, centralized analytics possible.
- Supports agile, decentralized product teams.
- Reduces risk of data duplication and governance chaos.
In practice, many companies start with a data lake, then gradually layer on mesh principles as the organization grows more complex.
Role of Skyvia: The Universal Integration Fabric for Any Architecture
Think of Skyvia as the universal archtecture in the data house. Whether users are running a giant lake or experimenting with a mesh, it’s the flexible fabric that keeps data flowing where it needs to go.
No leaks, no bottlenecks, just clean pipelines, ready for use.
For Your Data Lake
The lake is only as good as what flows into it. Skyvia’s Replication and ETL/ELT tools make it effortless to pipe in data from 200+ sources, like CRMs, ERPs, SaaS apps, and databases. All the stories into one central repository.
- Example: Project Syndicate used Skyvia to unify Mailchimp and GA4 data into PostgreSQL, powering a Tableau dashboard with real-time insights. That’s a data lake in action; clean, consolidated, and always up to date.
Skyvia ensures your lake doesn’t turn into a swamp by handling transformations, deduplication, and schema mapping on the way in.
For Your Data Mesh
In a data mesh, every domain team needs to be able to own and serve its data without begging central IT for help. Skyvia gives them the no-code pipelines to do just that.
- Drag, drop, publish: domain experts can build their pipelines visually.
- Share as APIs or sync with downstream systems.
- Maintain governance while granting autonomy.
- Example: Exclaimer consolidated billing and subscription data into Salesforce using Skyvia. That’s “data as a product” in real life: data packaged, documented, and consumable by others.
For Your Migration
Migrating from a data lake to a mesh is like renovating while living in the house. You can’t tear everything down and start fresh without a bridge.
Skyvia is the one. It connects to the legacy data lake, lets users spin up the first data product for a pilot domain, and helps people replicate the success across the org.
- Example: NISO automated data consolidation across MySQL, Excel, and QuickBooks with Skyvia. What once took days now updates overnight. There was the perfect stepping stone toward a more distributed, mesh-ready model.
Conclusion
Let’s zoom out. Data lakes and meshes are simply two strategies for taming the same flood of information. Both solve the challenge of scale, but they come from different angles.
- A data lake offers centralized control and cost-efficiency. It’s the “big vault” approach: one place for everything, with strong governance and economies of scale.
- A data mesh offers decentralized agility and scalability. It’s the “federated city” model: every domain manages its own neighborhood, but all follow the same rules of the road.
The right choice depends on your organization’s size, culture, and goals. Smaller and mid-sized companies often find lakes more practical. Large, complex enterprises lean toward mesh to avoid bottlenecks and empower domain teams.
And in reality?
Many companies end up with a hybrid: a centralized lake at the core, with mesh principles layered on top.
But no matter which path you choose, one truth remains: without reliable integration, neither model works.
No matter what you’re going to do: build a centralized data lake or empower a decentralized data mesh, you need a strong integration backbone. Try Skyvia’s free plan to see how it can accelerate the data strategy now.

F.A.Q. for Data Mesh vs Data Lake

Can a data mesh and a data lake work together?
Yes. A data lake can serve as one “data product” within a mesh, while domains publish their own products. This hybrid approach combines centralized analytics with decentralized agility.
Which is more cost-effective: data lake or data mesh?
Data lakes are cheaper for storage, but they require a strong central team. Data meshes cost more in infrastructure and personnel but pay off in agility for large, complex organizations.
Is a data mesh suitable for small businesses?
Not usually. Small and mid-sized companies often benefit more from a centralized lake. Mesh makes sense for large enterprises with many domains and complex data needs.
How can Skyvia support both data lakes and meshes?
Skyvia provides no-code pipelines for integration, replication, and APIs. It helps centralize data for lakes or empowers domains in a mesh to publish data products with governance intact.
