

Data mesh and data lake are not just buzzwords but modern approaches to data management. Both of them emerged at the crossroads of unimaginable data spikes and the development of new technologies.
Many businesses have already understood that data is a crucial asset, but its potential is revealed only when proper management techniques are applied. Both data mesh and data lake address large amounts of data, each in its own way.
Discover key similarities and differences between data mesh and data lake in this article. Decide which approach is a win-win for your business, or maybe you want to implement both?
Table of Contents
- What Is a Data Mesh?
- What Is a Data Lake?
- Comparing Data Mesh and Data Lake
- Choosing the Right Approach for Your Business
- Role of Skyvia in Dealing with Data Mesh and Data Lake
- Conclusion
What Is a Data Mesh?
Definition and Principles
The term ‘data mesh’ appeared only around five years ago to introduce a decentralized approach to data management. It’s a new way to organize data within large organizations and enterprises.
Data mesh relies on a distributed architecture, where each domain or team, in simple words, generates its datasets. Each domain defines its storage mechanisms, access control rules, and processing pipelines.
To better understand the concept of data mesh, it’s necessary to describe the four pillars it’s based on:
- Data ownership is provided to those teams that create information.
- Data is perceived and treated as a product.
- A self-service data platform is utilized to give users the possibility to access, share, and use information.
- Federated computational governance implies creating a cross-domain agreement defining data governance standards at the mesh level. At the same time, each domain has autonomy and freedom of choice when selecting the methods to achieve those data governance standards.
The main objective of data mesh is to shift from centralized data management to a decentralized one. It also aims to ensure access to data for those users who need it without the intervention of the central data team. For instance, if a Financial Director wants to get an overview of daily incoming and outgoing transactions, with the data mesh it’s no longer needed to address centralized data teams and wait for the requested data. Instead, it’s possible to access the needed data independently and much more quickly.
Benefits of Data Mesh
The value of data has been constantly increasing across all industries. One important thing is to use and process it efficiently. Data mesh provides such a possibility and brings a bunch of other benefits to businesses:
- Data accessibility. Data mesh ensures that everyone who needs specific data will get access to it.
- Boosted workflow efficiency. Given that each employee has the requested data, it’s possible to complete the tasks within the given time frames.
- Bottlenecks cut out. Employees no longer need to address centralized data teams and wait their turn to get the requested data. Instead, they can access the needed data on their own.
- Storage diversity. Data mesh allows you to store data at any location suitable for your organization or data team, enabling seamless data scaling and mobility.
What Is a Data Lake?
Definition and Principles
A data lake is a repository for data storage that can be used to aggregate all the organizational data. It can handle large amounts of structured, unstructured, and semi-structured data in its original format. They can store and process various data types, including video, audio, and documents.
Data lakes have gained popularity because their capabilities go beyond traditional databases and data warehouses. They usually make up a base for machine learning, data mining, and advanced analytics.
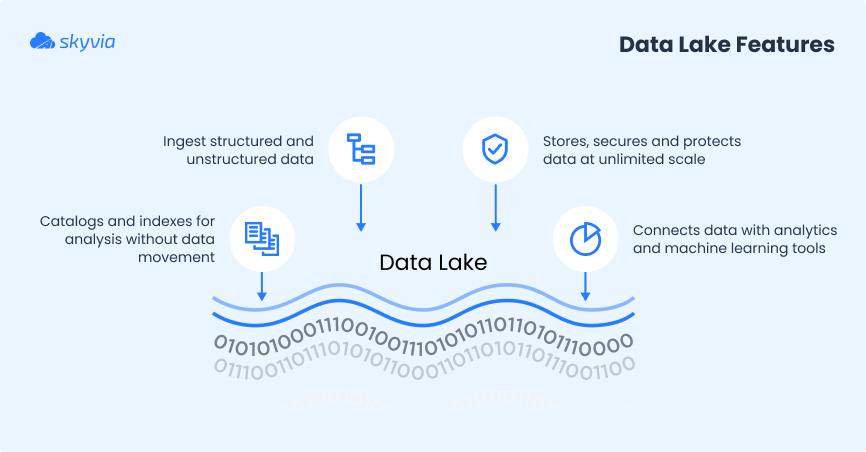
Let’s look at the characteristic features of the data lake that make it a popular choice for data management:
- It allows users to store different data types and convert them to other formats.
- It guarantees secure access to data at any time.
- It can be used as a base for data analytics to reveal insights and trends from data.
Benefits of Data Lake
A data lake is a complex structure that is useful for different kinds of organizations. No matter whether you are a small business that operates large amounts of data or a large enterprise with terabytes of data generated daily, you might consider using a data lake. And here is why it could be the right choice for your business:
- Scalability. Data lakes can handle spikes in data generation thanks to their ability to handle large data volumes and scale quickly.
- Cost-effectiveness. Most cloud providers offer affordable rates for storing large amounts of information.
- Flexibility. Data lakes support a variety of formats so that data can be stored as it is.
- Centralization. Very often, data lakes appear as central repositories that can be accessed by all authorized users.
Comparing Data Mesh and Data Lake
Our mission is to help you decide between data mesh and data lake. That way, the confrontation of these two approaches is inevitable. While data mesh is more about a philosophical-social approach, data lake is an architectural paradigm.
The first stage of confrontation is to explore the challenges of both data mesh and data lake.
Data Mesh Challenges
Despite its revolutionary nature and promising future for organizational data management, data mesh has several significant drawbacks:
- Difficulty in implementation. As this concept is relatively new in the IT industry, it’s not so easy to find a specialist who knows how to implement it right. Moreover, testing and adopting the data mesh principles across all the organizational departments might take plenty of time.
- Data duplication. Since each team is responsible for its dataset, there might be similar datasets across different departments. This creates difficulties for data analytics teams in driving meaningful insights and accurate organization-wide reports.
Data Lake Challenges
Even though data lakes are suitable for many use cases across organizations, they can cause some problems. Here are some of the typical ones:
- Difficulties for data analysis. Since data lakes allow users to operate a myriad of data types, it might be difficult to develop a standardized scheme required for analysis.
- Data quality deterioration. Poor control of the loaded data can lead to duplication and other issues, which generally decrease data quality.
- Poor data management. Even though data lakes are great storage options, they become more useful when combined with data management techniques.
- Connectivity. A data lake should integrate with other organizational tools and data platforms. For that, organizations need to implement reliable ETL solutions that can connect to the needed data sources.
- Bottlenecks. With centralized data management, teams might experience long waiting times to get the needed data from the IT team.
Data Mesh vs Data Lakes Comparison
It’s safe to say that data mesh and data lake have something in common. However, these concepts are still somewhat different. So, let’s compare these two approaches to data management.
| Data mesh | Data lake | |
|---|---|---|
| Grants decentralized data ownership, where each team is responsible for creating and managing a dataset. | Data ownership | Offers centralized data ownership, where all authorized users can access the storage repository. |
| Data mesh relies on distributed data systems and can use heterogeneous data sources. | Architecture | Data lake depends upon the architecture of the cloud provider. |
| Data is seen as a product. | Data vision | Data is seen as an asset. |
| Federated computational governance. | Data governance | Top-down governance. |
| Highly scalable. | Scalability | Highly scalable. |
| Complicates data analytics. | Data analytics | Can cause difficulties in data analysis. |
| Each team is responsible for integrating data from their sources of interest. | Data integration | Data integration is performed by the IT team. |
Choosing the Right Approach for Your Business
After having compared data mesh and data lake in detail, you might already have a vague idea of which one you like more. However, we’d say that both these concepts can be used together. For instance, data mesh can exploit a data lake as a data source in one of its domains.
To help you understand which concept would align with your business needs, we’d also present the key implementation steps for each approach.
Data Mesh Implementation
- Step 1: Define domains. Each data domain represents a specific set of business functions and processes within an organization. For instance, one domain may contain all sales-related information, another one can contain all the information about product inventory, and so on. Each domain should also have its owner, who will be responsible for data management and maintenance.
- Step 2: Define infrastructure for each domain. Set up systems and tools that make up the domain infrastructure. This is necessary for proper data collection, storage, and processing. Each domain owner needs to have access to the resources to effectively manage data without relying on data engineers.
- Step 3: Establish communication and collaboration channels. It’s crucial to enable communication between domain owners, so it makes sense to conduct regular meetings.
- Step 4: Monitor performance. It’s necessary to monitor data mesh domains to understand whether they perform as expected or not.
Data Lake Implementation
- Step 1: Set up the infrastructure. Select the cloud service provider for your data lake. Amazon, Azure, and Snowflake are popular choices for building a data lake.
- Step 2: Install supplementary tools. Consider adding tools for big data processing or integration to your data lake infrastructure.
- Step 3: Create metadata schemas. This is necessary for describing and understanding data stored within a data lake. Such procedures help to categorize data to enable its efficient querying and analysis.
- Step 4: Populate your data lake. Ingest data from various sources, either with batch data integration or real-time data streaming.
- Step 5: Monitor data ingestion. See how your data pipelines perform their job to identify malfunctions and detect defects promptly.
- Step 6: Set role-based access control. Make sure that only authorized users have access to a data lake. Otherwise, the lack of security and control may lead to data integrity violations or breaches.
Role of Skyvia in Dealing with Data Mesh and Data Lake
Given that both data lakes and data mesh domains usually deal with big data, there’s a need for a solution that would integrate and replicate data into your corporate data systems. That could be an ETL tool or data integration platform, such as Skyvia.
Skyvia Overview
Skyvia is a universal cloud platform that is suitable for a wide range of data-related tasks:
- data integration
- SaaS backup
- data query
- workflow automation
- OData and SQL endpoint creation
Skyvia is a no-code solution where you can build ETL, ELT, and Reverse ETL pipelines to populate your data mesh components. This platform allows you to easily implement your data integration strategy to facilitate data management, both on centralized and decentralized levels. It provides a range of other tangible benefits to users:
- Friendly user interface with drag-and-drop functionality.
- Web access to the platform via browser.
- A wide range of data integration scenarios.
- Powerful scheduling capabilities with up to 1-minute intervals.
- Availability for any type and size of business.
Integration Capabilities
Skyvia supports 190+ connectors, including cloud apps, databases, storage services, and data warehouses. Whether you choose the data mesh or data lake approach, Skyvia can send data there using the available integration scenarios.
Data Integration contains tools for implementing both simple and complex integration scenarios:
- Import allows you to implement the ETL and Reverse ETL scenarios between two data sources in the visual interface with zero code. You can apply transformations on the source data copy to match the destination data structure.
- Export allows you to extract data from cloud applications into CSV files and save them on a computer or online storage service.
- Synchronization is good for syncing data bidirectionally between two different apps.
- Replication copies raw data from the source, sends it to the destination and keeps it up-to-date. This can be an excellent option for populating your data lakes.
- Data Flow is a compound data integration scenario where you can build data pipelines with the drag-and-drop functionality. It involves multiple data sources, more complex logic, and compound data transformations.
- Control Flow is suitable for organizing data integration tasks in a specific order. It allows you to perform preliminary and post-integration actions and even set up some automatic error-processing logic for your integration.
Additional Benefits of Using Skyvia
One of the drawbacks of a data lake is the diversity of data formats, so it’s challenging to prepare data for analysis. Skyvia can help you overcome this by transforming structured data and reverting it to a unified format. It can also work with the metadata of unstructured data.
The notable drawback of data mesh is the possible data duplication across domains. While this is not a problem on the domain level, it causes some obstacles in organization-wide analytics. Skyvia can help to overcome this challenge by checking for duplicates on integration and gathering only unique data for further analysis.
Conclusion
Data mesh could be the right choice if you want to grant autonomy to different business departments. In this case, data management is decentralized, and each domain is responsible for creating and operating its data.
A data lake could be good for implementing the centralized approach to data management. This could be suitable for businesses dealing with sensitive data that needs to be governed and provisioned on the organization-wide level.
Whatever approach seems more attractive to you, it’s necessary to populate your systems with data. For that, use the Skyvia platform to integrate data into your data lake or move data to your data mesh domains. Skyvia offers a free plan to start with, where you can try out all of its functionality.

