

The sun rises, and teams across the globe wake up to spreadsheets cloning themselves, databases quarreling in different languages, and floods of chaotic information surging from every channel. If this sounds like your daily reality, welcome to the club; membership is unfortunately on the rise.
Traditional data management is like trying to fit square pegs into round holes. You spend countless hours cleaning and structuring before you can even think about analyzing. And while you’re busy with all of that, your competitors might already be fishing in calmer waters with data lake integration.
Curious how one can shift from constant friction into market dominance with modern data strategies? Inside this guide: proven methodologies, tangible benefits, and ready-to-implement action plans.
Table of Contents
- The Fundamentals: Data Lake vs. Data Warehouse
- How Data Lake Integration Works: The Core Processes
- The Business Value: Key Benefits of Data Lake Integration
- Common Challenges in Data Lake Integration
- The Future is Here: The Rise of the Data Lakehouse
- Best Practices for Successful Data Lake Integration
- Conclusion
The Fundamentals: Data Lake vs. Data Warehouse
There are two approaches to data storage – data lake and data warehouse. They often get lumped together or, worse, pitted against each other. The truth is, they’re specialized tools in any practical toolkit, each brilliant at what they do, but built for entirely different purposes.
What is a Data Lake?
It is a centralized repository that stores vast amounts of records in their original form, ready to be transformed into insights whenever you need them.

While traditional databases welcome only input dressed up in formal attire, data lakes roll out the red carpet for messy CSV files, chaotic JSON documents, sensor readings, customer emails filled with typos, etc.
This approach isn’t just about being inclusive; primarily, it’s about being smart, as lakes keep options open. You never know when you’ll need this or that, but until then, it patiently waits in a safe place.
What is a Data Warehouse?
It is a purpose-driven information fortress that collects, cleans, and organizes structured data from multiple sources into a single, reliable repository.
A data warehouse (DWH) can become a stage between a lake and analytics tools when you need high-performance, strict governance, consistent performance, or advanced business intelligence features.
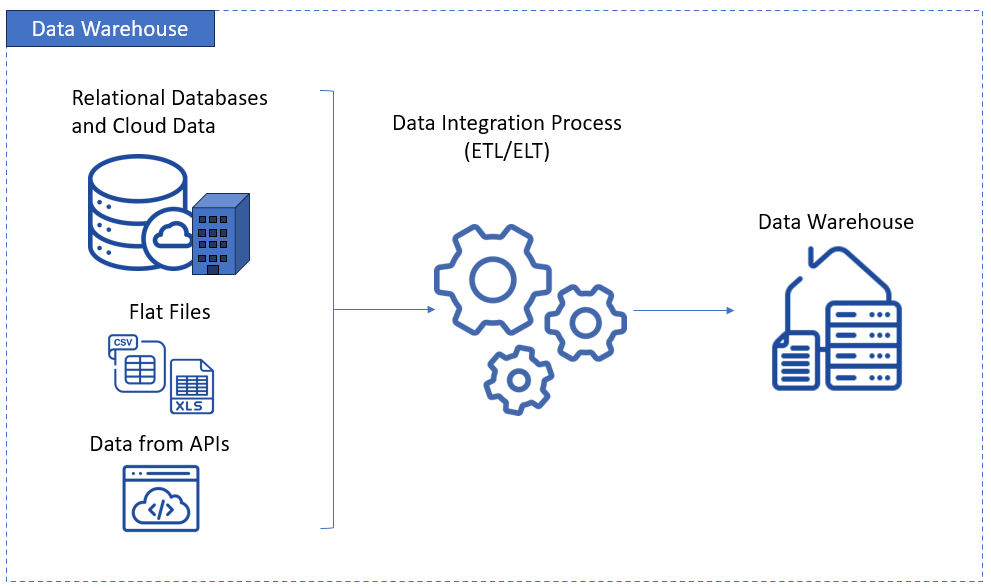
DWHs follow the “plan-before-populate” doctrine, requiring you to choreograph your data’s exact appearance before immigration. Flexibility gets sacrificed, but you gain steadfast reliability for classic business intelligence applications.
Data Lake vs. Data Warehouse: A Quick Comparison
Let’s pause and tackle the elephant in the room before exploring integration mechanics: what truly sets these storage giants apart, and why could this make or break your strategy?
| Aspect | Data Lake | DWH |
|---|---|---|
| Data Types | Raw: structured, semi-structured, unstructured | Cleaned, highly structured |
| Storage | In original format (schema-on-read) | Data is processed/organized before storage (schema-on-write) |
| Users | Data scientists, engineers, AI/ML practitioners | Business analysts, BI professionals |
| Purpose | Advanced analytics, ML, predictive analysis, real-time analytics | Traditional BI, reporting, dashboards |
| Scalability | Highly scalable and cost-effective (cloud/object storage) | Scalable but often costlier and more complex |
| Processing | ELT (Extract, Load, Transform), schema applied at retrieval | ETL (Extract, Transform, Load), strict schema during ingestion |
| Sources | IoT, social media, logs, apps, streaming data | Operational databases, CRM, ERP |
| Performance | Optimized for storing massive volumes and diverse data | Optimized for fast analytical queries |
| Governance & Quality | More challenging, risk of disorganization (“data swamp”) | Strong controls, data quality, consistent schemas |
| Cost | Lower storage costs, but can incur unpredictable analysis costs | Higher upfront and maintenance costs, but predictable query costs |

How Data Lake Integration Works: The Core Processes
Now it’s time for the behind-the-scenes tour of how raw input becomes insights.
The Role of ETL and ELT in Data Lake Integration
ETL (Extract, Transform, Load) is exactly what it sounds like – records leave the source, undergo changes, and end up in a target.
This approach worked brilliantly for DWHs, where structure and predictability reign supreme. But when the lake’s philosophy entered the scene, ETL started feeling a bit rigid for the job.
Thankfully, there’s ELT (Extract, Load, Transform), a more flexible option that stores now, figures it out later:
- Extract the data.
- Load it straight into the lake in its raw glory.
- Transform it only when it is needed.

The beauty of ELT for data lake integration flows from a target’s massive storage and computing power to handle transformations on demand. Why spend resources cleaning records that might sit unused for months when you can transform them at the speed of curiosity?
While ELT steals the spotlight, other methods like Change Data Capture (CDC) work behind the scenes to keep your lake fresh.
CDC acts like a vigilant watchdog, detecting changes in source systems and feeding only the updates to your lake, so there’s no need to reload entire datasets every time someone updates a customer record.

Key Components of a Data Lake Integration Strategy
Now, let’s explore the essential building blocks that make data lake integration patterns work in the real world. Miss one, and your entire strategy could fall flat.
- Data Ingestion: The Grand Entrance
It’s the intake process at a busy emergency room, where different types of input arrive through various channels and need to be processed efficiently.
- Batch processing shepherds the consistent parade of automated data loads. It’s bulletproof, methodical, and engineered for retrospective records that can survive without instant gratification.
- Real-time streaming serves data that refuses to sit still: social platform feed, IoT sensor readings, web navigation trails, and financial transactions.
An ingestion layer needs to be the ultimate polyglot that understands structured spreadsheets just as well as unstructured sensor gibberish.
- Data Storage: The Foundation That Scales
This layer is the foundation upon which everything else is built. Modern lakes typically lean on cloud object storage solutions like Amazon S3 or Azure Data Lake Storage – an infinitely expandable digital archive that charges you only for what you use.
Though records settle into the lake as-is, this doesn’t demand that you make heads and tails of it each time you pursue understanding. Storage can be divided into logical zones that mirror the journey from raw to refined. Here’s how it can look:

This zoning approach is a practical strategy that helps manage costs, performance, and governance across different data maturity levels.
- Data Processing and Transformation: Where Magic Happens
That is a workshop where rough elements become refined. The transformation workflow addresses everything from primary sanitization (mending inconsistencies, aligning formats) to complex enrichment (weaving location data into network identifiers, generating customer profitability forecasts).

- Data Governance and Security: The Guardians of Order
A lake ecosystem can quickly degrade into an unusable chaos if there’s only loading and no governance. Four whales support security inside data lakes:
- Cataloging
- Access controls
- Quality monitoring
- Compliance and audit capabilities.
Jump straight to the details or keep scrolling to get there naturally.
The Business Value: Key Benefits of Data Lake Integration
The question “Does data integration work?” is a bit outdated. We already know that it works beautifully. The real conundrum these days is “How much competitive advantage am I sacrificing by avoiding it?” And we have an answer to this one.
Break Down Data Silos for a Unified View
With data lake integration, your CRM can finally shake hands with the ERP system, IoT sensors can chat with social media feeds, and suddenly everyone’s moving toward the shared goal.
Let’s take Coca-Cola Andina, a drinks bottling operator spanning multiple Latin American countries. Transportation monitoring, warehouse management, and client delivery information lived in separate silos across numerous systems.
They consolidated everything into an AWS data lake, and the ripple effects were rapid: faster analytics, coordinated strategies across departments, and everyone’s numbers sing in unison.
Fuel Advanced Analytics, Machine Learning, and AI
To comprehend this advantage, imagine an art gallery and a massive artist studio. The first one is a traditional database – everything is organized, nicely composed, but you can only display what fits the format. Picasso can’t go near the Rembrandt.
The second one is a data lake, where raw creativity and experimentation thrive. Now, those two can hang out together.
Airbnb’s data lake on AWS is a great example. The company uses it to store and manipulate enormous volumes of booking, accommodation provider, and customer information crucial for smart systems that project perfect rates and enhance interface experiences.
That is especially beneficial for machine learning algorithms, notorious gluttons. They devour vast amounts of information to identify patterns that human analysts might miss entirely.
Enhance Business Agility and Innovation
When broader audiences can analyze information independently, you generate multiple angles, expanded testing, and consequently, more revolutionary insights. This creates a significant competitive advantage – everyone collects data, but not everyone can use it effectively.
By introducing their Hadoop data lake, Uber ignited a culture of rapid experimentation. With the fragmented information gathered into a unified workspace, the team could pursue solutions directly.
At the same time, engineering teams began developing groundbreaking features like shared transportation and intelligent pricing mechanisms.
Reduce Costs and Improve Scalability
While business growth brings smiles, data growth often brings stress. Lakes adapt smoothly from small collections to vast repositories without demanding expensive renovations or crushing financial commitments. Beyond space, lakes centralize the whole operation and let automated processes handle the heavy work.
When TTEC consolidated its disparate sources into a lake, it achieved significant cost reduction and better scalability. From that moment, the need for multiple tools and platforms was no longer valid.
Common Challenges in Data Lake Integration
Building a data lake sounds easy enough – just dump everything into one massive repository and let that cook there.
You’re almost right, but lakes come with their own set of pitfalls that can trip up optimism. Let’s take a look at the usual suspects plus the smart moves to sidestep them.
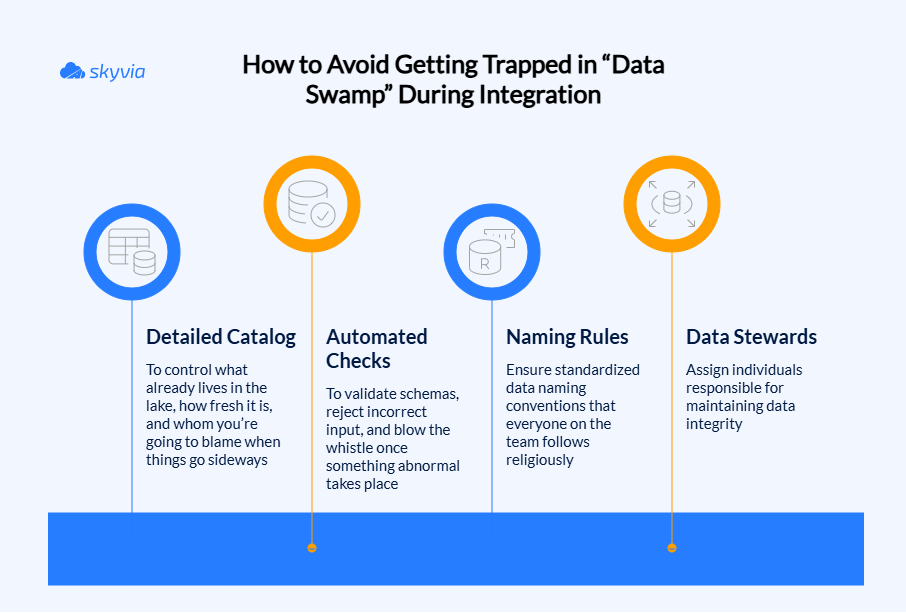
The “Data Swamp” Problem
What happens with a lake whose ecosystem has no governance, and everything gets dumped there? It turns into a data swamp that’s about as user-friendly as a maze in the dark.
But just like Shrek managed to clean up his swamp, you can shape the mess into an organizational dream.
Data Security and Compliance
Despite such advantages as accessibility and flexibility, one of the key challenges is security. Things become even more frustrating when you factor in compliance requirements. GDPR, HIPAA, and SOX each wave around their own unique set of demands.
One fumbled security setting or missed personally identifiable detail can plunge a lake into compliance quicksand.
Since lakes mash together structured and unstructured records until the boundaries disappear, traditional security mechanisms come up short.
The issues multiply when lineage comes into play – once confidential records start hopscotching through different processing phases and mingling with other collections, tracing their path becomes a wild goose chase.

Scalability and Performance
What performed beautifully with millions of records starts grinding to a halt when you hit billions. And now query performance tanks, processing jobs start timing out, and users begin complaining that their reports take forever to run. Everyone is demanding resources from infrastructure that’s already gasping for breath.

The Future is Here: The Rise of the Data Lakehouse
For years, data architects have been stuck in a love triangle between the freedom of data lakes and the reliability of DWHs.
But what if someone figured out how to get the best from both without sacrificing the fun? Meet data lakehouse – the equivalent of the perfect middle ground everyone said was impossible to find.
What is a Data Lakehouse?
It’s a system that can house the messiest log files alongside the most pristine customer records. That is possible through a few key innovations:
- Lakehouses bring order to the chaos of data lakes through ACID transaction support, making sure all operations stick to being atomic, consistent, isolated, and durable, even when handling enormous datasets that live across different storage locations.
- A thorough catalog of rich metadata about every single record it holds.
- Everything lives in formats like Parquet and Delta Lake, which means a team can work with whatever technology makes them happy.
- The separation of compute and storage takes this flexibility even further. Need to crunch through a massive dataset for year-end reporting? Spin up additional compute resources for a few hours, then scale back down.
Some of the most popular lakehouse platforms enterprises love include:
- Databricks – a popular option built on proven Apache technologies. Perfect for streamlining everything from BI dashboards to ML pipelines.
- Snowflake – a unified platform supporting transactional and analytical workloads on fresh and historical data. Perfect for BI and machine learning directly on raw and processed data using familiar SQL interfaces.
Why the Lakehouse is the Future of Data Architecture
According to Dremio’s 2024 report, surveying 500 enterprises, 65% of them are already running the majority of their analytics on lakehouses.
Moreover, over 70% predict that more than half of all analytics will happen on lakehouses within just three years. Let’s see why all these businesses make this switch.
- One record and its copies across different places take up storage space everywhere. But the bigger concern is that it calls for regular maintenance while giving inconsistencies plenty of chances to worm their way in. Now, all these redundant copies have collapsed into a single source of truth that serves all analytical needs.
- Cloud storage costs a fraction of what traditional warehouse storage used to run, and the lakehouse uses this economic advantage without sacrificing performance.
- Traditional DWHs choke on the unstructured data that machine learning models need, and lakes struggle with the complex queries for BI dashboards. The lakehouse handles both scenarios, creating a platform where your data scientists and business analysts can work without crossing each other’s paths.
- Lakehouse ingests streaming data and makes it instantly available for dashboards and analytics. As a result, fraud detection catches transactions as they happen, recommendations adapt in real-time, and monitor spots issues before they disrupt workflows.
- You get enterprise-grade features that compliance officers love – built-in access controls, automated lineage tracking, and full encryption.
- Most significantly, lakehouses future-proof your approach like nothing else can. Open architecture lets you embrace new tools without overhauling everything.
By this moment, it is a rock-solid fact that the data lakehouse isn’t just another trend that’ll be forgotten in a few years. They represent a fundamental shift from inflexible, specialized systems to adaptable, unified architectures.
Best Practices for Successful Data Lake Integration
Building an effective lake is like planning the perfect city. So, you need a roadmap. Let’s create it:
- Start with strategy and business objectives
Take a phased approach that makes project managers smile. Focus on impactful use cases initially, prove they deliver value, and only then expand your scope. Risk gets reduced, confidence builds up, and you maintain the breathing room needed to adjust when original assumptions prove incorrect.
- Choose the right tools
Pick technologies that handle your specific headaches rather than getting swept up by whatever’s making waves in the industry right now.
For ETL platforms, match tool capabilities to your actual requirements, not aspirational ones. Take Skyvia, for example. Here’s how you can get your data lake integration up and running without writing a single line of code:
Step 1: The first move is connecting to your, let’s say, Google BigQuery, using Skyvia’s clean, simple interface. Go with OAuth 2.0, Account Access Key, or SAS Token authentication – whatever suits your security preferences. Simply plug in your Storage Account Name and credentials, and you’re connected.
Step 2: Pick your integration strategy. Skyvia offers five flavors of data movement, each designed for different scenarios:
- Import when you need to pull CSV files or app data into your lake
- Export for extracting database records as CSV files to your storage
- Replication to keep cloud application data synced and analysis-ready
- Data Flow for complex multi-source ETL pipelines with heavy transformations
- Synchronization to keep various sources automatically synced

Step 3: Map your source and destination schemas using drag-and-drop simplicity. Apply transformations through built-in expressions, no SQL wizardry required. Set up filters to move only the data you actually need, and schedule everything to run automatically. Want it updated every minute? No problem. Just schedule it.
Step 4: Track your integration runs through Skyvia’s log, review it when things go sideways, and rerun failed jobs with a single click.
Also, if you want to move two steps forward – bring data from legacy or on-premises systems to a lake, Skyvia will be very effective. That move will present both technical and organizational challenges if there’s no mediator to reach the cloud first. So, the tool will assist in both transactions through a wide range of connectors.
One more tool to help the integration is data cataloging solutions, and they deserve special attention. They’re the difference between a well-organized library and a chaotic warehouse.
Think of platforms like Apache Atlas or AWS Glue Catalog as the GPS system for a lake. Without them, even sophisticated users might get lost.
- Implement solid data governance
Establish clear policies for data ingestion, transformation, access, and retention. Who can add new sources? What quality standards must be met? These policies need documentation and automated enforcement wherever possible.
Metadata management represents the cornerstone of effective governance. Every dataset needs a digital passport explaining its origin, structure, and quality characteristics. That enables discoverability and builds trust through transparency.
Combat the dreaded data swamp by applying all the means we described above.
- Focus on quality and reliability
Poor data quality is like a virus that spreads within the system. The cost of fixing grows exponentially downstream, so catch problems at ingestion time.
Implement automated quality checks that act like security guards at a lake entrance. Schema validation ensures incoming records match expected formats, while data profiling catches anomalies indicating upstream problems.
Create distinct data zones as we discussed above. This tiered approach gives users clear quality expectations.
Build comprehensive monitoring that tracks technical metrics like ingestion rates and business metrics like data freshness. Create dashboards giving stakeholders visibility into data health, with escalation procedures for when things go wrong.
- Automate
Set up hands-off ingestion pipelines that manage multiple sources with little human involvement. Bake in failure recovery, automatic retries, and oversight tools to maintain steady data streams when upstream systems act up.
- Foster an analytics-focused culture that sticks
Technology is only half the battle. The other half is getting people to use what you’ve built.
Democratize access through self-service analytics and provide user-friendly tools that don’t require computer science degrees. A business user who can answer their own questions without IT tickets becomes more data-driven.
Cross-functional collaboration has the power to break down silos. Create communities where analysts share techniques and learn from each other. The goal is to build network effects where value increases as more people contribute.
Conclusion
When data is both the fuel and the fire of business success, building a data lake is like constructing a reservoir that can hold every drop of insight, waiting to be unleashed whenever needed.
Since lakes are more about flexibility and multiple formats living peacefully in one environment, one might get the idea that there’s no strict planning needed. However, if you:
- Plan the right approach
- Choose the right tools
- Implement solid governance
You can build a system that keeps data fresh, accessible, and ready to ignite analytical sparks. Ready to start? Try Skyvia today and see how easy it can be to navigate the waters of data lake integration.

F.A.Q. for Data Lake Integration

What is the main difference between a data lake and a data warehouse?
A data lake stores unstructured input. A DWH, on the other hand, stores processed data. The first one is ideal for analytics and machine learning; the second one is optimized for business intelligence and reporting.
Why is data lake integration important for businesses?
It helps unify disparate inputs for deeper insights. As a result, it improves decision-making, promotes innovation, and supports AI and machine learning.
How do you prevent a data lake from becoming a “data swamp”?
Strong governance, regular monitoring, and automated quality checks are the foundation for a healthy ecosystem. Also, categorize records by applying metadata, establish standards for their naming, and map the lake structure (zones) to ease further workflows.
What role does ELT play in data lake integration?
The ELT (Extract, Load, Transform) nature matches the lake philosophy – raw input goes directly into the lake, where it can be transformed when needed for analytics.
