

Data warehouses are the absolute protagonists for storing and managing data in the modern tech world. They can be seen as the replacement for traditional RDBMS and the platform for analytics and machine learning.
Amazon Redshift is among the most popular and widely used data warehouses today. Populate a DWH with data first to see it in action and reveal its potential. While doing that manually is a crime, consider using ETL tools to bring data into a DWH promptly.
This article discusses the best ETL tools for Redshift and how they assist in data integration and management. Companies of any size and industry using Redshift data warehouse can help streamline business operations and make data-driven decisions.
Table of contents
- Key Advantages of Amazon Redshift
- What is ETL? How It Transforms Data Management in AWS Redshift
- Top ETL Tools for Redshift in 2025
- Optimize Your Redshift ETL: Achieving Speed, Efficiency, and Cost-Effectiveness
- Conclusion
Key Advantages of Amazon Redshift
Redshift is a cloud data warehouse that is a part of the huge Amazon Web Services infrastructure. It’s designed with the large-scale data sets in mind – to store and analyze them effectively.
Amazon Redshift is based on PostgreSQL, so it uses a traditional relational database schema for data storage. This guarantees efficient performance and fast querying, which is crucial for teams that aim to find answers quickly.
Key features:
- Cloud-based. Being hosted on the cloud, Amazon Redshift doesn’t require any on-premises installations.
- Scalability. DWH can handle any workload, even if there’s an unpredicted data spike or large data set to process.
- Elasticity. The capacity of the data warehouse is automatically provisioned depending on the current needs.
- Integration. Redshift easily connects to other AWS services and can integrate with other apps with Redshift ETL tools.
What is ETL? How It Transforms Data Management in AWS Redshift
ETL stands for Extract – Transform – Load – an approach originally used for converting transactional data into formats supported by relational DBs. Now, it’s mainly applied for better data management in digitalized settings by moving data between apps or consolidating it within a DB or DWH.
Redshift uses ETL scripts to populate a data warehouse, but those are complex. Therefore, it makes sense to use AWS Redshift ETL tools, which usually offer a user-friendly graphical interface.
ETL tools are directly associated with the ETL concept and bring each step (extraction, transformation, and loading) to life.
- Extract – ingesting data from a certain app or database.
- Transform – applying filtering, cleansing, validation, masking, and other transformation operations to data.
- Load – copying the extracted and transformed data into a destination app or data warehouse.
All the above-mentioned steps make up a so-called ETL pipeline. It also includes source and destination, data transformations, mapping, filtering, and validation functionalities.
Even though the concept of ETL was the pioneer in data integration, its successors, such as Reverse ETL and ELT, are gaining momentum now. Both notions are also applicable to the Reshift:
- Reverse ETL loads data back from a DWH into apps for data activation and robust operability.
- ELT is a faster alternative to ETL as it loads data into a DWH before transforming it. This is crucial for accommodating large and fast-flowing data sets in a DWH.
Top ETL Tools for Redshift in 2025
As ETL has two modern variations, it implies that some ETL tools have built-in ELT and reverse ETL algorithms. Below, find the list of the Redshift ETL tools, specifying their features and pricing models.
Skyvia
Skyvia is a no-code universal data cloud platform for a wide set of operations on data. It has the ETL, ELT, and Reverse ETL functionality for building simple and complex data pipelines with 200+ connectors available. Also, this service offers backup, workflow automation, and data querying options.
Key features
Skyvia is the best ETL tool for Redshift because it has the spectrum of all the necessary functions and attributes that make data warehousing simple but powerful.
- Replication component embodies ELT concept – it copies data from the preferred app or database into a DWH and can even automatically create tables for that data. This scenario is ideal for working with AWS Redshift and other DWHs because it allows scheduling regular incremental data updates.
- Import component connects AWS Redshift to other sources and allows loading data into a DWH (ETL) and vice versa (Reverse ETL).
- Data Flow + Control Flow tools. Data Flow enables the creation of complex data integration scenarios with compound data transformations. Control flow orchestrates tasks by creating rules for the data integration task order considering specific conditions.
Skyvia also has other data integration components as well as tools for workflow automation and creating web API points with no coding.
The biggest advantage of this service is the possibility of building all the data integration pipelines with no coding – just with the drag-and-drop visual interface!
Pricing
Skyvia offers a free plan with all principal features and connections available. Though, there are certain limitations on the frequency of integration and the amount of operated data. The basic plan extends these limits slightly, while the Enterprise and Advanced plan practically wipe them away. The latter even offers complex integration scenarios where you can include more than three sources and specify task execution conditions.

AWS Glue
AWS Glue is a modern serverless data integration service developed by Amazon. It connects natively to 70+ sources on one side and AWS Redshift on another side by carrying out data preparation and transfer operations in between. This tool simplifies data discovery and cleansing for developers by supporting coding solutions as well as for analysts by introducing a visual interface.
Key features
- Supports ETL, ETL, batch, and streaming workloads.
- Connects to 70+ sources.
- Automatically recognized the data schema.
- Uses ML algorithms to point out data duplicates.
- Schedules jobs.
- Scales on demand.
Pricing
The cost for the AWS Glue service is based on the progressive model, where the pricing depends on the duration of the job run. Try out the pricing calculator to get to know the approximate cost or get a quote from Sales.
Apache Spark
Apache Spark is an open-source distributed system primarily dedicated to big data processing for analytical purposes. It uses the MapReduce programming paradigm to handle large-scale data by implementing massively parallel operations. In case you need to process big data stored on Amazon Redshift, you can use AWS Glue or other third-party ETL tools for that.
Key features
- Supports real-time data streaming and batch data.
- Executes ANSI SQL queries and builds ad-hoc reports.
- Trains machine learning models with large datasets.
- Works with structured and unstructured data.
Pricing
Being an open-source solution, Apache Spark doesn’t have an exact pricing model. The total cost depends on the installation and configuration works performed by specialists.
Talend
Talend is another solution for data integration as well as data management and quality. Its Data Integration product connects to multiple sources, including AWS Redshift, creates ETL/ELT pipelines, and makes sure that data arrives in a favorable condition to the final destination. Talend can work both with batch and streaming data, which makes it possible to obtain real-time insights.
Key features
- Ingests, transforms, and maps data.
- Designs and deploys pipelines with the possibility to reuse them.
- Prepares data either automatically or with self-service tools.
- Ensures data monitoring and advanced reporting.
Pricing

Hevo
Another AWS Redshift ETL tool is called Hevo – an automated platform that extracts data from ready-to-use popular sources and pushes it into a data warehouse. All this can be done without the predefined schema since Hevo can apply automatic mapping settings on export. This tool also allows users to create data pipelines with no coding and transfer data in real-time.
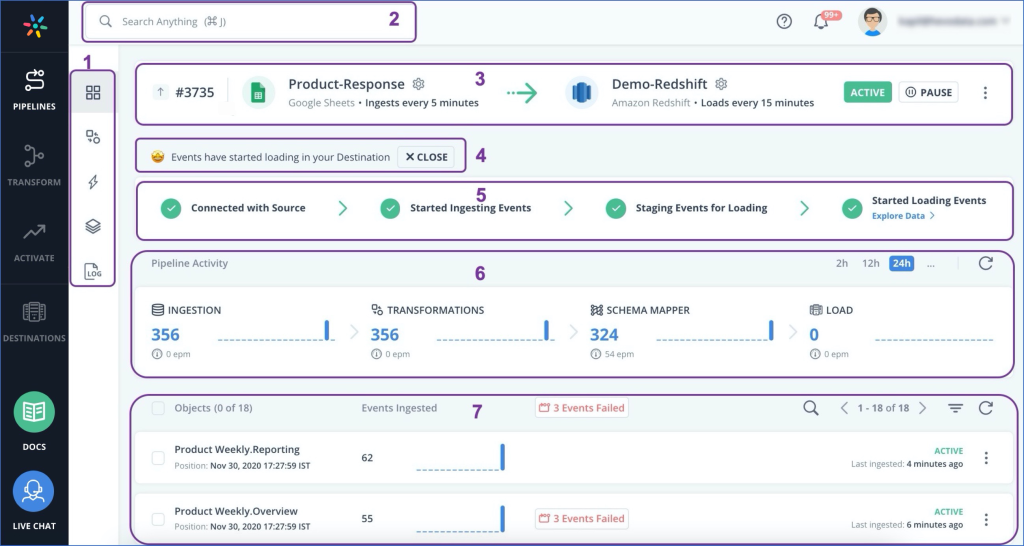
Key features
- Provides complete visibility of how data flows across the data pipelines.
- Cleans and transforms data before it’s loaded into a DWH.
- Ensures data security with end-to-end encryption and 2-factor authentication.
- Complies with SOC 2, GDPR, and HIPAA standards.
- Notifications about any delays and errors.
- Pre-aggregates and denormalizes data for faster analytics.
Pricing
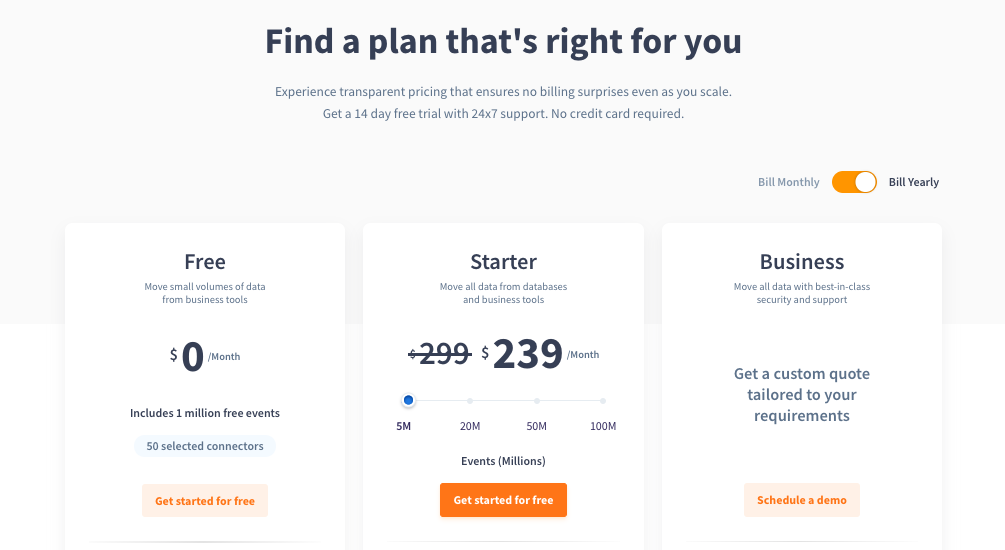
Integrate.io
Integrate.io is another solution that makes it possible to consolidate data from multiple SaaS apps and databases in a DWH. This service practically provides a 360-degree view of your data with constant observability and monitoring. It can also prepare data by loading it into a DWH, so teams can focus on deriving insights while Integrate.io is working on the data quality for analysis.

Key features
- Data transformation with a low-code approach, suitable even for non-engineers.
- REST API of Integrate.io allows users to connect to any other sources using REST API.
- Data security is provided by SSL/TLS encryption and firewall-based access control.
- Compliance with SOC 2, GDPR, CCPA, and HIPAA.
Pricing
The monthly cost of the plan for building ELT pipelines starts from $159.
Stitch
Another AWS Redshift data warehousing tool is named Stitch. It’s a cloud-based tool for data integration and management. This solution helps to move data from preferred sources to a DWH without specific IT knowledge or coding expertise.
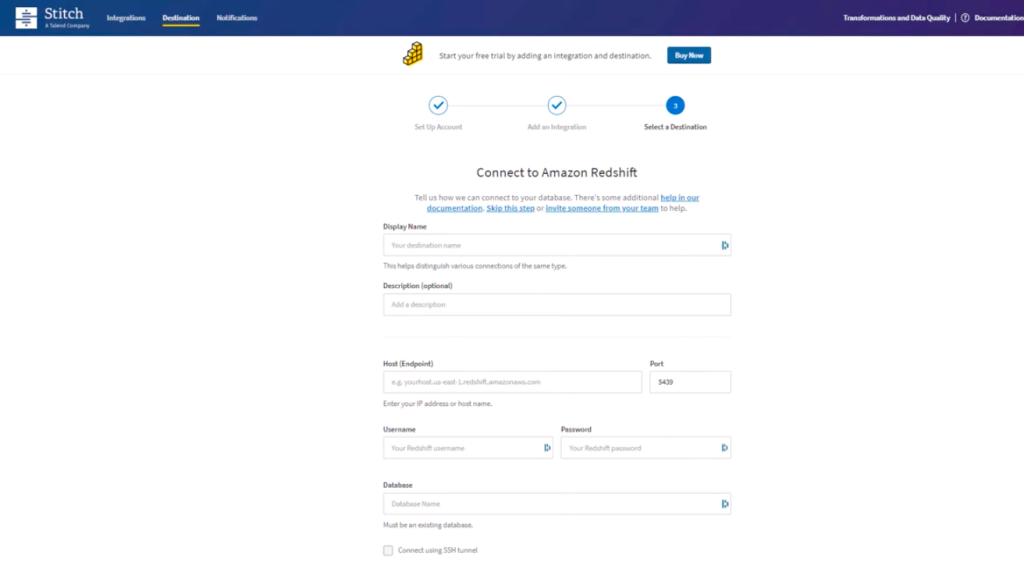
Key features
- API key management for adding connections programmatically.
- Logs and notifications on any errors.
- Advanced scheduling options.
- Automatic scaling that adjusts to the actual data load.
Pricing
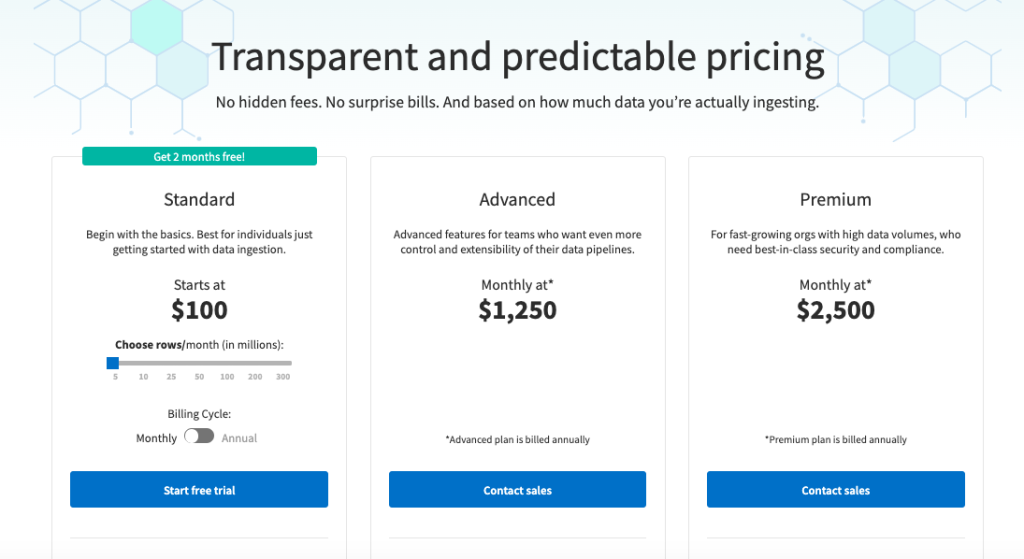
Fivetran
Fivetran is an automated platform using ETL and ELT approaches to move data between sources. This tool helps businesses gather data from diverse datasets and centralize it in a DWH for further analytics or BI purposes.
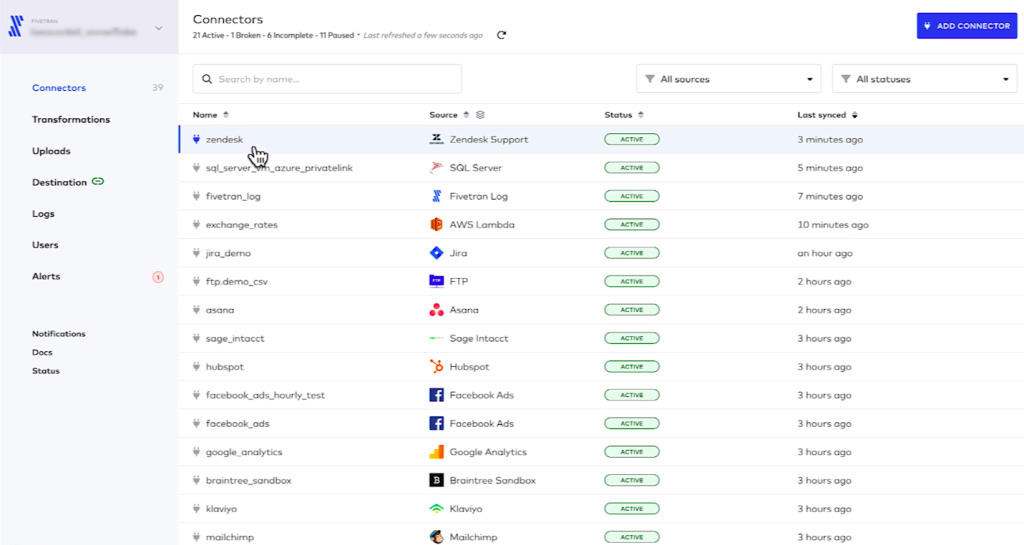
Key features
- Automatic data cleansing and duplicate removal.
- Preliminary data transformations before its load into a DWH.
- Data synchronization on schedule.
- Masking for protecting sensitive data.
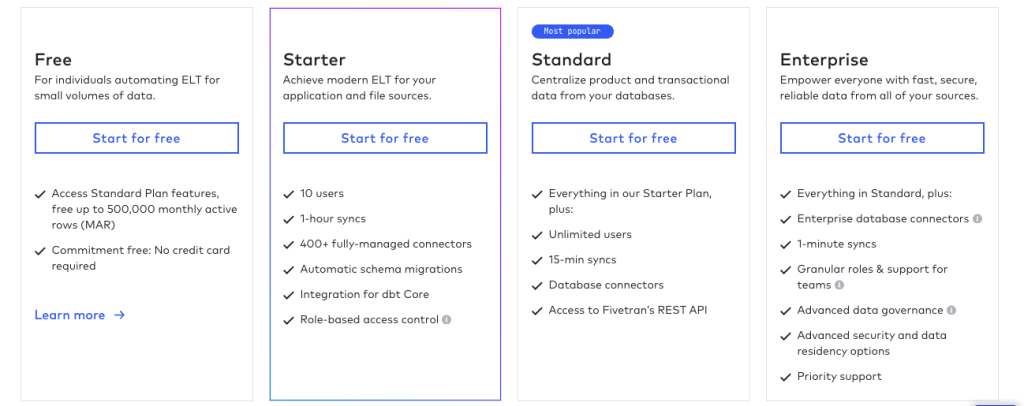
Pricing
Optimize Your Redshift ETL: Achieving Speed, Efficiency, and Cost-Effectiveness
Even though the refined ETL pipelines bring already prepared data into AWS Redshift, they also need to consider this DWH’s architecture for better results. So here we provide several pieces of advice for optimizing your Redshift ETL in order to speed up the decision-making and make the process more efficient and cost-effective.
Load Data in Bulk
Amazon Redshift is a DWH designed to operate on petabytes of data with the massive parallel processing (MPP) approach. This refers not only to the computing nodes but also to the Redshift Managed Storage (RMS). Loading data in bulk ensures that the DWH resources are used efficiently, with no nodes standing by. So, consider this when ingesting data from other sources directly within AWS Redshift or when using external ETL tools.
Perform Regular Table Maintenance
With incremental updates, the fresh data is added to the tables, while the replaced data is moved to the unsorted region of the table and only marked for deletion. However, the space previously occupied by that data isn’t reclaimed, which could significantly degrade the user query performance as the unsorted region grows. To overcome this, apply the VACUUM command against the table.
Use Workload Manager
Amazon has an in-build solution for monitoring the workload queues inside the DWH – Workload Manager (WLM). It shows the number of queues, each dedicated to a specific workload. The overall number of queues shouldn’t be greater than 15 to ensure the effective execution of all processes. In particular, the WLW helps to improve the ETL runtimes.
Choose the Right ETL Tool
The key to achieving quick and highly performing Redshift ETL is the pickup of the right ETL tool. Data load frequency, transformations, and the number of sources are the most critical criteria in making that choice. Skyvia could be a perfect choice as it designs simple and complex ETL pipelines with no code, applies advanced transformations on data, performs data filtering, and ensures constant monitoring of their execution!
Conclusion
Amazon Redshift is the preferred data warehouse choice for many companies. Its cost-effectiveness, scalability, speed, and built-in tools ensure a favorable environment for data storage and management for any company.
Even though Redshift has its own ETL mechanisms, they mightn’t always be the best option for populating a DWH. Here come professional ETL tools that connect to apps and databases, get data from there, transform it, and copy it into a data warehouse. Skyvia is the universal Redshift ETL tool with everything necessary to populate your DWH.
