

Summary
- Skyvia: Best for no-code cloud data pipelines that combine ETL, ELT, reverse ETL, and automation in one platform
- Fivetran: Best for fully managed, scalable ETL pipelines with seamless integrations across a wide range of platforms
- Stitch: Best for easy-to-use ETL with a strong focus on simplicity and broad integrations
- Talend: Best for data governance and enterprise-level ETL with comprehensive compliance features
- Apache NiFi: Best for visual flow management with powerful batch and streaming capabilities
Your data’s everywhere. Salesforce has the customers. Shopify has the orders. Google Analytics has the traffic. Finance keeps a secret stash in spreadsheets. And instead of powering growth, it’s just… chaos.
- Reports don’t match.
- Teams don’t trust the numbers.
- Decisions stall.
That’s where data pipeline tools just give a hand to your business. They’re the behind-the-scenes tech that moves, transforms, and unifies all that scattered data. Think of them as the subway system for the company:
- Clean tracks.
- Regular schedules.
- Every department connected.
In this guide, we compare the 11 best data pipeline tools for 2026.
You’ll see what they cost, how secure they are, their standout features, and where they shine.
By the end, you’ll know exactly which tool fits your team, whether you’re a lean startup or a global enterprise.
Table of Content
- What Are Data Pipelines and How Do They Work?
- Why Data Pipelines Are Crucial for Your Business
- The Ultimate Comparison: 11 Best Data Pipeline Tools for 2026
- Open-Source vs. Commercial Tools: Which is Right for You?
- Practical How-To Guides
- Real-World Use Cases & Case Studies
- The Future of Data Pipeline Technology
- Conclusion
What Are Data Pipelines and How Do They Work?
They are the processes that automatically move data from its source to a destination, transforming it along the way. So the info is clean, consistent, and ready for analysis or operational use.
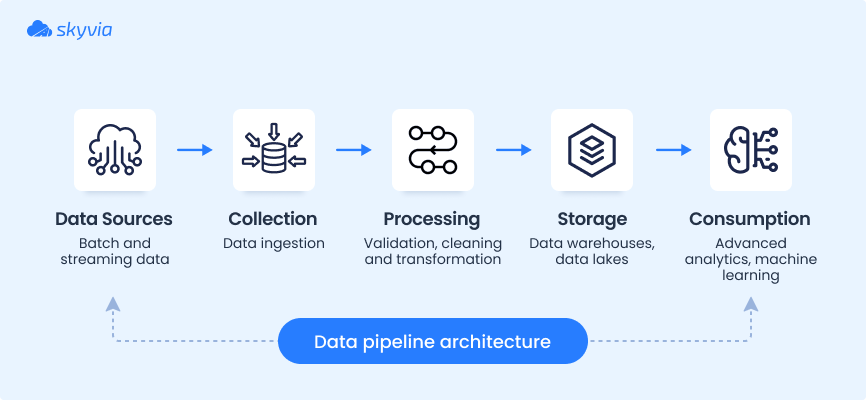
Core Components Explained
- Data Sources. Where the data originates: SaaS apps, databases, APIs, IoT sensors, or spreadsheets.
- Ingestion. The process of collecting and importing data into the pipeline, includes batch data ingestion or real-time options.
- Transformation. Standardizing, cleaning, or reshaping data (e.g., converting currencies, deduplicating records).
- Storage. Where the processed data lives, such as data warehouses (Snowflake, BigQuery), data lakes (S3, ADLS), or databases.
ETL vs. ELT vs. Reverse ETL
- ETL (Extract, Transform, Load). Transform data before loading it into storage. Ideal for strict governance and compliance.
- ELT (Extract, Load, Transform). Load raw data first, then transform it inside the warehouse. Scales well for big data.
- Reverse ETL. Pushes data from the warehouse back into operational tools (e.g., syncing churn predictions into a CRM).
Feel free to check the key differences between ETL and data pipelines.
Batch vs. Streaming
- Batch Processing. Moves data in scheduled chunks (e.g., nightly reports). Simple, cost-efficient, but not real-time.
- Streaming. Processes and delivers data continuously as it’s generated (e.g., fraud alerts, live dashboards). Critical for use cases where seconds matter.
Why Data Pipelines Are Crucial for Your Business
Data pipelines aren’t just a technical convenience; they are the backbone of modern, data-driven organizations.
Let’s see why:
Creates a Single Source of Truth (SSOT)
Pipelines unify info from scattered sources into one reliable hub. Instead of teams arguing over whose numbers are right, everyone works off the same consistent dataset.
Example: Project Syndicate used Skyvia to merge Mailchimp + GA4 into PostgreSQL, powering a single Tableau dashboard for all teams.
Enables Data-Driven Decision-Making
With clean, up-to-date data flowing into dashboards and models, leaders make decisions based on facts, not gut feelings or outdated spreadsheets.
Example: Amazon highlights how companies use Redshift ML to centralize customer usage data and build churn prediction models. By spotting early drop-off signals, teams can proactively retain customers and improve the way they decide.
Improves Operational Efficiency and Automation
Automated pipelines replace manual exports, imports, and endless copy-paste. This approach frees up your team’s time and reduces the risk of human error.
Example: NISO automated MySQL, Excel, and QuickBooks updates via Skyvia, which took days, now updates overnight.
Ensures Higher Data Quality and Governance
Built-in transformations and validation rules catch duplicates, standardize formats, and enforce compliance. Your data isn’t just centralized, it’s trustworthy.
Example: Exclaimer used Skyvia to consolidate billing/subscription info into Salesforce, improving trust and cutting manual cleanup.
Provides Scalability for Business Growth
Whether you’re adding new data sources, handling more transactions, or expanding into new markets, pipelines scale with you. No need to reinvent the wheel each time.
Example: A retailer using Databricks scaled from 5M to 50M events/month without rewriting pipelines, keeping analytics real-time.
The Ultimate Comparison: 11 Best Data Pipeline Tools for 2026
In this section, we’ll walk through the 11 top data pipeline tools worth knowing in 2026.
Each has its strengths, quirks, and best-fit use cases, and we’ll get into all that detail shortly.
But let’s be honest: before features, everyone wants to know, “How much is this going to cost me?” So here’s a side-by-side pricing snapshot to set the stage.
| Tool | Free Tier | Starting Price | Pricing Model |
|---|---|---|---|
| Skyvia | Yes. 10k records, 2 daily tasks. | $79/month (Basic). | Usage-based / pay-as-you-go. |
| Fivetran | Yes. 500k MAR, 5k model runs. | From $500/million MAR. | Usage-based (monthly active rows, model runs). |
| Apache Airflow | Yes. Open-source. | N/A (self-hosted). | Open-source, infra cost only |
| Estuary | Yes. Up to 10 GB of managed data per month. | From about $0.50 per GB per month. | Consumption based per GB, with private and BYOC options. |
| Airbyte | Yes. Open-source. | ~$10/month (Cloud Starter). | Usage-based / pay-as-you-go. |
| Stitch | Yes. Limited. | From ~$100/month. | Flat monthly tier. |
| Talend | Yes. Open-source. | Paid plans vary. | Subscription + per feature/module. |
| Integrate.io | 14-day trial. | From $15,000/year. | Enterprise annual pricing. |
| Matillion | Free credits (500). | Paid usage tiers. | Usage/credit-based. |
| StreamSets | Community (free). | Custom pricing. | Usage tier + enterprise addons. |
| Apache Spark | Yes. Open-source. | N/A (self-hosted). | Open-source, infra cost only. |
“We’re thrilled to be recognized as Top Data Integration and Data Pipeline Tool by TrustRadius and our customers. Our mission is to make data integration accessible to businesses of all sizes and to all clients, regardless of their coding expertise. Receiving this award confirms that we are moving in the right direction by creating an easy-to-use yet feature-rich solution capable of handling complex scenarios.” Oleksandr Khirnyi, Chief Product Officer at Skyvia, stated.
Skyvia
G2 / Capterra Rating
- G2: Rated 4.8 out of 5 from over 200 reviews.
- Capterra: Rated 4.8 from 103 reviews, especially noted for ease of use and value for money.
Skyvia is a no-code cloud data pipeline tool built to simplify data movement, transformation, and synchronization across your business systems. Its intuitive visual interface enables teams to design, automate, and manage pipelines without writing complex scripts or maintaining infrastructure. Skyvia supports ETL, ELT, reverse ETL, data synchronization, and workflow automation scenarios.
Skyvia is often chosen by teams that want flexibility without heavy engineering effort, balancing visual configuration with advanced control.
Best For
Businesses and teams looking for a versatile, no-code data integration platform that supports both ELT and ETL workflows. Ideal for organizations that need easy, browser-based access to over 200 connectors, want to automate data backups, and build scalable pipelines without heavy technical overhead.
Perfect for SMBs and mid-market companies, but also valuable for enterprise departments that need autonomy without waiting on central IT.
Key Features
- Visual, drag‑and‑drop pipeline builder for ETL/ELT, replication, reverse data flows, and backups.
- 200 + prebuilt connectors (SaaS, databases, warehouses), including the most popular, like Salesforce, BigQuery, Redshift.
- Offers replication, transformation, OData, API creation, email alerts, and error logging.
- Recognized for exceptional ease of use, responsive support, and cost efficiency.
Pricing Deep Dive
Skyvia offers a tier-based pricing model where cost scales based on usage (record counts, number of tasks, run frequency).
- A free tier includes up to 10,000 records and two daily tasks.
- The Basic paid plan starts at $79/month, with upward scaling for higher volume or more frequent runs. Costs rise with increased data volume, more syncs, and higher automation frequency.
Security & Compliance
- Encryption. Supports both SSL and SSH connections to secure data in transit.
- Access Control. Offers centralized role-based access management.
- Compliance. Recognized leader on G2 and rated high on trust metrics for enterprise readiness.
- Also features logging, monitoring, and configurable alerts for auditability.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Intuitive no‑code UI. Minimal learning curve. | Free tier has limited transformation depth, advanced error-handling features are restricted. |
| Broad connector library and real-time sync support. | Not as strong for enterprise-scale custom transformations compared to fully open-source tools. |
| Excellent customer support and documentation |

Fivetran
G2 / Capterra Rating
G2: Scores of 4.3 out of 5 from over 792 reviews.
Capterra: Scores 4.4 from 25 reviews.
Fivetran focuses on fully managed, standardized data replication into cloud data warehouses. It removes much of the operational overhead by automating schema management, incremental updates, and maintenance.
While highly reliable for analytics-driven pipelines, its limited transformation depth and usage-based pricing make it better suited for data teams with stable schemas and clear reporting needs.
Best For
Organizations that need robust, automated ELT pipelines with minimal maintenance.
Ideal for data-intensive enterprises, especially teams focused on rapid scaling, diverse connector coverage, and seamless schema management without coding.
Key Features
- Automated ELT pipelines that run with minimal setup or ongoing maintenance.
- 700+ prebuilt connectors for databases, SaaS platforms, and cloud services.
- Automatic schema drift handling to keep the source and destination in sync.
- Fast syncs: every 15 minutes on Standard plans, down to 1 minute on Enterprise.
- Built-in integration with dbt for in-warehouse transformations.
- High reliability: strong uptime SLAs and continuous monitoring.
Pricing Deep Dive
Fivetran uses a usage-based model billed on Monthly Active Rows (MAR).
- Free Tier. Up to 500k MARs and 5k model runs per month.
- Standard Plan. “Pay as you go” includes unlimited users and faster sync intervals.
- Enterprise & Business Critical Tiers. Adds granular access controls, private networking, and compliance certifications (e.g., PCI DSS).
What drives the costs up? Spikes in active row volume, frequently changing schemas, and real-time sync needs. Multiple connectors, each tracking MAR separately, which can complicate budgeting.
Security & Compliance
- SOC 1 & SOC 2 Type II audits, plus support for GDPR, HIPAA BAA, ISO 27001, PCI DSS Level 1, and HITRUST compliance frameworks.
- Data encryption. End-to-end (in transit and at rest)—data isn’t stored longer than necessary.
- Secure deployment options. VPN or SSH tunnels, proxy and private network support, and optional customer-managed encryption keys.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Hands-off ETL pipelines, with almost no maintenance required once set up. | Pricing unpredictability. MAR-based billing can spike unexpectedly with growing data volumes. |
| Automatic schema updates reduce downtime when source schemas evolve. | Real-time syncs cost more. Only available in higher tiers, limiting flexibility for smaller teams. |
| Strong security posture—trusted by regulated organizations. |
Apache Airflow
G2 / Capterra Rating
G2: Scores of 4.4 out of 5 from 111 reviews.
Capterra: Scores 4.6 from 11 reviews.
Apache Airflow is an open-source orchestration framework that gives engineering teams full control over workflow scheduling and monitoring.
Pipelines are defined as Python code, making Airflow extremely flexible but also more complex to maintain. It’s commonly used when teams need custom logic, tight system control, and deep integration into engineering workflows.
Best For
Technical teams and data engineers who need a flexible, open-source orchestration platform for building, scheduling, and monitoring complex data workflows. Ideal for organizations with strong Python skills seeking full control over pipeline customization and integration with version control systems.
Best suited for those willing to manage their own infrastructure and rely on community support rather than dedicated vendor assistance.
Key Features
- Define workflows as Directed Acyclic Graphs (DAGs) in Python, which are highly flexible and dynamic.
- Clean “Workflow as code” approach, allowing loops, parameterization, and reuse with Python and Jinja templates.
- Robust scheduling and dependency management, with features like branching, retries, and backfills.
- Web-based UI for real-time monitoring, logging, and visual execution tracing.
- Highly extensible. Support for custom operators, hooks, and integrations across major cloud platforms, data tools, and services.
- Built for scale. Distributed executor architecture can orchestrate hundreds of tasks across many workers.
Pricing Deep Dive
Airflow is fully open-source, with no licensing cost for the software itself. However, organizations must budget for:
- Infrastructure (cloud or on-prem servers).
- Operational setup (scheduler, webserver, metadata store).
- Monitoring and user access configuration.
Note: As with many open-source tools, the software is free, but you’ll pay for its hosting and maintenance.
Security & Compliance
- Supports role-based access controls (RBAC) to control who can trigger or modify workflows.
- Authentication support via enterprise identity providers (LDAP, SSO) for secure access governance.
- Encryption support in deployment for secure communication between components (scheduler, webserver, workers).
- Versioning and UI safeguards introduced in Airflow 3.0 add execution consistency and auditability.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Highly flexible and customizable workflows as code using Python. | The backside of the coin is the steep learning curve that requires Python and infrastructure expertise. |
| Scales to complex, enterprise-grade workflows with parallel execution. | Requires significant DevOps investment to manage, secure, and scale. |
| Extensive ecosystem of operators, plugins, and community support. | Not designed for real-time streaming. Better suited for batch processing. |
Estuary
G2 / Capterra Rating
G2: Rated 4.8 out of 5 from over 25 reviews.
Estuary is a right time data platform that unifies CDC, streaming, and batch pipelines in one place. Teams can move data when they choose, whether sub second, near real time, or on a schedule, without running Kafka, custom streaming code, or separate ETL tools. It is built for continuous replication from operational databases and SaaS tools into warehouses, lakes, streams, and other operational systems.
Best For
- Teams that need low latency pipelines from OLTP databases into warehouses, lakes, search, or queues.
- Companies building event driven architectures, operational analytics, or real time customer experiences.
- Organizations that want one platform for CDC, streaming, and batch with simple consumption pricing.
Key Features
- Change Data Capture from popular databases into modern warehouses, lakes, and streaming systems.
- Right time pipelines that can be configured as streaming, micro batch, or scheduled batch per use case.
- SQL based transformations on streaming data for filtering, joins, and aggregations in flight.
- Connector catalog focused on core databases, SaaS apps, cloud storage, and analytics destinations.
- Flexible deployment, including fully managed cloud, private deployment, and bring your own cloud.
Pricing Deep Dive
- Free tier: Includes up to 10 GB of managed data per month so teams can build and test real pipelines.
- Cloud edition: Usage based pricing starting around $0.50 per GB of managed data, with volume discounts at higher tiers.
- Private and BYOC: Custom pricing for dedicated or in your own cloud deployments, aligned to scale and SLAs.
Main cost drivers are total data volume, number of active pipelines, and whether you run on shared cloud or a dedicated environment.
Security & Compliance
- Encryption in transit and at rest, with private networking options such as VPC peering.
- Role based access control, audit logs, and project level isolation for teams and environments.
- Alignment with common standards such as SOC 2, GDPR, and HIPAA for regulated workloads.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Unified CDC, streaming, and batch in one platform, no need for separate ETL and streaming stacks. | The UX is not polished yet because the platform has a lot of configuration options so the learning curve is a bit steeper |
| Right time pipelines for low latency analytics and operational use cases. | Connector catalog is growing but smaller than the largest legacy vendors. |
| Simple per GB pricing and flexible deployment, including managed cloud and bring your own cloud. |
Airbyte
G2 / Capterra Rating
G2: Review scores of 4.4 out of 5 from 65 reviews.
Capterra: No score.
Airbyte is an open-source data integration platform built around a rapidly growing connector ecosystem. It allows teams to deploy pipelines either in the cloud or on their own infrastructure and customize connectors when needed.
Airbyte works well for organizations that want extensibility and control, although it often requires more setup and monitoring than turnkey platforms.
Best For
Data teams looking for an open-source, flexible ELT platform with no-code connectors and the ability to customize or build connectors via code.
Suitable for organizations that want control over their infrastructure and integration with modern data orchestration tools like Kubernetes and Airflow. Ideal for users with coding skills who need both free self-hosted options and enterprise-grade support in paid plans.
Key Features
- 600+ open-source connectors (cloud has 550+), covering databases, SaaS apps, APIs, and more.
- Flexible connector development with low-code/SDK support (CDK), Docker-based modularity, and customization within minutes.
- Built-in CDC (Change Data Capture) support and ELT-first design with dbt integration.
- Cloud and self-hosted deployments offer flexibility for governance needs and infrastructure preferences.
- Observability tools: detailed logs, monitoring, and integrations with Datadog and Prometheus.
Pricing Deep Dive
- Open Source. Fully free, but you manage the infrastructure yourself.
- Cloud Plans:
- Cloud (Growth). Starts with a $10 base + credits. Priced per GB or per row (e.g., $15 per million rows).
- Teams. Capacity-based pricing based on the number of pipelines and sync frequency.
- Enterprise. Custom pricing with enhanced security, SLAs, and deployment control.
Cost Drivers. Volume, pipeline count, backfills, sync frequency, and credit use.
Security & Compliance
- Supports RBAC, SSO, encryption in transit/rest, and multi-region options.
- Compliance frameworks supported include SOC 2, ISO 27001, HIPAA, GDPR, and CCPA.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Massive connector library + low-code SDK for fast customization. | Requires DevOps and infrastructure—self-hosting is powerful but more hands-on. |
| Supports ELT, CDC, and modern data delivery patterns with dbt support. | Not optimized for real-time workloads (<5 mins). Batch intervals only. |
| Cloud/self-host choices give flexibility for enterprise control. | Performance can suffer at higher volumes. Some users note memory and scaling issues in forums. |
Stitch
G2 / Capterra Rating
G2: Scores of 4.9 out of 5 from over 77 reviews.
Capterra: Scores 4.3 from 4 reviews.
Stitch is a lightweight extract-and-load tool aimed at analytics teams who want to move data into a warehouse with minimal configuration. It prioritizes simplicity and fast setup over advanced transformations or orchestration.
Stitch is frequently used for straightforward reporting pipelines but may feel limited in more complex data architectures.
Best For
Small to mid-sized teams needing a straightforward, cloud-based ETL solution with a wide range of connectors and easy setup. Ideal for users who want visual pipeline management with scheduling and monitoring capabilities, and who value community-driven integrations via the Singer project.
Suitable for organizations that prioritize simplicity and scalability in the cloud but do not require on-premises deployment.
Key Features
- Cloud-based ETL service with straightforward setup. Connect and sync data in minutes.
- 130+ pre-built connectors for SaaS apps, databases, and file sources, plus support for historical data replication.
- Flexible scheduling via cron expressions; sync as often as minutes to hours.
- Rich pipeline visibility. Logs, error reporting, and loading dashboards help you troubleshoot quickly.
Pricing Deep Dive
- Free plan. Up to 5 million rows/month, making it great for lightweight usage or pilots.
- Standard. Starts at $100/month and includes core features and email/chat support.
- Higher tiers:
- Advanced (~$1,250/mo.) adds destination/source flexibility and better support.
- Premium (~$2,500/mo.) includes enhanced SLAs and customization.
- Enterprise. Custom, with compliance and HIPAA support.
Key cost drivers: Monthly row volume, number of integrations and destinations, and support/service level. Rising usage and scaling needs can increase costs rapidly.
Security & Compliance
- Offers enterprise-grade security, including SOC 2 and HIPAA compliance, along with secure connectivity, like SSH tunneling.
- Simple operational setup reduces attack surface. No local agents or complex infrastructure to manage.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Superfast to set up: pipelines up in minutes with minimal configuration. | Limited transformation functionality, mostly EL-focused, not full ETL. |
| Predictable pricing tiers and a useful free tier for smaller workloads. | Can get pricey quickly as row volume and connectors increase. |
| Clear monitoring, logging, and scheduling tools built-in. | Not open-source; less flexibility for customization compared to alternatives like Airbyte. |
Talend
G2 / Capterra Rating
G2: Scores of 4.4 out of 5 from over 68 reviews.
Capterra: Scores 4.3 from 24 reviews.
Talend is an enterprise-grade data integration platform with strong support for governance, data quality, and compliance. It offers both cloud and on-prem deployment models and is commonly used in regulated industries.
Talend is powerful, but its complexity, infrastructure requirements, and cost often make it a better fit for large organizations with dedicated data teams.
Best For
Enterprises and teams needing a comprehensive, hybrid data integration platform capable of handling complex ETL workflows across both cloud and on-premises environments.
Well suited for organizations that require robust support for structured, semi-structured, and unstructured data, as well as advanced API design and testing capabilities.
Ideal for users who value an all-in-one solution with strong governance and management features, and who can manage a more involved installation and setup process.
Key Features
- Unified platform for data integration, quality, preparation, governance, and cataloging, all in one suite.
- Flexible support for ELT, ETL, batch, and streaming pipelines with built-in CDC and Spark-based transformers.
- Drag-and-drop pipeline designer paired with low-code and developer-friendly options for reuse and fast deployment.
- Strong data governance and profiling with real-time quality monitoring, metadata management, and automated rule-based sanitization.
Pricing Deep Dive
- Talend pricing is not publicly listed. Expect enterprise-level costs. General benchmarking suggests:
- Cloud Starter: ~$12,000–30,000/year.
- Cloud Premium: $50,000–100,000+/year.
- Enterprise (Data Fabric): $150,000–$500,000+/year.
Note: Hidden costs often include implementation services, training, and infrastructure overhead, which can significantly raise total spend.
- A simplified per-user option starts at $1,100 per user per month on AWS Marketplace for Talend Cloud DI.
Security & Compliance
- Fully audited with SOC 2 Type II, HIPAA, and other enterprise-grade compliance standards.
- Designed to handle sensitive and regulated industries, with built-in support for GDPR, CCPA, SOX, and others, powered by real-time governance and risk management tools.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Broadest platform in the class: integrates ELT/ETL, data quality, governance, and cataloging in one suite. | High entry cost—negotiated contracts, makes it expensive for smaller businesses. |
| Handles streaming and batch at scale; tight governance. Ideal for enterprise use cases. | Complexity means a long learning curve. It requires specialized training and administration support. |
| Extremely flexible deployment. Cloud, on-prem, hybrid. | Less friendly for lightweight or low-touch use cases where simpler tooling could suffice. |
Integrate.io
G2 / Capterra Rating
G2: Scores of 4.43out of 5 from over 200reviews.
Capterra: Scores 4.6 from 17 reviews.
Integrate.io is a low-code ETL and ELT platform designed to simplify pipeline development while still supporting complex transformations.
It provides a visual interface combined with SQL-based logic, making it accessible to both analysts and engineers. The platform is often used by teams that want faster pipeline delivery without fully custom development.
Best For
Businesses, especially in e-commerce, looking for a cloud-based ETL/ELT platform with minimal coding requirements. Suitable for teams needing API generation capabilities and support for change data capture (CDC) workflows.
Ideal for organizations aiming to orchestrate multiple dependent data pipelines in the cloud, with a focus on integrating REST API-enabled sources. Less suited for those requiring broad connector variety or on-premises deployment.
Key Features
- Fixed-Fee, Unlimited Usage. Unlimited data volume, connectors, pipelines, and full platform access. All at a flat $1,999/mo starting price.
- Rich Connector Library. 120+ integrations with SaaS apps, databases, warehouses, BI tools, and cloud services for seamless data flow.
- Advanced Security & Compliance. Field-level encryption via AWS KMS, SOC 2, ISO 27001, HIPAA, PCI‑DSS, GDPR, CCPA, and robust firewall isolation.
- No-Code Pipelines With AI Enhancements. Drag-and-drop interface supporting ETL, ELT, reverse ETL, CDC, API generation, and data observability. Now with AI-powered pipeline prompts.
- High-Frequency Syncs & Alerts. Sub-60-second CDC support, scheduled jobs via cron expressions, and real-time monitoring.
Pricing Deep Dive
- Starter Plan. ($15K/year) Includes two connectors, daily schedules, 24/7 support, and 30 days of onboarding.
- Professional Plan. ($25K/year): Adds on-prem connectors, hourly syncs, 99.5% SLA, and enhanced support.
- Enterprise Plan. Custom pricing includes 5-minute syncs, unlimited REST APIs, and premium SLAs.
- For ELT & CDC workloads. Pricing starts at $199/month for 5M rows.
- Plus, a 14-day free trial is available to test the platform.
Security & Compliance
- Comprehensive Certifications. SOC 2, ISO 27001, HIPAA, GDPR, CCPA, built for regulated industries.
- Data Protection. End-to-end encryption, field-level masking, strict firewall rules, and verified access protocols.
- High Trust Architecture. AWS-hosted, CISSP-led security team, audit logging, and compliance-ready infrastructure.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Predictable flat-fee pricing. no row-based surprises. | High minimum spend; may be excessive for small teams or low-volume use cases. |
| Built-in security and compliance. Ideal for regulated environments. | Less flexible than pay-as-you-go alternatives if needs are variable. |
| Unified platform: ETL, ELT, reverse ETL, CDC, API generation, observability. | Slightly limited connector breadth compared to Airbyte or Fivetran, especially when it comes to niche or less common data sources. |
| AI-enhanced workflows and fast scheduling capabilities. | Pricing transparency differs by plan. Some features (e.g., ELT) priced separately. |
Matillion
G2 / Capterra Rating
G2: Scores of 4.4 out of 5 from over 81 reviews.
Capterra: Scores 4.3 from 111 reviews.
Matillion is a cloud-native data integration and transformation platform built specifically for modern data warehouses.
It excels at SQL-based transformations and integrates tightly with platforms like Snowflake, BigQuery, Redshift, and Databricks. Matillion is well-suited for teams that rely heavily on warehouse-centric ELT architectures.
Best For
Organizations seeking a cloud-native data integration platform with a user-friendly drag-and-drop interface for building ETL and ELT pipelines. Well-suited for teams that need flexible deployment across major cloud providers and want to perform transformations using either SQL or visual components.
Ideal for businesses requiring a robust orchestration and management solution with support for both cloud and on-premises data sources. Less optimal for users who prioritize extensive documentation or need fault-tolerant job restart capabilities.
Key Features
- Pay-per-use credits (vCore/hour) make compute tailorable across all tiers.
- No-code pipeline orchestration with drag-and-drop builder, job scheduling, and real-time validation.
- Supports ELT with pushdown optimization. Most transformations happen directly in the data warehouse.
- Connector support: over 150 sources, including REST APIs and popular SaaS tools.
- Higher tiers add enterprise features like audit logs, permissions, data lineage, Git integration, and HA clusters.
Pricing Deep Dive
- Basic Plan. Starts at approximately $2.00 per vCore-hour, billed as credits. Includes up to 5 users, orchestration jobs, and validation tools.
- Advanced Plan. Around $2.20/credit. Adds audit logging and finer access controls.
- Enterprise Plan. Around $2.30/credit. Adds features like data lineage, Git integration, and HA clusters.
Note: Vendors commonly quote a baseline of 500 credits (~$1,000/month), but actual cost depends on pipeline complexity and runtime.
Cost Drivers:
- Running pipelines continuously, i.e., paying for idle runtime. Can inflate costs.
- Transform-heavy or large-scale loads consume more vCores.
- Add-ons like audit, lineage, and high availability (HA) raise the spend.
Security & Compliance
- Supports role-based access control with fine-grained permissions.
- Offers audit trails, auto-generated documentation, and lineage tracking in the Advanced and Enterprise tiers.
- Designed for cloud-native deployment with enterprise-grade configurability, but specific compliance certifications (e.g., SOC 2, GDPR) aren’t publicly listed.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Cloud-native and scales well with your usage; integrates tightly with major warehouses. | Cost can escalate quickly due to vCore-hour billing and continuous instance usage. |
| Clean no-code UI, Easy for non-technical users to build complex ELT pipelines. | Lacks robust CDC support.Sschema changes often require manual pipeline updates. |
| Advanced enterprise features like access control, lineage, and versioning improve governance. | Connector ecosystem is modest in size (~150+); niche or custom sources may need custom work. |
| License includes unlimited users across plans. Cost-effective for growing teams. | Requires infrastructure uptime even when pipelines aren’t actively running. Can drive unnecessary usage costs. |
StreamSets
G2 / Capterra Rating
G2: Scores of 4.0 out of 5 from over 100 reviews.
Capterra: Scores 4.3 from 19 reviews.
StreamSets focuses on building resilient, real-time and batch data pipelines that can adapt to schema and infrastructure changes.
It provides strong observability and error-handling capabilities, making it popular for operational pipelines. StreamSets is typically used in complex, high-throughput environments rather than basic analytics use cases.
Best For
Enterprises needing a fully managed cloud platform capable of handling both batch and streaming data pipelines with robust transformation capabilities. Ideal for organizations integrating multiple SaaS and on-premises data sources that require scalable, real-time data processing.
Best suited for teams comfortable with Kubernetes or those willing to invest in learning it, as the platform operates on Kubernetes infrastructure. Not recommended for organizations seeking on-premises deployment options.
Key Features
- Drag‑and‑drop pipeline design for batch, streaming, ETL, ELT, and CDC workflows in a single interface.
- Built‑in processors for data transformation (masking, joins, lookups) and schema drift detection.
- Reusable pipeline fragments and Python SDK support for templating and scale.
- Unified control plane for monitoring, lineage, and operations across hybrid and cloud environments.
Pricing Deep Dive
StreamSets uses a custom pricing model, based on node or core usage:
- VPC-based pricing: e.g., $1,050 per virtual core per month.
- Packages:
- Departmental starting at ~$4,200/month (12–20 pipelines, 10k+ records/sec).
- Business units ~$25,200/month (72–120 pipelines, 60k+ records/sec).
- Enterprise typically starts around $105,000/month.
Note: There’s also a free open-source Data Collector edition; enterprise-only features, like monitoring or lineage, require additional licensing.
Security & Compliance
- Includes logging, monitoring, alerts, and built-in governance tools.
- Ideal for sensitive and regulated environments with workflow auditability and drift protection built in.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| Rich support for streaming, batch, CDC, and data drift. One platform handles all. | Pricing is opaque and high. Enterprise-only tiers are costly. |
| Visual design with code extensibility (Python SDK) helps build and scale efficiently. | Setup complexity. Especially containers, hybrid setup needs technical expertise. |
| Strong visibility via lineage, monitoring, and control plane across environments. | Less adoption among small teams. Performance at scale can depend on infrastructure care. |
Apache Spark
G2 / Capterra Rating
G2: Scores of 4.0 out of 5 from over 12 reviews.
Capterra: Scores 4.6 from 16 reviews.
Apache Spark is a distributed data processing engine designed for large-scale batch and streaming workloads.
Rather than being a complete integration tool, Spark serves as the computational backbone for custom pipelines built by engineering teams. It’s extremely powerful, but requires significant infrastructure management and development expertise.
Best For
Organizations and data teams with strong programming expertise looking for a powerful, flexible, and free open-source engine to build complex, real-time, and batch data pipelines.
Ideal for users who need multi-language support (Python, Scala, Java, R, SQL) and require deep customization for data transformation and exploratory data analysis on large datasets. Not suitable for teams without coding skills or those needing dedicated vendor support.
Key Features
- Lightning-fast, in-memory distributed processing, often tens to hundreds of times faster than traditional MapReduce frameworks.
- Unified platform supports batch and streaming, SQL querying (Spark SQL), machine learning (MLlib), and graph processing (GraphX).
- Native Spark UI for monitoring jobs, resource utilization, and performance tuning.
- Multi-language support: Scala, Java, Python (PySpark), R, SQL, giving developers and data scientists flexibility.
Pricing Deep Dive
Spark is fully open-source and free to use, but the costs lie in infrastructure and operational overhead:
- Requires clusters (on-prem or cloud), cluster management, and ongoing maintenance.
- You’re responsible for provisioning, scaling, patching, and monitoring the infrastructure.
Security & Compliance
- Supports encryption in transit and at rest, depending on the deployment setup.
- Integrates with enterprise authentication tools (LDAP, Kerberos, etc.) for secure access control.
Note: Spark does not offer built-in, fine-grained access control by default, which may require supplemental tools for secure, multi-tenant environments.
Strengths & Limitations
| Strengths | Limitations |
|---|---|
| High-performance computing for varied workloads (batch, streaming, ML, graph). | Requires significant infrastructure and technical expertise to deploy and maintain. |
| Unified platform supports diverse data processing patterns. | No native governance or fine-grained security. It needs external solutions. |
| Spark UI simplifies debugging and tuning in production. | Complex learning curve; code-heavy, not low-code . It can be hard for non-dev teams. |
Open-Source vs. Commercial Tools: Which is Right for You?
When you’re choosing a data pipeline tool, one of the biggest questions isn’t what features it has. It’s whether you want open-source flexibility or commercial polish. Both camps have their wins and trade-offs.
Open-Source (Airflow, Airbyte, Spark)
Pros
- Free to use. No license fees, just the infra costs.
- Customizable. Tweak the code, build custom connectors, own the stack.
- Strong community. Forums, GitHub, Slack groups buzzing with solutions and plugins.
Cons
- DIY overhead. You need engineers who know their way around clusters, configs, and logs.
- Self-hosting headaches. Upgrades, scaling, and uptime are on you.
- Support = forums. No SLA if something breaks at 2 a.m.
Commercial (Skyvia, Fivetran, Integrate.io, Matillion)
Pros
- Fully managed. No servers, no patches, no late-night pager duty.
- Ease of use. Clean UIs, no-code builders, fast setup.
- Dedicated support. Ticket systems, SLAs, sometimes even onboarding help.
Cons
- Subscription costs. You pay per row, per seat, or per credit, and it adds up.
- Less customization. You’re in their sandbox, not yours. If a connector doesn’t exist, you wait.
Practical How-To Guides
Reading about tools is one thing. Seeing how they actually work is another. In this section, we’ll walk through real-life scenarios step by step.
These quick guides show how different tools tackle common challenges. So you can picture what it would look like in your own stack.
Guide 1: Syncing Salesforce to QuickBooks in Minutes with Skyvia
Finance and sales don’t always see eye to eye, but their data should. Your sales team closes deals in Salesforce, while your finance team tracks invoices in QuickBooks. Without integration, someone’s stuck copy-pasting, or worse, double-entering data.
Here’s how you fix that with Skyvia:
- Log in to Skyvia → open the browser-based app.
- Choose your sources → Salesforce as the input, QuickBooks as the destination.
- Authenticate both systems → OAuth login, no drivers or local installs.
- Drag, drop, and map fields → align accounts, customers, and invoice details.
- Run or schedule the sync → Skyvia pushes Salesforce records straight into QuickBooks automatically.
Just like that, the sales orders flow seamlessly into invoices. No copy-paste, no errors, no angry emails between sales and finance.
Want to see it in action? Watch this quick demo.
Guide 2: Orchestrating a Workflow with Apache Airflow
Think of this as a quick, no-drama build: grab a simple API, clean the data, drop it in a database, and let Airflow babysit the schedule, retries, and logging. No hand-holding cron jobs, no mystery shell scripts.
Minimal local install that works on any laptop:
- Spin up Airflow (fast path)
pip install "apache-airflow==2.*"
airflow db init
airflow users create \
--username admin --password admin \
--firstname Admin --lastname User \
--role Admin --email admin@example.com
airflow webserver --port 8080 # Terminal 1
airflow scheduler # Terminal 2
Open http://localhost:8080 and log in. That’s your control tower.
Create dags/example_etl_pipeline.py. This is a clean, readable ETL: extract from a demo API → transform with pandas → load into SQLite (swap for Snowflake/BigQuery later).
- Drop a DAG into dags
Create dags/example_etl_pipeline.py. This is a clean, readable ETL: extract from a demo API → transform with pandas → load into SQLite (swap for Snowflake/BigQuery later).
from __future__ import annotations
from datetime import datetime, timedelta
import logging
import sqlite3
import requests
import pandas as pd
from airflow import DAG
from airflow.operators.python import PythonOperator
# Default behavior every task gets unless overridden
default_args = {
"owner": "data-eng",
"retries": 2,
"retry_delay": timedelta(minutes=3),
}
RAW_PATH = "/tmp/users_raw.csv"
CLEAN_PATH = "/tmp/users_clean.csv"
SQLITE_DB = "/tmp/example.db"
def extract():
url = "https://jsonplaceholder.typicode.com/users"
r = requests.get(url, timeout=15)
r.raise_for_status()
df = pd.DataFrame(r.json())
# Keep only what we care about for the demo
cols = ["id", "name", "username", "email", "phone", "website"]
df = df[cols]
df.to_csv(RAW_PATH, index=False)
logging.info("Extracted %d rows -> %s", len(df), RAW_PATH)
def transform():
df = pd.read_csv(RAW_PATH)
# Lightweight cleanup: upper-case usernames, normalize domain
df["username"] = df["username"].str.upper()
df["domain"] = df["email"].str.split("@").str[-1].str.lower()
# Basic data quality check
assert df["email"].notna().all(), "Found null emails after extract"
df.to_csv(CLEAN_PATH, index=False)
logging.info("Transformed %d rows -> %s", len(df), CLEAN_PATH)
def load():
df = pd.read_csv(CLEAN_PATH)
with sqlite3.connect(SQLITE_DB) as conn:
df.to_sql("users", conn, if_exists="replace", index=False)
logging.info("Loaded %d rows into SQLite table 'users' (%s)", len(df), SQLITE_DB)
with DAG(
dag_id="example_etl_pipeline",
description="Simple API -> pandas -> SQLite ETL orchestrated by Airflow",
default_args=default_args,
start_date=datetime(2025, 1, 1),
schedule_interval="@daily", # or "0 7 * * *" for 07:00 every day
catchup=False,
max_active_runs=1,
tags=["demo", "etl"],
) as dag:
extract_task = PythonOperator(task_id="extract", python_callable=extract)
transform_task = PythonOperator(task_id="transform", python_callable=transform)
load_task = PythonOperator(task_id="load", python_callable=load)
# The assembly line
extract_task >> transform_task >> load_task Why this shape works:
- Clear boundaries. Each step does one thing well.
- Idempotent-ish. Re-runs just overwrite /tmp artifacts and the SQLite table.
- Production-friendly. You can swap the load() for a warehouse operator with almost no rework.
- Turn it on and watch it run
- Save the file into your dags/ folder.
- In the UI, toggle the DAG On.
- Hit Play → Trigger DAG.
- Open each task’s Logs to see what happened. If the API blips, Airflow retries for you.
- Make it a little tougher (timeouts, SLAs, alerts)
These tweaks are what keep pagers quiet:
# In default_args above
default_args.update({
"execution_timeout": timedelta(minutes=10),
# Optional if you use SLAs and email config
# "email": ["data-oncall@company.com"],
# "email_on_failure": True,
# "sla": timedelta(minutes=15),
}) - Swap the demo bits for real infra
- Load to Postgres: use PostgresHook or SqlAlchemy (or PostgresOperator if you want pure SQL).
- Load to Snowflake/BigQuery/Redshift: install the provider package and use the native operator.
- Object storage: write your interim files to S3/GCS instead of /tmp.
A tiny example swapping SQLite for Postgres with psycopg2:
import psycopg2
from psycopg2.extras import execute_values
def load_to_postgres():
df = pd.read_csv(CLEAN_PATH)
rows = list(df.itertuples(index=False, name=None))
conn = psycopg2.connect(
host="localhost", dbname="analytics", user="airflow", password="airflow"
)
with conn, conn.cursor() as cur:
cur.execute("""CREATE TABLE IF NOT EXISTS users (
id INT PRIMARY KEY,
name TEXT,
username TEXT,
email TEXT,
phone TEXT,
website TEXT,
domain TEXT
)""")
execute_values(
cur,
"INSERT INTO users (id,name,username,email,phone,website,domain) VALUES %s "
"ON CONFLICT (id) DO UPDATE SET "
"name=EXCLUDED.name, username=EXCLUDED.username, email=EXCLUDED.email, "
"phone=EXCLUDED.phone, website=EXCLUDED.website, domain=EXCLUDED.domain",
rows,
)
Then point your load_task at load_to_postgres.
Optional: Same pipeline with Airflow’s TaskFlow API (cleaner, more “Pythonic”).
If you prefer decorators and native XCom passing (no temp files), this version keeps the data in memory and is easier to test:
from __future__ import annotations
from datetime import datetime, timedelta
from airflow import DAG
from airflow.decorators import task, dag
import requests, pandas as pd, sqlite3
@dag(
dag_id="example_etl_taskflow",
start_date=datetime(2025, 1, 1),
schedule_interval="@daily",
catchup=False,
default_args={"retries": 2, "retry_delay": timedelta(minutes=3)},
tags=["demo", "etl", "taskflow"],
)
def taskflow_etl():
@task
def extract():
r = requests.get("https://jsonplaceholder.typicode.com/users", timeout=15)
r.raise_for_status()
return r.json() # Sent to next task via XCom
@task
def transform(rows: list[dict]) -> list[dict]:
df = pd.DataFrame(rows)
df["username"] = df["username"].str.upper()
df["domain"] = df["email"].str.split("@").str[-1].str.lower()
return df.to_dict(orient="records")
@task
def load(rows: list[dict]):
df = pd.DataFrame(rows)
with sqlite3.connect("/tmp/example.db") as conn:
df.to_sql("users", conn, if_exists="replace", index=False)
load(transform(extract()))
taskflow_dag = taskflow_etl() Production notes that save headaches later
- Providers: install only what you need, e.g. apache-airflow-providers-amazon, …-google, …-snowflake.
- Connections/Secrets: store creds in Airflow Connections or a secrets backend (AWS Secrets Manager, HashiCorp Vault).
- Backfills: set a realistic start_date; enable catchup=True only when you’re ready to replay history.
- Observability: add max_active_runs, SLAs, and alerting; pipe logs to S3/Cloud Logging.
- Data quality: wire in checks (e.g., Great Expectations) as first-class tasks.
Real-World Use Cases & Case Studies
You can talk theory all day, but nothing beats seeing how this stuff plays out in the wild. Think of it like swapping stories on a park bench: “Here’s the problem we had, here’s what we tried, and here’s how such tools saved us from late nights and messy spreadsheets.”
The following case studies show real companies turning tangled data flows into smooth, reliable pipelines.
Use Case 1
Redmond Inc., an agri‑brand powerhouse managing stores for labels like Real Salt and Best Vinyl, had 1,000–3,000 orders per day coming into Shopify. Their ERP, Acumatica, tracked stock and resources, but syncing the two systems was a nightmare.
They needed Shopify orders flowing into Acumatica fast and stock updates from ERP pushing back to Shopify near real‑time. Manual scripts and delays? Not scalable.
The Skyvia Way
Skyvia served as the glue. It ingested Shopify data. Orders, payments, inventory, into a SQL Server staging area with incremental updates.
From there, it merged into Acumatica and fed Power BI dashboards for Customer Service to actually use. All seamless, with no custom dev drag.
What Changed
- Order syncing became reliable. No more missed or duplicate entries.
- Inventory accuracy soared. Staff could see what was live vs. out of stock near real‑time.
- Budgets were happier. They saved over $60,000 annually compared to building and maintaining custom logic.
Use Case 2
A global tech company was drowning in siloed marketing data. Paid ads lived in Google Ads and Facebook Ads, web analytics came from GA4, email engagement sat in HubSpot and Marketo, while CRM data stayed locked in Salesforce.
In total, 15+ SaaS apps each had a slice of the customer journey. Teams spent hours exporting CSVs, copy-pasting into spreadsheets, and fighting over “which number was right.” Scaling reporting across global regions? Nearly impossible.
The Fivetran Way
Fivetran stepped in as the central pipeline. With pre-built connectors, it pulled data from every SaaS app: ads, CRM, email, web, and landed it cleanly into Snowflake.
Schema drift? Automatically handled. New fields in the source? Synced automatically. Instead of babysitting scripts, the team could trust their pipelines.
What Changed
- One source of truth. All marketing and sales data in Snowflake, queryable in seconds.
- Enterprise analytics unlocked. Marketing ROI reports blended across channels, campaigns, and geographies.
- No maintenance overhead. Fivetran managed schema updates and API quirks behind the scenes.
- Productivity wins. Analysts stopped wrangling exports and started building dashboards that leadership actually used.
Use Case 3
A fast-growing SaaS startup needed more than dashboards. Their data science team wanted machine learning models to predict churn and upsell opportunities.
But the raw data was scattered: product usage sat in PostgreSQL, payments in Stripe, support tickets in Zendesk, and web traffic in Google Analytics. Copy-pasting into notebooks was fine at the seed stage, but now the team needed a pipeline that could scale with their growth.
The Open-Source Way
They turned to Airbyte for ingestion. With community-built connectors, Airbyte piped data from all their SaaS apps and databases into a central warehouse (BigQuery).
Once the data landed, dbt took over: transforming raw tables into clean, analytics-ready models with version-controlled SQL. This approach gave the team not just raw data, but curated datasets ready for training models and reporting.
What Changed
- Faster experimentation. Data scientists no longer wasted days on exports; datasets were fresh every morning.
- Trust in data. dbt tests caught issues before they hit dashboards or models.
- Cost efficiency. Open-source tools meant no steep licensing fees, and the pipeline scaled with their cloud infrastructure.
- Collaboration. Analysts and engineers could work in the same Git repo, reviewing SQL changes just like code.
The Future of Data Pipeline Technology
Data pipelines aren’t standing still either. Just like the city hums and shifts, pipelines are evolving fast. What worked yesterday, manual ETL jobs, nightly batch runs, won’t cut it tomorrow. Here’s where things are headed.
The Rise of Data Mesh Architecture
The old model was “all roads lead to one giant warehouse.” It worked, but it also created bottlenecks. Data mesh flips that idea: each domain (marketing, finance, ops) owns its own data as a product. Pipelines in this world don’t just feed a single hub.
They become the connective tissue across distributed data domains. The shift is cultural as much as technical: less about central gatekeepers, more about federated ownership with standards baked in.
AI-Powered Pipeline Monitoring and Automation
Logs and alerts are fine, but they don’t scale when you’re running hundreds of pipelines. That’s why AI is creeping in. Not to replace engineers, but to:
- Spot patterns.
- Predict failures.
- Auto-heal before anyone gets paged.
Imagine a system that learns your normal data volumes, notices a sudden drop at 2 AM, and reroutes or retries automatically. That’s where pipelines are headed: less babysitting, more self-driving.
The Convergence of Batch and Streaming (Hybrid Pipelines)
Once upon a time, you had to choose:
- Batch for reliability.
- Streaming for immediacy.
Now, the walls are blurring. Modern architectures let you process events in real time while still rolling them up into clean daily aggregates. That means you can power dashboards that update instantly and maintain the historical tables analysts rely on.
Hybrid pipelines are the sweet spot. You don’t compromise, you combine.
Conclusion
Choosing a data pipeline tool is a lot like picking the right bike for a city ride. Some are built for speed, some for cargo, some for comfort.
If you grab the wrong one, you’ll still get from A to B, but it’ll be bumpy, costly, and you’ll wish you had something better suited to the path.
The big takeaway? Match the tool to your needs.
- If your team is small and doesn’t live in Python, a no-code platform saves sanity.
- If you’re running enterprise-scale workloads, you need something that scales without creaking.
- If compliance and security keep you up at night, look for SOC 2, GDPR, HIPAA-level guarantees.
- And always keep the budget in mind: tools that look cheap upfront can rack up costs later.
That’s where Skyvia finds its sweet spot. It’s like the commuter bike with a basket and gears: practical, reliable, secure, and not outrageously priced. You don’t need a Tour de France racing rig or a cargo trike the size of a car.
You need something balanced, powerful enough for the daily grind, and easy for anyone on the team to ride.

