Data lakes are common for centralized storage of large amounts of data in its native format. According to Fortune Business Insights, large enterprises hold a dominant share of the global data lake market since they typically manage big data. However, small businesses have also started discovering the benefits of data lakes, which help them identify trends out of data and enhance customer service.
Contrary to the popular belief that all data lakes are hosted in the cloud, many companies also prefer on-premises data lakes. Another myth is associated with the high costs of data lakes, which is not true. In this article, you will discover other curious things about data lakes and see which solutions will help you create one for your company.
Table of Contents
- What Is a Data Lake?
- Popular Data Lake Tools
- Data Integration with Skyvia
- How to Choose a Data Lake Tool?
- Conclusion
What Is a Data Lake?
“A data lake is a low-cost storage environment, which typically houses petabytes of raw data.” – IBM
“A data lake is a place to store structured and unstructured data, as well as a method for organizing large volumes of heterogeneous data from diverse sources.” – Oracle
We’d stick rather to the second definition as it emphasizes the dual purpose of a data lake. It’s not only a centralized repository for storing unstructured, semi-structured, and unstructured data but an approach to data management.
According to Fortune Business Insights, data lakes are widely used in banking and finance (21%), IT and telecom (24%), retail and e-commerce (20%), healthcare and life sciences (18%), and in other industries. Data lakes make up a solid basis for data-intensive tasks, such as real-time analytics and machine learning.
It’s possible to implement a data lake either in the cloud or on-premises. The latter choice provides better control over data, so it’s widespread among financial and healthcare institutions. However, note that data lake tables aren’t transactional; they show either success or failure results and cannot roll back operations.
In this article, we will also discuss data lakehouses, a solution that combines the best of two worlds – data warehouses and data lakes. It also overcomes the challenges of these two systems since it supports unstructured data, which is unavailable in data warehouses, and transaction management, which is restricted in a data lake.
What Value Does a Data Lake Bring?
Many organizations have already shifted to data lakes, while others are on their way to implementing them. Such popularity isn’t occasional since data lakes bring value to companies. Here are some of their key benefits:
- Data consolidation. Data is collected from multiple sources in various formats and amounts with the data aggregation tools. That way, data storage is centralized, which makes it easier to manage and govern.
- Regulatory compliance. Centralized management enables admins to set up role-based access, which strengthens overall data security.
- Advanced analytics. With data lakes, you can perform complex analytical operations without the need to move data to a dedicated analytics system.
- Machine learning. It’s easy to build machine learning models using a pile of data in its original format.
- IoT data support. Data lakes also can accept data from high-speed data streams.
Data Lake Architecture
As mentioned above, data lake is about storage, but it’s not just a repository but a number of connected tools empowering centralized data management. The architecture of each data lake may vary slightly from one company to another. Anyway, the typical scheme of a data lake looks something like this:
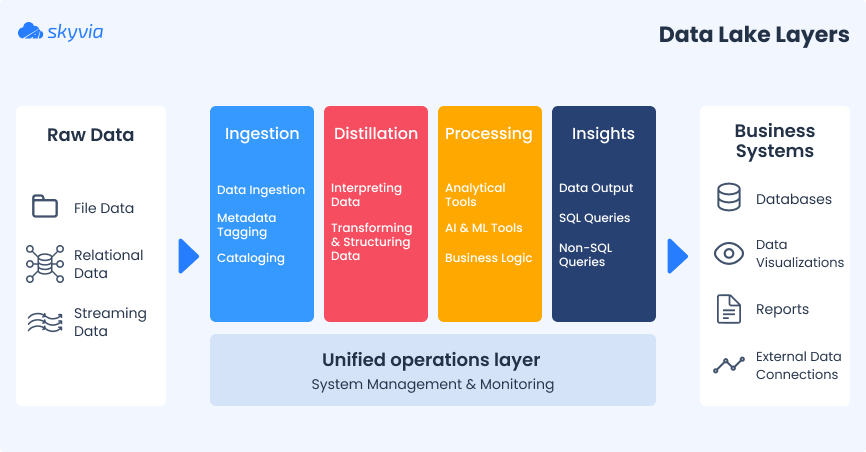
| Layer | Description |
|---|---|
| Data ingestion layer | Initially, data is gathered from various sources and sent to the central repository in its raw format. Data ingestion tools can help with collecting data at this stage. |
| Distillation layer | At this point, it’s necessary to convert unstructured data to a structured format to be used for analytical purposes. |
| Data processing layer | With the help of query tools, users can execute queries on structured data. Analytical applications also run at this layer and consume the structured data. |
| Insights layer | This tier acts as an output interface of a data lake. SQL and NoSQL queries are used to fetch data. The results are usually provided in the form of dashboards and reports. |
| Unified Operations layer | This layer is designed for system monitoring. |
Popular Data Lake Tools
Amazon S3
There are 1000+ data lakes already running on AWS. Amazon S3 is a decent storage solution for your data lake foundation, thanks to its availability, scalability, durability, security, and compliance.
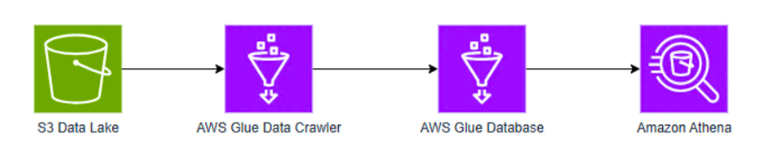
With AWS, you can create a data lake rather fast and then use AWS Glue to move data to such analytics services as AWS Athena. It allows you to perform advanced analytics tasks, streaming analytics, BI operations, machine learning, and other data-demanding operations.
There is a popular question of whether Redshift can be a basis for data lakes as well. Get to know the differences between AWS Redshift and S3 and discover why the latter is a better choice.
| Pros | Cons |
|---|---|
| – Encryption and security. – High scalability. – Ease of use. – A diverse set of tools. | – Confusing billing. – AWS limits resources based on location. – The interface is a bit laggy. |
Google Cloud Storage

Google Cloud Storage is a service designed to store mostly unstructured data, including video, audio, media files, etc. Obviously, it makes the first layer of a data lake. So, other Google Cloud services are needed to build a data lake and extract value out of data.
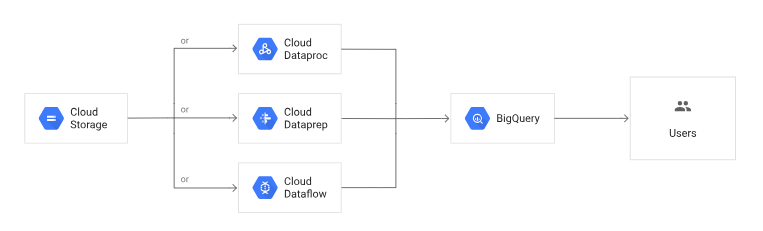
Depending on your analytics needs, use Google Cloud Dataprep or Dataflow for the distillation layer. Dataflow is a service for batch and stream data processing, while Dataprep is a service for data exploration, cleansing, and preparation. Then, preprocessed data can be loaded into BigQuery for analysis or SQL queries can be used to fetch data from large datasets.
| Pros | Cons |
|---|---|
| – Excellent documentation and detailed API reference guides. – Affordable prices for different storage classes. – Easy to integrate with other Google Cloud services. | – Costly support service. – Complex pricing scheme. |
Snowflake
Snowflake allows users to bring together structured, semi-structured, and unstructured data in their Data Cloud. With its Elastic Performance Engine, different users can run independent jobs on the same data. This feature powers up data science, analytics, and application creation without the need to manage the underlying infrastructure.
Snowflake relies on state-of-the-art compression algorithms to reduce the amount of data stored, which directly leads to cost savings. It also simplifies data governance by managing privileges with the RBAC (role-based access control) mechanism.
| Pros | Cons |
|---|---|
| – Decoupled architecture of Storage and Compute. – Centralized data security. – Integration with many apps and services. | – Vague pricing model. – Limited support of unstructured data. – Graphical interface for app development. |
Azure Data Lake
Azure Data Lake is a solution for organizations that want to take advantage of big data. It helps data scientists and analytics professionals to extract value from large amounts of data. Azure Data Lake supports multiple popular programming languages and integrates with other data lakes and data warehouses.
Azure Data Lake consists of three main components:
- Storage makes a base for a secure data lake platform.
- Analytics allows users to run massively parallel processing (MPP) and transformation tasks on petabytes of data.
- HDInsight cluster deploys Apache Hadoop on the Microsoft platform so that users can optimize analytics clusters for Apache Spark, Kafka, Storm, and other tools working with data streams.
| Pros | Cons |
|---|---|
| – Cost-efficient – Enhanced data security – Integration with other Microsoft and open-source products | – Setup complexity that requires strong technical proficiency – Slower performance compared to other data lakes |
Databricks

Databricks is a data intelligence platform suitable for building lakehouses. It allows companies to craft lakehouses containing the following key components:
- Delta Lake is a storage layer that also brings ACID guarantees to transaction data.
- Apache Spark is the module for data transformation and preparation for complex analytical tasks.
- Photon is an engine for data query acceleration, especially when addressing large datasets.
- Databricks SQL is an analytics engine for interactive query and reporting.
- Integrated data science tools are integrated for building, training, and deploying machine learning models. In particular, TensorFlow, PyTorch, and scikit-learn libraries are available within Databricks.
All together, these tools create a comprehensive ecosystem for data ingestion, storage, processing, and analysis.
| Pros | Cons |
|---|---|
| – Support of ACID transactions – Fast data processing – End-to-end ML support | – High cost – Vendor lock-in |
Dremio
Dremio is a lakehouse platform designed for self-service analytics and AI. Data analysts can use it to visualize and explore data, enjoying low response times. Data engineering can ingest and transform data directly in a data lake, enjoying the full support of DML operations.

A huge advantage of Dremio is that it works both with cloud and on-premises data. Dremio uses open-source Apache Arrow, proprietary Columnar Cloud Cache (C3), and Reflection Query Acceleration technologies, which makes it a fast query engine.
| Pros | Cons |
|---|---|
| – Simplified data management – 50% lower TCO compared to other lakehouse solutions – High-performing SQL query engine | – Doesn’t connect to legacy data sources – Limited documentation and support |
Data Integration with Skyvia
Skyvia is not a data lake or a data lakehouse, but it can assist companies with populating data lake storage with data. It’s a universal cloud platform designed for multiple data-related tasks, such as data integration, data query, SaaS backup, workflow automation, etc.

Skyvia’s Data Integration product has everything needed to populate data lakes with analysis-ready data with the following tools:
- Import is the ETL-based tool for ingesting data from cloud apps, data warehouses, and databases. It also allows users to perform filtering and transformation operations on data.
- Replication is the ELT-based tool for copying data from cloud apps into data warehouses and databases.
- Data Flow allows users to build more complex data pipelines, including several sources, and apply multistage data transformations.
- Control Flow creates logic for task execution, performs preparatory and post-integration activities, and configures automatic error processing logic.
| Pros | Cons |
|---|---|
| – Intuitive user interface – Integration with 200+ data sources – Powerful data transformations – Flexible pricing model | – Unclear error messages – No unstructured data support |
Overall, Skyvia could be a good solution for capturing data from different sources and moving it into supported data lakes.
How to Choose a Data Lake Tool?
Choosing the right tools for building your data lake is not that difficult. Just pay attention to several factors:
- Integration capabilities. Perform an audit of your existing infrastructure and see whether it integrates well with a data lake tool. For instance, if you have many processes running over the Google Cloud infrastructure, then Google products could be a good choice.
- Features. Explore the functionality of data lake tools and decide whether they can help to accomplish your business objectives.
- Explore querying and analytical capabilities. Each data lake has a processing layer where queries and analytics take place. Some tools offer faster queries, while others can’t boast high performance. It’s up to you to decide which option to prefer, depending on the required analytics speed.
- Price. Well, estimating data lake tool price is challenging since it depends on the data storage amounts and processing times. However, each cloud service provider has a price calculator, allowing you to estimate a data lake cost. That way, you can get an idea of the approximate spending on a data lake and compare it to the allocated budget.
- Metadata management. Since metadata is crucial for understanding and organizing data within a data lake, check whether a specific tool ensures effective metadata management.
Here is a comparison table for data lake tools, which may help you make the right choice.
| Data lake tool | Rating | Pros | Cons |
|---|---|---|---|
| Amazon S3 | 4.6 / 5 | – Encryption and security – High scalability – Ease of use – Diverse set of tools | – Confusing billing – AWS limits resources based on location – Interface is a bit laggy |
| Google Cloud Storage | 4.6 / 5 | – Excellent documentation and detailed API reference guides – Affordable prices for different storage classes – Easy to integrate with other Google Cloud services | – Costly support service – Complex pricing scheme |
| Snowflake | 4.5 / 5 | – Decoupled architecture of Storage and Compute – Centralized data security – Integration with many apps and services | – Vague pricing model – Limited support of unstructured data – Graphical interface for app development |
| Azure Data Lake | 4.5 / 5 | – Cost-efficient – Enhanced data security – Integration with other Microsoft and open-source products | – Setup complexity that requires strong technical proficiency – Slower performance compared to other data lakes |
| Databricks | 4.6 / 5 | – Support of ACID transactions – Fast data processing – End-to-end ML support | – High cost – Vendor lock-in |
| Dremio | 4.6 / 5 | – Simplified data management – 50% lower TCO compared to other lakehouse solutions – High-performing SQL query engine | – Doesn’t connect to legacy data sources – Limited documentation and support |
Conclusion
The compound architecture of a data lake contains not only storage but also querying and analytical modules. Its advanced version, a data lakehouse, even supports ACID transactions and embeds smart modules for analytics.
Modern cloud service providers can help build a well-performing data lake. Azure, Amazon, and Google offer a combination of tools for constructing a data lake, which helps to extract value from your data and perform advanced analytics. Databricks and Dremio can extend data lake functionality even further. Regardless of the chosen data lake, Skyvia can help you fill it with data from multiple sources.