

You know that sinking feeling when someone asks for “just a quick report” from a MySQL database, and you suddenly realize that “quick” is not a good word choice? By integrating MySQL with Google BigQuery, you can easily manage these requests without awkward explanations about processing time.
Let’s admit it from the beginning: combining structured storage with powerful analytics won’t give businesses a clairvoyant vision. Still, it does provide the data-driven edge so badly needed to stay ahead of the competition if you handle the migration, and we’re here to ensure that you do.
This guide cuts through this with three proven integration methods, ranging from the tried-and-true to the cutting-edge, each accompanied by clear instructions. Let’s go!
Table of Contents
- Understanding the Core Concepts: Before You Begin
- Planning Your Migration: Key Considerations Before You Start
- Method 1: The Manual Approach – Dump & Load with
mysqldump - Method 2: The Google Cloud Native Way – BigQuery Data Transfer Service
- Method 3: The Modern Approach – Real-Time Sync with CDC
- Comparison: Which Integration Method is Right for You?
- Troubleshooting Common Integration Issues
- Post-Migration Best Practices: Monitoring and Optimization
- Conclusion
Understanding the Core Concepts: Before You Begin
Your operational data lives in one world – MySQL, while unlimited analytic power awaits in another – BigQuery. So, we need a bridge. The construction must be solid to withstand the heavy flow and wide enough to process the traffic.
We will lay the foundation in a bit, but let’s start by nailing down the essentials.
What is an ETL/ELT Pipeline?
An ETL pipeline is a three-step data movement process: extracts data from MySQL, transforms it (cleans, reorganizes, and prepares it for the new analytical home), and then loads it into BigQuery.

ELT pipeline works differently – it dumps raw data straight into BigQuery first, then transformations are the warehouse’s responsibility. Why? The main reason is speed. Unprocessed records load faster, and BigQuery is generally better suited for data transformation compared to MySQL.

What is Change Data Capture (CDC)?

CDC can be of different types, but in the context of MySQL to BigQuery integration, where we want to reach near-real-time synchronization, we need the type that uses timestamp or autoincrement columns in MySQL tables to detect changes.
It only captures what changed since the last load. Instead of full table scans that make servers wheeze, it tracks updates through:
- Transaction logs
- Timestamps
- Database triggers
The result is fresh data with minimal database impact. It’s the difference between daily newspaper delivery and breaking news alerts on your phone.
We will discuss the importance of CDC in the context of MySQL with Google BigQuery integration further below.
Data You Can Migrate
Not everything you store in MySQL can easily find its way to BigQuery. Here’s what components move into BigQuery easily, which ones need a makeover beforehand, and which ones can’t enter at all:
| MySQL component | Transferability | Comment |
|---|---|---|
| Data rows | Yes | |
| Data types | Yes | Some data types require transformation; see the Troubleshooting Common Integration Issues section for more information |
| Table schemas | Yes | |
| Indexes | No | MySQL indexes are not applicable in BigQuery |
| Stored procedures | No | Cannot be directly migrated; requires re-implementation using BigQuery’s SQL syntax |
| User-defined functions | No | Must be rewritten with BigQuery’s SQL syntax |
| Triggers | No | BigQuery does not support triggers |
| Views | Yes | |
| Transactional logic | No | Needs redesign within BigQuery |
| User Permissions | No | Appropriate access controls should be set up in BigQuery |

Planning Your Migration: Key Considerations Before You Start
The worst kinds of surprises are those involving compromised tables or security lapses. Therefore, it’s a good practice to consider a planning phase as a pre-flight checklist to avoid it. Skip one checkbox, and you may have to explain to your supervisor why client orders don’t appear in the quarterly reports.
A. Security & Prerequisites

The foundation of everything:
- GCP Project Setup: Enable BigQuery and Data Transfer APIs – a digital passport for the journey ahead.
- IAM Roles & Service Accounts: Configure least-privilege access (because not everyone needs the keys to every door).
- Network Security: Set up firewall rules for MySQL IP addresses and position VPC Service Controls.
- Data Encryption: Make sure SSL/TLS protects data in transit; BigQuery handles at-rest encryption automatically – part of the task is complete.
- SSL encryption is non-negotiable. Without it, transferring data is like sending postcards with your bank details written in Sharpie. For GCP Cloud SQL users, enforce SSL connections through instance settings.
BigQuery IAM holy grail guidelines:
- Never make datasets publicly accessible.
- Avoid
allUsersorallAuthenticatedUsersroles. - Read-only users and write-access users should always go separately.
- Use row-level security to prevent unauthorized data peeping.
ETL tool security checklist:
- Verify encryption practices (both at rest and in transit).
- Guarantee compliance with the organizational security policies.
- Manage credentials securely.
B. Handling Schema and Data Type Differences
MySQL and BigQuery speak different dialects, but it’s possible to make them understand each other perfectly through a proper schema and matching data types.
Before you migrate anything, audit your MySQL architecture:
- Schema inventory: Document all tables, columns, and relationships.
- UDF detection: Identify User Defined Functions that won’t survive the journey.
- Stored procedure assessment: BigQuery and MySQL’s stored procedures don’t get along.
Critical mapping considerations:
| MySQL Data Type | BigQuery Equivalent | Transformation & Notes |
|---|---|---|
| TINYINT(1) | BOOLEAN | Direct conversion |
| DATETIME | TIMESTAMP | Critical: Must handle time zone conversion; BigQuery stores in UTC |
| DECIMAL | NUMERIC, BIGNUMERIC | Match precision and scale carefully |
| TEXT, BLOB | STRING, BYTES | Check for size limits in BigQuery |
| ENUM, SET | STRING | Transform into a string or an array of strings |
| JSON | JSON | Natively supported, generally smooth transfer |
Schema evolution challenges:
- Be cautious when adding/dropping columns, as this can disrupt ETL pipelines.
- Build sturdy pipelines with schema validation and error handling.
- Choose sync tools that support graceful schema evolution.
Design for analytics, not transactions. The BigQuery schema should be optimized for analytical workloads, rather than the OLTP (Online Transaction Processing) patterns that MySQL is designed for.
Pro tip: Test your mappings with sample data before going full-scale. It’s better to catch conversion issues with 100 rows than 100 million.
C. Strategies for Migrating Logic
Your stored procedures, triggers, and UDFs have been inmates for a long time. But now it’s time to spring them loose and give them a new life in BigQuery – though they’ll need some serious rehabilitation first.
- The great procedure breakout
Start by rewriting them using CREATE PROCEDURE with BigQuery’s scripting syntax. Split them into smaller, focused chunks that make sense.
Pro tip: Ditch the row-by-row thinking. BigQuery loves set-based operations, so teach your old procedures some new tricks by using bulk processing instead.
- UDF witness protection program
Your user-defined functions need new identities in the form of CREATE FUNCTION statements. Most scalar functions can slip into SQL or JavaScript disguises pretty easily. For the stubborn ones that refuse to cooperate, set up remote functions that phone home to Cloud Functions.
- Trigger trouble
Bad news: BigQuery doesn’t want triggers. They’re persona non grata in this new world. But don’t panic – you can still pull their strings using Cloud Functions triggered by audit logs or Pub/Sub messages that jump into action when your data gets poked and prodded.
- The rehabilitation plan
Start by cataloging your current inmates – er, logic components. Figure out what is critical to operations and what is just taking up space. Then begin the transformation: break down complex procedures into bite-sized chunks, use BigQuery’s analytical superpowers, and remember that sometimes the best migration strategy is knowing when to call in backup through remote functions.
Method 1: The Manual Approach – Dump & Load with mysqldump
It’s the time-tested ritual of MySQL data migration, which involves exporting records from MySQL using mysqldump, uploading them to Google Cloud Storage (GCS), and then importing them into BigQuery. It completely drops and replaces existing BigQuery tables. No incremental updates, no gentle merging, just good old-fashioned “out with the old, in with the new.”
Best For
- One-time data migrations: Shifting that dusty archive data from 2018 that’s been sitting in storage like vintage wine.
- Foundation-laying transfers: Establish core datasets in BigQuery, reserving advanced real-time implementations for later.
- Boutique-scale projects: Perfect when you’re managing a cozy collection of tables, but can’t handle enterprise-sized data monsters.
- Disaster recovery scenarios: Simple backup missions when you need a dependable safety net without the complexity.
- Lean engineering teams: When dev resources are stretched thin and you need something that just works.
Spoiler alert: If you want real-time insights, regular updates, or constant synchronization, using mysqldump to integrate MySQL with Google BigQuery will make you feel as though you are lacking something. It’s also not your best friend forever for production environments that require always-fresh data.
- Set up the Google Cloud Platform (GCP) environment:
- Create a Google Cloud account.
- Enable BigQuery Service: within your GCP project, ensure that the BigQuery API is enabled.
- Install the Google Cloud SDK, the toolkit for interacting with GCP services.
- After installation, run
gcloud initto configure the SDK with your GCP account and set the default project.
- Export data from MySQL:
- Use the
mysqldumpcommand to export MySQL databases or tables. To export a specific table:
mysqldump -u [username] -p [password] -h [hostname] [database] [table_name] > [table_name].sql Replace the placeholders in [ ] brackets with your MySQL credentials and the specific table you wish to export.
- Upload data to GCS:
- In the GCP Console, create a new bucket in GCS to hold your files.
- Upload your files to a newly created bucket using the
gsutilcommand-line tool:
gsutil cp [table_name].csv gs://your-bucket-name/ - Create a new dataset in BigQuery:
- Using the
bqutility, run the command:
bq mk [dataset_name]- Import data into BigQuery:
- Define the table schema: BigQuery requires a schema definition for the data. Create a JSON file (schema.json) that describes the structure of your table. For example:
[
{"name": "column1", "type": "STRING"},
{"name": "column2", "type": "INTEGER"},
{"name": "column3", "type": "FLOAT"}
]Adjust the column names and types to match your records.
- Use the
bqtool to load data from GCS into BigQuery:
bq load --source_format=CSV [dataset_name].[table_name] gs://[your_bucket_name]/[table_name].csv schema.jsonEnsure that the source_format matches the format of your file (e.g., CSV).
Optimizing for Large Datasets
Got a massive dataset? Don’t worry, with the right tweaks, you still can make mysqldump perform.
- Ditch full dumps for incremental exports using
updated_atcolumns or timestamps, and export only what’s changed since the last run. Your network bandwidth will be amazed and amused. - Split large tables by date ranges or primary key chunks and run multiple mysqldump processes in parallel. Then, load these smaller pieces concurrently into BigQuery.
- Gzip those dump files before transfer (BigQuery likes compressed sources). Additionally, it reduces storage costs and network traffic, which is definitely a win if large datasets are your only reality.
- Use explicit schema files instead of letting BigQuery guess because auto-detection is slower than a dial-up connection and twice as unreliable. Validate schema compatibility regularly (especially after MySQL changes).
- Apply smart loading tactics, e.g., use BigQuery options:
--replace,--append, or--schema_update_option. Batch your load jobs to minimize overhead and skip the manual table recreation dance. - Use cloud Storage as your staging area: dump locally → compress → upload to Cloud Storage → load to BigQuery. This move decouples operations for better retry logic and parallel execution.
- Export without the drama. Use MySQL replicas or read-only instances (keep production happy). Deploy
--single-transactionand--quickoptions to reduce locking. - Load incremental data into staging tables first and use SQL upserts to merge into main tables. That maintains data consistency without the headache of duplicates.
Spoiler alert: Even optimized, mysqldump won’t win any speed contests against purpose-built replication tools. But for periodic large transfers where you control the schedule, these techniques transform it from painful to perfectly adequate.
Method 2: The Google Cloud Native Way – BigQuery Data Transfer Service
This fully managed Google Cloud service is designed to shuttle information from various sources straight into BigQuery. Basically, it’s the “set it and forget it” solution. You simply create transfer jobs, set a schedule, and watch as data flows into your BigQuery tables with clockwork precision.
Best For
- Scheduled, recurring batch transfers for users heavily invested in the GCP ecosystem. If you’re already living in Google’s cloud neighborhood, this is your golden ticket.
- Automating routine data refreshes for keeping analytics dashboards fed and reports looking fresh without manual interventions.
- Multi-platform data consolidation between different cloud kingdoms and SaaS applications.
- Reducing engineering overhead to free up resources for other tasks.
Step-by-Step Guide
Time to get your hands dirty with Google’s own transfer wizard. However, before you start, ensure you have the required roles to set up transfer run notifications for Pub/Sub –pubsub.topics.setIam Policy Identity and Access Management (IAM) permission. Also, bigquery.transfers.update and bigquery.datasets.get permissions are required to create a MySQL data transfer.

- Head to the Data transfers page in the GCP console and hit the Create transfer button.
- In the Source type dropdown, select MySQL because that’s why we’re here, right?
- Give the transfer a memorable name in the Display name field for easier identification in case you need to modify it later.
- Schedule data rendezvous:
- In the Schedule options section, pick the repeat frequency: Hours, Days, Weeks, or Months (Daily is the crowd favorite). You can go Custom for specific scheduling needs. And if you need everything right now, choose On-demand for manual triggers only.
- Set the launch time depending on when you need the transfer to take place: start now, immediate gratification seekers, this one’s for you; start at a set time: plan a transfer like a rocket launch with a specific date and time.
- Destination decision time:
- In the Destination settings, select the existing BigQuery dataset. No dataset? Click Create new dataset and build one on the spot to use as the destination dataset.
- Network setup first:
- In the Data source details, match/choose the following properties.
| Details | Properties |
|---|---|
| Network attachment | Choose an existing one or create a new one |
| Host | Your MySQL server’s hostname or IP address (no typos allowed here) |
| Port number | Your MySQL database server’s port number |
| Database name | The exact database you’re targeting (case sensitivity matters) |
| Username | Your MySQL user (make sure it has the right permissions) |
| Password | That securely stored, corresponding password |
| Encryption mode | Choose Full for complete SSL validation (recommended) or Disable if you’re living dangerously |
| MySQL objects to transfer | To choose which MySQL tables are needed for the transfer, click Browse. Then, click Select or Enter the table names by hand in the MySQL objects that need to be transferred |
Selection tip: You can get several tables at once, but keep in mind the network’s patience and transfer constraints.
- You have the option to activate Pub/Sub notifications for automated alerts (choose an existing subject or create a new one) or to set Email notifications ON if you would want transfer failure warnings to appear in your email.
- Go over all the options again, press Save, and see the magic take place.
Google then assumes control, verifies the connection, and initiates the migration in accordance with the timetable. Transfer runs will show up in the console along with logs and progress updates.
Limitations
BigQuery Data Transfer Service, like any specialized tool, comes with its own set of trade-offs worth understanding before committing:
- Batch service only, not real-time CDC.
- One-way street into BigQuery.
- Limited transformation capabilities. Raw data ingestion is the name of the game; heavy lifting happens after landing
- Some connections might require custom solutions or third-party tools
- Data transfer volumes, API usage, and storage can add up costs fast.
Method 3: The Modern Approach – Real-Time Sync with CDC
Welcome to the royal court of data integration, where Change Data Capture transforms how we think about moving data from MySQL to BigQuery.
A. Understanding Change Data Capture (CDC)
It captures the holy trinity of database operations: inserts, updates, and deletes, all in near real-time, focusing only on what’s actually changed. New customer signup? Captured. Price update on that bestselling product? Got it. Deleted spam account? Noted and forwarded. Your pipelines weigh less now and move graciously.
CDC works with MySQL by reading its binary log without disturbing the primary database operations. The binlog approach is brilliant in its simplicity. Rather than pestering a database with constant “How are you doing?” queries, CDC tools just tap into this existing stream of information. They read incrementally, parse the events to reconstruct exactly what changed, and then stream those changes to BigQuery.
The important thing about CDC is that it doesn’t just compete with traditional batch processing. It absolutely demolishes it in three key areas:

B. Implementing CDC with a No-Code Platform
While the manual methods discussed above provide greater control over exported data, they can be resource-intensive and require technical expertise. In contrast, the next method – integrating MySQL and BigQuery using Skyvia, a cloud data integration platform that offers diverse functionality, making it a one-stop solution for all data operations.
Step 1. Create Connections
First, let’s establish a connection to MySQL.
- Sign in to Skyvia, or, if you don’t have an account yet, create one for free.
- Click +Create New, select Connection, and choose MySQL.

Note: Skyvia supports two connection methods for MySQL: direct and with an agent. Use a direct connection if the MySQL server is accessible via the internet. If it is on a local computer or network, you’ll need to install the Skyvia Agent application to make a secure connection. For this case, we’ll create a direct connection.
- Provide MySQL credentials: server address, port, user ID, password, and database name.
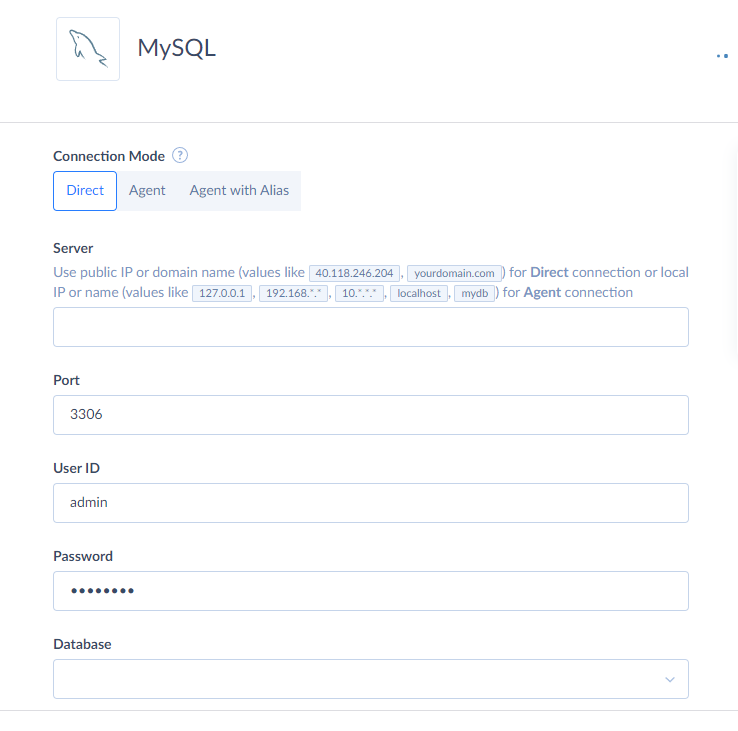
- Click Create Connection.
Сonnecting Skyvia to BigQuery involves the same steps as with MySQL:
- In Skyvia, go to Connections and click +Create New.
- On the Select Connector page, choose BigQuery.
- Select the preferred authentication method.
Note: Skyvia supports two authentication methods for Google BigQuery: OAuth authentication (User Account) and Service Account authentication. When using OAuth authentication, you sign in with your Google account without sharing your credentials with Skyvia. Instead, Skyvia uses OAuth 2.0 to generate a secure token, which is bound to the connection. For Service Account authentication, you need to provide the Private Key JSON.
- Enter your BigQuery credentials: Project ID and DataSet ID to connect to. You can retrieve these in the Google API console.
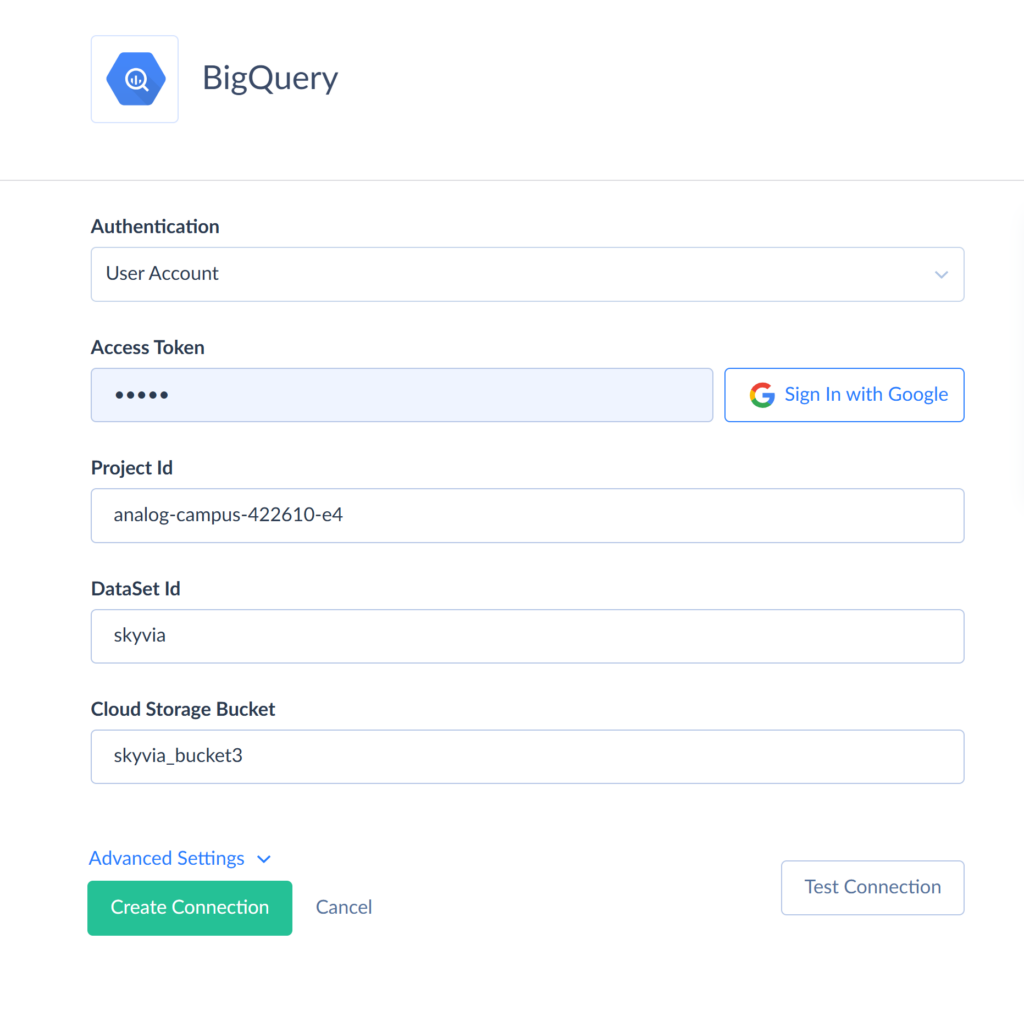
- Enter the Project ID. You can find it in the Google API Console. Go to the Navigation menu, select BigQuery, and click BigQuery Studio. Expand the Project node and choose the required dataset, and open the Dataset Info. Here you can find and copy the Dataset ID.
Note: Dataset ID contains a Project ID as a prefix. For the Connection parameter, use the ID without a prefix.

- Specify a Google Cloud Storage Bucket (optional unless you are planning for bulk import and replication operations).
- Click Create Connection.
Step 2. Create a Replication
Once both connections are ready, let’s implement a scenario of moving MySQL records to BigQuery. Let’s say you use MySQL as a database layer to store and manage customer details from an online shop. We will create a copy of the MySQL database in BigQuery, replication tables with customer and order information as an example.
- In the top menu, click +Create New and select Replication.

- Set the corresponding source (MySQL) and target (BigQuery).
- Configure the following replication options to make CDC happen:

Skyvia offers different options for Replication, so the result is tightly aligned with the main goal. For when you want to enjoy CDC benefits, check these boxes:
- Incremental Updates for tracking metadata changes and updating data without fully replicating a dataset or reloading its data.
- Ingestion Mode defines how to track changes in the source during the incremental update, provided that the replication source is a database.
- Once everything on the left is set, it’s time to choose the objects for Replication from the table on your right. Select all by ticking the relevant checkbox or specific ones.
- By default, Skyvia replicates all fields of selected objects. If you need to specify, click on the Pen icon that appears after selecting the needed objects to open the Task Editor; however, this is only possible if the Incremental Updates option is enabled on the main configuration page.
- In the Task Editor, ensure the Standard mode is selected. This way, only changed data is replicated, which is a key requirement in CDC.

- Additionally, you can hash sensitive fields, such as customers’ emails.
- Once all the parameters are set, click Save task and return to the main configuration page of this replication. Then, press Save in the upper-right corner.
- To automate the Replication, click Schedule and configure the timing.

- You can track its progress in the Monitor or Logs tabs. If errors occur, click the run results to review the failed records.
Note: Advanced scenarios call for Data Flow and Control Flow tools that offer intuitive design interfaces for developing comprehensive data networks. They enable the use of multiple connectors within a single integration, supporting process automation with personalized logic, complex transformation sequences, data consolidation from various sources, and simultaneous distribution to multiple endpoints.

Comparison: Which Integration Method is Right for You?
Three contenders enter the MySQL-to-BigQuery bar, each with their own personality quirks and hidden talents. The bartender takes one look at this motley crew and starts sizing them up:
| Feature | Manual (mysqldump) | BigQuery DTS | Real-Time CDC (Skyvia) |
|---|---|---|---|
| Technical Skill | High (requires SQL command line, scripting) | Medium (Google Cloud Console/UI usage) | Low (no-code UI) |
| Real-Time Data | No (batch dumps/loads only) | No (scheduled batch) | Yes (near real-time incremental sync) |
| Handling Large Datasets | Requires manual optimization (splitting, compression) | Managed by service, but can be slower for large datasets | Optimized for streaming and incremental changes |
| Schema Change Handling | Brittle, prone to breaking with schema changes | Mostly automated, but possible failures on complex changes | Automated with alerts and schema evolution support |
| Maintenance Overhead | High (custom scripting, error fixes) | Low (managed service with monitoring) | Very low (automated incremental pipelines, monitoring) |
| Cost | “Free” but high engineering time (hidden cost) | GCP usage-based | Predictable subscription |
We would like to pause for a moment to discuss TCO (Total Cost of Ownership), as even though migration methods are free, there are subscription costs that can’t be avoided. Here’s what to be aware of:
- MySQL Community Edition is free, but then there are Standard Edition – $2,140 per server per year for 1-4 socket servers, Enterprise Edition is $5,350 per server per year, and editions like Cluster Carrier Grade for larger setups can cost up to $10,700+ per server per year or more.
- BigQuery pricing works on another pattern. Users pay for storage and query volume. Typically, GB of storage costs $0.02, and TB queried costs $6.25.
- Skyvia offers a free plan that handles up to 10,000 records and allows you to create up to 5 integrations. If your project doesn’t fall into the “small to medium” category, a Basic Plan will cost $49 per month (covering up to 50,000 records).
Troubleshooting Common Integration Issues
Even the smoothest data integration hit a few speed bumps along the way. But we have good news on this occasion – most MySQL-to-BigQuery hiccups fall into predictable patterns, which means they’re totally solvable with the right approach.
Problem: Connection Failure to MySQL
Most connection challenges boil down to the usual suspects: credentials playing hard to get, firewalls being overly protective, or network configs that don’t have an idea about your integration plans.
Solution
- Check firewall rules and IP whitelisting to make sure your BigQuery service can reach MySQL without getting bounced by security gates.
- Verify credentials and user permissions. Double-check that username/password combo, and ensure your MySQL user has the right privileges (don’t forget
GRANT REPLICATION SLAVEfor CDC setups). - Validate network connectivity, including VPC peering, private IP configurations, and SSL settings.
- Review Cloud IAM roles in the Google Cloud Console if you’re using Google Cloud SQL.
Problem: BigQuery Load Job Fails on Data Type Mismatch
The age-old tale of two databases that can’t understand each other because their schemas don’t match. For example, MySQL’s TINYINT(1) thinks it’s a boolean, while BigQuery raises an eyebrow and asks for clarification. Usually, this misunderstanding happens because:
- Invalid or missing credentials (username/password).
- Network connectivity issues: firewall rules, VPC peering, or private IP configurations blocking access.
- Insufficient permissions for the user in MySQL and Cloud SQL IAM roles in BigQuery.
- SSL or encryption misconfiguration.
Solution
- Refer to the data type mapping table – a roadmap for translating between MySQL and BigQuery’s type systems.
- Use a staging area to clean data before final load, especially for dates and decimals.
- Define explicit BigQuery schemas. Skip the auto-detection guesswork and tell BigQuery exactly what you expect.
- Monitor load job error logs for detailed mismatch reports.
Problem: Data Discrepancies Between Source and Target
Finding missing updates, transformation issues during ETL/ELT, or consistency delays is the perfect way to destroy a day. These differences typically result from:
- Partial or failed incremental loads.
- CDC lags.
- Incomplete replication configurations or filtering.
- Schema changes were not applied properly in the target.
The bigger problem is data loss during the migration process. It triggers a cascade of expensive consequences: failed migrations demand costly do-overs, missing regulated data invites compliance auditors, and compromised data integrity turns your entire platform into a quicksand. Why is it even possible? Network hiccups during transfer, schema changes that blindside your migration scripts, and data type mismatches.
Solution
- Implement data validation checks post-migration to confirm all changes are accounted for.
- Investigate time zone handling for DATETIME fields. Time zones are trickier than they appear, especially when crossing database boundaries and causing data jet lag.
- Monitor replication lag and tune CDC settings. Sometimes the pipeline just needs a little performance tuning to catch up.
- Review incremental capture configurations to make sure all changes are being captured and applied.
- Back up all data before migration to protect it from getting lost in the digital woods. If Skyvia Replication is your go-to tool for migration, breathe out because it significantly reduces the risk of data loss. However, there’s always a chance that such a thing might happen. If you’re not ready to play with fire, try Skyvia Backup. It puts your data into Azure GRS Storage, where it will always be available for reviewing or restoring.
Problem: Performance Degradation on MySQL During Extraction
Your production database suddenly feels like it’s running through molasses. Your speedy MySQL instance turns into a sluggish mess, leaving users wondering if the internet broke because of:
- Heavy extraction and long-running queries.
- Lack of indexing on columns used for incremental extraction.
- Extraction from production MySQL without replication or read-only replicas.
It’s the data equivalent of rush hour traffic.
Solution
- Be kind to your production workloads and schedule large dumps during off-peak hours.
- Use
--single-transactionto avoid locking tables and keep the database running smoothly while extraction occurs in the background. - Switch to the CDC method for continuous loads. It barely touches the database performance.
- Utilize MySQL read replicas for extraction, allowing the primary database to focus on what it does best.
Post-Migration Best Practices: Monitoring and Optimization
Migration is just the opening act. The real show begins afterward. That is the “adulting” phase of data integration. Maybe less exciting than the initial setup, but absolutely crucial for long-term success.
- Data validation
Trust but verify, especially when it comes to data that’s just completed a round-the-world trip.
- Start with cross-database diffing tools that compare source and target data at the table level.
- Tools like Google’s Data Validation Tool (DVT) can automate records comparison, transformation verification, and discrepancies detection.
- Don’t underestimate the power of manual spot checks either. Sometimes, a well-crafted SQL query comparing row counts and key values can catch issues that automated tools might miss.
With a platform like Skyvia in your toolkit, you’ve basically got a head start. A well-written SQL query that compares key values and row counts can occasionally identify problems that automated tools would overlook.
- Monitoring
It’s quite a horror to learn that your trusty dashboard – your supposed beacon of truth – has outwitted you, making ancient data look fresh while you’ve been calling the shots. To avoid that, BigQuery tasks and ETL pipelines must be monitored.
- Google Cloud’s Pub/Sub notifications are an early warning system, tracking job and task state changes.
- Set up Cloud Monitoring alerts for the usual suspects: failed BigQuery jobs (whether they’re loading or querying), and pipeline latency thresholds that might indicate upcoming trouble.
- Additionally, you can even stream these notifications back to BigQuery itself for analysis – meta-monitoring at its finest.
BigQuery’s job history and monitoring metrics provide real-time operational visibility, giving you the pulse of your data operations. Platforms like Skyvia sweeten the deal with dashboard-based monitoring, making it dead simple to spot data load failures or delays without diving into complex logging systems.
- Cost Optimization
The secret of wise resource allocation lies in understanding the delicate balance between query costs (based on the data scanned) and storage costs (based on the data volume). Even a tightrope walker would find this a challenge.
- Partitioning is the first line of defense against runaway query costs. Partition tables by time (typically date or timestamp columns) so queries only scan relevant chunks instead of the entire dataset.
- Clustering takes optimization a step further, organizing data within partitions based on the most frequent filter columns. That double-whammy approach reduces both query costs and improves performance.
- Even if you’re using Skyvia for efficient and budget-friendly data replication, most of the cost optimization magic happens post-load in BigQuery. Set up partitioning and clustering on the target tables to make sure ongoing queries stay both fast and affordable.
- Governance:
Good governance is, let’s admit it, boring, but absolutely essential when you need to find something important quickly. Your data dictionary should be the single source of truth, documenting schema details, table relationships, column meanings, and data lineage.
BigQuery’s governance features are surprisingly robust:
- Use the Identity and Access Management (IAM) system to control access at the project, dataset, and table levels with precision.
- Fine-grained column-level and row-level access controls protect sensitive data, while audit logging tracks who accessed what and when. Perfect for those compliance conversations with auditors.
- For sensitive data, remember to use encryption and data masking. These are not only desirable extras; they are necessary to uphold confidence and comply with legal requirements.
Conclusion
If your head spins a bit after all this information, here’s the gist of it:
- Mysqldump can be enough for one-off transfers.
- Google Data Transfer Service is perfect for recurring tasks.
- CDC-based replication gives the always-fresh data modern analytics depend on.
Whichever option you eventually decide on, success depends on coordinated schema, security, and monitoring to guarantee that your data is reliable and accurate.
If custom pipelines aren’t on your to-do list, but real-time analytics are, try Skyvia and let your data work.

FAQ for MySQL and Google BigQuery

What are the advantages of using BigQuery instead of MySQL?
BigQuery is a serverless, highly scalable DWH optimized for big data analytics. Unlike MySQL, it supports real-time streaming, fast SQL-based querying on large datasets, built-in ML models, and pay-per-query pricing for cost efficiency.
Can I use Google Cloud SQL instead of MySQL for BigQuery integration?
Yes! Google Cloud SQL (managed MySQL) can be directly integrated with BigQuery using Cloud SQL federated queries or ETL tools like Dataflow or Cloud Data Fusion, enabling real-time or batch data transfers.
What is the easiest way to move MySQL data to BigQuery?
The easiest way is to use a fully automated tool like Skyvia, Hevo, or Fivetran. These tools handle all steps of the ETL process – extraction, transformation, and loading – ensuring seamless transfer with minimal effort.
Which ETL tools support MySQL to BigQuery migration?
Popular ETL tools for MySQL to BigQuery include Skyvia, Hevo Data, Fivetran, Stitch, Google Cloud Data Fusion, and Airbyte. These tools automate data extraction, transformation, and loading, reducing manual effort.
