

Every day, lots of data is generated across all departments of an organization. To extract value from it, you need to ensure it’s correct and standardized before further processing. The implementation of data pipeline architecture can help you with that.
Like a conductor coordinates an orchestra to produce pleasing sounds, a data pipeline architecture manages data to reveal its full potential. Solutions for creating and elaborating on data pipelines aim to collect raw data from multiple sources and prepare it for analysis.
This article talks about the principal components of a typical data pipeline architecture. It also provides best practices for constructing efficient and resilient solutions. You will also see how Skyvia can improve data orchestration without coding.
Table of Contents
- Key Components of Data Pipeline Architecture
- Design Patterns for Data Pipeline Architecture
- How Skyvia Integrates with Data Pipeline Architecture
- Data Quality and Monitoring in Pipelines
- Conclusion
- FAQ
Key Components of Data Pipeline Architecture
This is an umbrella term that refers to data movement processes between different systems. It also describes the structure and components of a dataflow, which is tailored to each specific business case.
The majority of pipelines are linear and simple, but the expansion of digital services may sometimes complicate their structure. Anyway, a typical data pipeline architecture includes a standard set of modules:
- Sources of data
- Ingestion methods
- Transformation options
- Storage services
- Delivery and consumption systems
1. Data Sources
The toolset may vary from one company to another greatly. Therefore, pipeline architecture needs to consider such a variety of sources and be able to ingest data from:
- SaaS applications
- Relational and NoSQL databases
- Data warehouses
- Web services
- APIs
- Flat files
- IoT systems
- Other online and offline services
2. Data Ingestion
Data ingestion is raw data extraction from the chosen sources into a pipeline using either:
- A batch mode with data collection over predefined intervals.
- A real-time streaming with immediate data capture.
The choice of ingestion method depends on the speed, volume, and diversity of data to be collected. Data retrieval mode also affects pipeline complexity, latency, and infrastructure costs.
3. Data Transformation
The data transformation stage comes next after ingestion. Typical transformations include:
- Data cleansing
- Duplicate removal
- Outlier detection
- Normalization
- Standardization
At this stage, it’s necessary to prepare data for further analytical goals by ensuring its accuracy and quality. The data transformation step also prepares a foundation for subsequent data pipeline stages. ETL tools, such as Skyvia, are often a popular choice for data transformations.

4. Data Storage
After transformation, data travels to the destination system to be stored and processed. Relational databases, NoSQL databases, data warehouses, and data lakes are among the most popular solutions for accumulating data. Decide which storage repository to select considering:
- data types
- retrieval speed requirements
- expected scalability grade
Whatever storage system you choose must provide data for reporting, analytics, and other purposes defined by a company. For instance, data lakes contain vast amounts of raw data at low cost but aren’t very adapted for analytical queries. Data warehouses also store considerable amounts of data, but they are more convenient for querying. This results from data warehouses storing only structured and semi-structured data, while data lakes may contain unstructured data.
5. Data Delivery
Data delivery is the final stage of a data pipeline. At this point, data travels to BI tools, analytics platforms, machine learning engines, etc., so that end users (analysts, executives, etc.) can consume and utilize data.
Design Patterns for Data Pipeline Architecture
Data pipeline creation is a multi-step process where you need to consider many nuances. We have prepared several valuable pieces of advice for building scalable and resistant data pipelines.
1. Make a selection of data sources
Explore data types, formats, and other essential characteristics in systems where data is generated. This is necessary for a proper ingestion workflow design.
2. Validate data quality
Check the data quality at the entry point by detecting missing values, duplicates, anomalies, and other issues. Timely discovery of quality distortions prevents inaccuracies in further data pipeline stages.
3. Data security
Implement regular security checks to protect sensitive data across the pipeline. Data encryption, role-based access control, backup, and data governance are the most effective methods for ensuring data integrity and security.
4. Scalability
Design your pipelines with the changing loads in mind to ensure they can handle growing amounts of data. Adopt distributed processing frameworks and additional computational capacities for that.
5. Monitoring and logging
Include mechanisms for observing data flow throughout the pipeline. Ensure they can detect errors, perform audits, and execute regular health checks. Proper monitoring mechanisms help to avoid downtime and trace data movement over the pipeline.
6. Opt for data modularity
As business requirements evolve, data pipelines also might need to be changed. Therefore, it makes sense to design modular pipelines where components can be added, altered, or removed over time, adding flexibility to the pipeline. A modular structure helps to avoid pipeline creation from scratch but use the existing one and change it.
7. Choose a suitable processing algorithm
Decide whether batch, real-time, or hybrid processing suits your business use case. Consider the volume and velocity of the data entering a pipeline to select the correct processing algorithm.
8. Disaster recovery
Craft a disaster recovery plan that includes distributed storage solutions and regular backups. This approach will help to minimize downtime and ensure quick pipeline recovery in case of system failures.
9. Regular testing
Execute a series of tests on a regular basis on various data pipeline stages. With this approach, you can detect issues within your data pipelines promptly before they affect the integration flow. Testing procedures also help to explore the pipeline behavior on fluctuating data loads.
How Skyvia Integrates with Data Pipeline Architecture
In modernity, ELT and ETL pipelines are trendy types of dataflows. They effectively operate large volumes of information through collection, processing, and delivery to target systems.
Skyvia is a universal cloud platform designed for a wide range of data-related tasks, including data pipeline building. This tool supports ETL, ELT, and Reverse ETL pipelines.

Note that the ETL, ELT, and Reverse ETL pipelines aren’t the same as a data pipeline in general. Usually, an ETL pipeline represents several stages of a complete data pipeline. Feel free to check the key differences between ETL and data pipelines.
Skyvia offers several solutions for building different types of pipelines.
- Import is a wizard-based tool that allows you to construct ETL and Reverse ETL pipelines, apply data transformations, and map source and destination data structures without coding.
- Replication is a wizard-based tool that allows you to build ELT pipelines to copy data from source apps to a database or a data warehouse without coding.
- Data Flow is a visual pipeline builder that allows you to design more complex data pipeline diagrams with compound transformations. With this tool, it’s possible to integrate multiple data sources into a pipeline and implement multistage data transformations.
Benefits of building data pipelines with Skyvia:
- Pricing plans that are suitable for any company regardless of its size and industry of operation.
- An intuitive interface allows you to create pipelines of various difficulty levels without coding.
- Powerful transformation functions.
- Being a native-cloud solution, Skyvia allows for easy scalability to match current data needs.
- Support of 200+ sources, including SaaS apps, databases, data warehouses, etc.

Data Quality and Monitoring in Pipelines
Monitoring and logging features help businesses track data integration outcomes. These mechanisms also detect data quality issues at any point in the pipeline architecture. All of this ensures data accuracy, which is essential for correct analysis of business performance and credible predictions for the future.
Let’s look at the monitoring in data pipelines and explore Skyvia mechanisms for ensuring data quality at certain stages of the pipeline.
- Data sources. At this stage, data monitoring takes place on the source site, where the system shows issues with raw data and suggests actions to be taken to improve data quality.
- Collection. When starting to ingest data from a source, Skyvia will show a warning in case of any connection issue or data retrieval problem.
- Processing. During the transformation and mapping procedures, Skyvia shows warning and error messages if something isn’t set up correctly. For instance, data structure inconsistencies between the source and target system or incompatibility of the chosen data format with the field type will invoke a warning.
- Storage. Once the integration is executed, Skyvia provides its outcome in the Monitor tab. In case of failure, check the Log for a detailed description of an error. You can also set up email notifications in case of data integration issues.
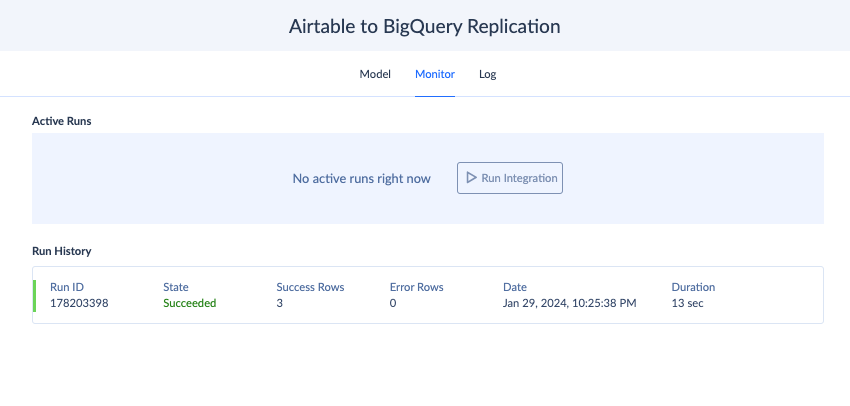
- Consumption. At this stage, the warning and notification message appear in the BI tools, reporting solutions, and other software products where data is used for a specific purpose.
Conclusion
Data pipeline architecture is a compound notion that involves dozens of tools and processes. It needs to implement mechanisms for robust data security, quality checks, and smooth data flow. A pipeline should also be modular, providing scalability and flexibility in data movement.
Skyvia is at the heart of any data pipeline since it offers ETL and ELT approaches for working with data. It also ensures outstanding data security, powerful transformation options, and a variety of no-code connectors to multiple data sources.

FAQ for Data Pipeline Architecture

What is the difference between ETL and data pipeline?
A data pipeline is a general term assuming the flow of data from a source system to the destination with the processing operations in between. Meanwhile, the ETL pipeline is a specific approach to data pipeline organization. Feel free to explore other key differences between ETL and data pipelines.
