

AI is eating the world—90% of today’s data was created in just the last few years, and every shiny AI tool out there runs on one thing: clean, reliable data. Problem is, most companies sit on mountains of messy logs, CSVs, and APIs that are nowhere near “AI-ready.” That’s where the AI data pipeline comes in — it’s the plumbing that turns raw chaos into something models can actually learn from.
In this guide, you’ll see how it works, how it extends what you already do with ETL, and how it makes you the hero behind the numbers.
Promise – no textbook vibe. Just 7 ways your ETL skills still save the day.
Table of Contents
- What is an AI Data Pipeline (for ETL Pros)?
- The Key Stages of a Modern AI Data Pipeline
- 7 Ways AI Data Pipelines Make You the Hero Behind the Numbers
- Common Challenges and How to Overcome Them
- Use Cases: AI Data Pipelines in Action
- How Skyvia Can Help You Build Your AI Data Pipeline
- Conclusion: The Future is Automated & Intelligent
What is an AI Data Pipeline (for ETL Pros)?
So here’s the plain version first: an AI data pipeline is just your ETL pipeline with extra steps for machine learning. It still extracts, transforms, and loads. The difference? Instead of stopping at a warehouse, it keeps going — into models that train, predict, and (when they’re wrong) learn again. Also, streaming or real-time data flows into this pipeline.
Check it out below:
Think of ETL as a delivery truck. You pick up packages (extract), sort them at a hub (transform), and drop them at the right addresses (load). An AI pipeline is more like a whole logistics network. It doesn’t just deliver — it studies traffic, predicts demand, and reroutes on the fly so next week’s deliveries are smoother.
Now, let’s make this real.
ETL vs AI Data Pipelines
Here’s the part you probably feel but haven’t seen spelled out. How different is ETL to AI data pipelines? I’ll throw it in a table so it’s easier to eyeball, but keep in mind—it’s not just a checklist, it’s a mindset shift.
| Aspect | Traditional ETL | AI Data Pipelines |
|---|---|---|
| Workflow | Linear: Extract → Transform → Load. You run it, it’s done. | Iterative: Ingest → Prep → Train → Predict → Monitor → Retrain. With MLOps (for ML CI/CD), life’s easier with automated retraining/deployment. |
| Data Types | Mostly structured—tables, CSVs, APIs. | Structured + semi-structured (JSON, logs) + unstructured (images, text, IoT feeds—aka “the mess”). |
| Processing | Batch runs (daily, weekly). I had jobs that kicked off at 12 AM… and failed at 12:05. (But totally fixable). | Batch + streaming. Fraud alerts, recommendations, anomaly detection—all as it happens. |
| Destination | Warehouse → dashboards, BI reports. | Models → predictions, recommendations, alerts. End user isn’t a manager with a chart—it’s a system making calls. |
| Monitoring | Did the job complete? Row counts match? | Drift, accuracy, bias. Not just “did it run” but “does it still make sense?” |
| Collaboration | Often a solo gig (yep, I’ve been the 1-man ETL shop). | Cross-functional: data engineers, ML engineers, ops. Sometimes still one person… just wearing hats. |
| Business Impact | Backward-looking: KPIs, what happened. | Forward-looking: forecasts, predictions, automation. |
👉 Bottom line: ETL moves data from A to B. AI pipelines try to learn from it so tomorrow’s output isn’t the same old rerun. But ETL isn’t dead. This doesn’t mean that ETL is dead. It’s still the backbone — AI just extends the chain.
And this is where the fun starts — there are 7 ways AI pipelines make you the hero. We’ll get there, but first, let’s break down the moving parts — so you can see where your existing skills slot in, and where the new stuff begins.

The Key Stages of a Modern AI Data Pipeline
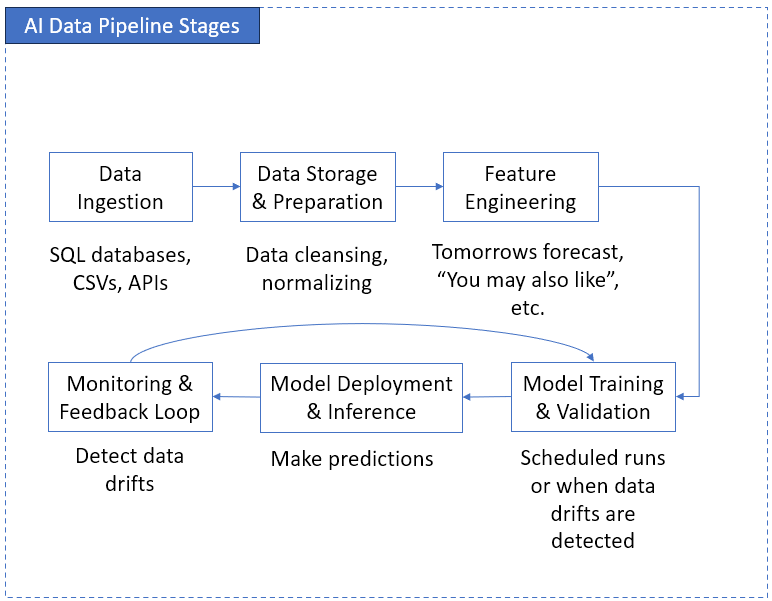
If you’ve built ETL jobs, you already know the rhythm: extract, transform, load. That same rhythm lives inside an AI data pipeline architecture — just with a few extra beats and some loops you didn’t bargain for. Think ETL on steroids, or maybe ETL with insomnia (because it never sleeps). That table earlier was the 10,000-foot view. Here’s the close-up, stage by stage.
Check it out below:
Let’s break it down.
Stage 1: Data Ingestion
Still connectors, but messier. In ETL, I pulled from SQL databases, some CSVs, maybe an API or two as data sources. Here, you’re also dealing with event streams, IoT sensors, even blobs of unstructured stuff. Think “meter readings plus random log files plus maybe images.” The ETL tools you know can feed the AI pipelines.
Tools you can use: For streaming pipelines, we have Kafka or Spark. Also, batch ingestion gizmos you may know, like Apache Nifi or Skyvia (Spoiler: we’ll have an example with Skyvia later).
Example: For electricity consumption, instead of just the daily reading, you might add real-time sensor events (voltage spikes) streaming in. Yeah, that means you’ll need something like Kafka or Spark streaming instead of your good old nightly cron.
Stage 2: Data Storage & Prep
This part still feels like home. You’ve got your data warehouse or lake, you clean things up, normalize, dedupe. Same SQL brainpower, different plumbing.
Tools you can use: Snowflake, BigQuery, DataBricks/Spark, dbt. Our example later writes to Snowflake, so stay tuned.
Example: Back when I built insurance dashboards, I sometimes had to squash duplicate policy entries. Here, it’s the same cleanup—just maybe in a data lake instead of a relational database.
Stage 3: Feature Engineering (the “new transformation”)
Here’s the twist. Instead of aggregates like “total claims per region,” you’re creating features like “rolling 7-day average consumption” or “time since last claim.” Same data transformation muscle, different recipe.
Tools you can use: Classic Python libraries like Pandas (I used this one for the utility consumption) and Numpy, or feature stores like Feast.
Example: For my home utilities project, one feature was “days since last high usage spike.” That’s just a glorified date diff, but to a model it’s gold.
Stage 4: Model Training & Validation
This is your new Load. In ETL, you drop data into a warehouse. Here, you feed it into a model for training. Train, validate, tweak, retrain. And unlike dashboards, models can actually argue back (well, with bad accuracy scores).
Tools you can use: scikit-learn, TensorFlow, MLFlow
Example: Imagine training a model to predict tomorrow’s water consumption. You split your past data: 80% for training, 20% for validation. If the model starts predicting nonsense, you tweak features or try another algorithm.
Stage 5: Model Deployment & Inference
Think of this model deployment as publishing. ETL pushes to a dashboard; here, you push to an endpoint or service that delivers predictions.
Tools you can use: AWS SageMaker, KFServing
Example: Instead of refreshing a Power BI report, your model is serving “tomorrow’s estimated consumption” right into your dashboard table. Same delivery feeling — just your “report” now comes from a model.
Stage 6: Monitoring & Feedback Loop
ETL monitoring is emails about failed jobs. AI adds another headache: data drift. The model gets stale. Predictions slowly go off the rails.
Tools you can use: Evidently AI, WhyLab, Arize AI
Example: In my utility project, if consumption suddenly changed (say, new appliance in the house), the old model would underpredict every single day. Without retraining, you’d never catch it.
👉 Key takeaway: An AI pipeline isn’t some alien system — it’s the same ETL galaxy, just with more gravity and an orbit that loops back on itself.
Anyway, that’s the architecture. Nuts and bolts are nice, but let’s be honest — what you really want to know is: why bother? What’s in it for you as an ETL pro who already keeps dashboards running and jobs from blowing up?
That’s where the payoff comes in. Let’s walk through the 7 AI data pipeline benefits.
7 Ways AI Data Pipelines Make You the Hero Behind the Numbers
Because the real magic of an AI data pipeline isn’t in the plumbing diagrams—it’s in what it lets you stop doing (the grind) and what it opens up (new wins). I’ll keep it real and give examples you’ve probably lived through, too.
1. Automate the Tedious Stuff
Remember those endless nights fixing the same broken job? I once had an ETL batch that failed if someone uploaded an empty or deformed CSV. Of course, it’s fixable. And yes, I fixed it. But AI pipelines lean harder into automation—detecting patterns, catching anomalies before they break.
Make it less manual to ingest. Use the tools with scheduling and drag-and-drop components, like Skyvia. The tools for monitoring anomalies? Try Evidently AI or other cloud AI services, like AWS Lookout.
Example: Instead of manually writing rules to flag missing readings, an automated check can learn the “normal” pattern and raise a flag when something looks weird.
2. Deliver Cleaner, Smarter Data
ETL gave us row counts and NULL checks. AI pipelines add intelligence. They don’t just say “missing value here” — they can fill it in using historical patterns.
For data drifts, use tools like Evidently AI, and for the usual transforms, dbt gets it done.
Example: Once I had a dashboard for seafarer data, and gaps in it were a nightmare. With AI-driven imputation, you don’t just know data is missing — you get a smart guess that keeps the downstream reports intact.
3. Speed Up Model Delivery
Traditional ETL: you clean data, push to warehouse, build reports. Slow, but steady. With an AI pipeline, the cleaned and transformed data flows directly into model training, testing, and even deployment. That means quicker time-to-value.
To track experiments and avoid “where’s that model file?”, you can use MLFlow.
Example: Instead of waiting weeks to roll out a “new sales KPI” dashboard, you could spin up a churn prediction model in days. That’s AI data pipeline optimisation at work — fewer manual handoffs, more delivery.
4. Scale Without Extra Headcount
I design my ETL pipelines with the future in mind. So I don’t change the pipeline every now and then when some new requirements come up or the data volume explodes. But sometimes, a few weird stuff emerge. So some late nights still come up. But AI pipelines are built to scale horizontally — new data sources, bigger volumes — with built-in automation. So, the grunt work? Minimized. And adding more engineers? No need.
But note that it doesn’t offload strategic design from you. It provides you with info so you finish faster. So, you’re enough in certain cases without new guys to help.
To handle more data sources without adding more engineers, you can use Skyvia, Fivetran, or similar. Meanwhile, Kubernetes helps to autoscale workloads.
Example: Plugging in IoT sensor data for utilities doesn’t mean hiring three more ETL devs. The pipeline handled ingestion and transformation with built-in automation, while I fine-tuned only the exceptions.
5. Enable Real-Time Insights
ETL = batch. You wait until the nightly load finishes. AI pipelines? They can serve predictions live. For no waiting time, Kafka is always in mind, and KFServing for real-time model serving.
Example: With utilities, I used to get “yesterday you consumed 50 kWh.” Helpful-ish. But with real-time inference, I get “today you’re on track to exceed your cap.” That’s a different level of value.
6. Bridge DevOps and MLOps
I once joked that half my job was duct-taping cron jobs to scripts and hoping they’d run. AI pipelines force you to borrow best practices from DevOps — versioning, CI/CD, monitoring—but applied to models (MLOps).
You enjoy model training, validation, deployment, and monitoring with MLOps tools like MLFlow and Kubeflow.
Example: Instead of “v2_final_FINAL.sql,” you now track “Model v1.3” with version control and deployment pipelines. Way less chaos.
7. Turn Data Into Business Advantage
Dashboards tell stories about the past. AI pipelines let you change the story in real time. That’s the big shift — from hindsight to foresight.
This is the hero part for you. Try Snowflake ML or BigQuery ML to do ML from your warehouse.
Example: In insurance, a dashboard said “claims spiked last quarter.” An AI pipeline could’ve said, “claims will spike next month, here’s why.” Which message do you think the execs would prefer?
👉 Bottom line: ETL makes you the person who moves data. AI data pipelines make you the person who moves the business forward.
And of course, it’s not all sunshine. There are potholes — messy data, brittle jobs, models that go stale the moment you look away. Let’s get real about the common challenges and how to overcome them.
Common Challenges and How to Overcome Them
Here’s the part nobody brags about on LinkedIn: AI pipelines break. And usually in ways that feel way too familiar if you’ve been wrangling ETL. You know the drill – the late-night surprises, row counts that don’t add up, or that one API that breaks on Fridays. Anyway… let’s walk through the usual suspects and how to keep them from eating your pipeline alive.
Data Silos
Classic headache. Finance has their database, HR has another, marketing has twelve spreadsheets that never match. In ETL, I once built a whole job just to stitch together finance data from sister companies that allegedly tracked the same thing (spoiler: they didn’t).
Solution: In AI pipelines, the fix is wide connectors and integration platforms. Tools that can pull from structured (databases), semi-structured (JSON APIs), and unstructured (logs, images). It’s not just stitching tables — it’s breaking walls.
Data Quality
ETL déjà vu. Nulls, duplicates, bad formats — you’ve seen it. From my years of experience, other common pipeline breakers are apostrophes in data and bizarre date formats. Imagine explaining that to an exec.
Solution: Add automated checks and cleansing routines. AI data pipeline optimisation often means layering in validation at ingestion, not just at the end. If data smells funny, flag it early. Still a best practice whether in data pipelines, front-end systems, or otherwise.
Scalability
In ETL, scaling usually meant “optimize the SQL” or “throw more hardware at it.” We had a SQL Server load that took hours until we used incremental updates.
Solution: AI pipelines lean on cloud and distributed systems. Spark, Kubernetes, managed cloud ML services — stuff that scales horizontally. The trick isn’t brute force, it’s elasticity.
Collaboration (MLOps)
Here’s the culture shock. ETL was often a solo gig (me, my scripts, my logs). AI pipelines force collaboration — data engineers, scientists, ML folks, ops. Unless you’re all in one person, switching hats mid-day.
Solution: Shared tools and workflows. Version control, model registries, CI/CD for data. And yes, a culture where people actually talk to each other before pushing breaking changes (still working on that one).
👉 The point: If you’ve lived through bad data quality, broken jobs, or scaling nightmares, you’re already halfway there. AI data pipeline optimization just raises the stakes — and gives you better gear to fight back.
So, that’s the dirty laundry. Next, let’s make it less abstract. Let’s look at some real-world use cases of AI data pipelines in action.
Use Cases: AI Data Pipelines in Action
This is where things get fun. Diagrams and theory are nice, but seeing how AI pipelines actually move the needle? That’s the good stuff. And honestly, most of these use cases aren’t some sci-fi future—they’re problems you and I have already wrestled with in ETL, just turned up a notch.
E-commerce → Personalized Recommendations
Remember when we built “Customers by Region” dashboards and thought that was enough? Yeah, turns out people want Netflix-style “you might also like” predictions. An AI pipeline ingests transaction logs, product views, even clickstream data, then feeds it into models that serve personalized recommendations in real time.
Example: Instead of showing “Top 10 products sold last month,” the model can nudge a customer with “Hey, you forgot socks to go with those sneakers.” That’s the difference between a BI report and a generative AI data pipeline making live suggestions.
Where ETL pros fit: building ingestion jobs that pull clean product, transaction, and user activity data into the pipeline.
Finance → Fraud Detection
This one feels close to home. Back in my ETL days, I had a nightly batch that flagged “unusual” transactions. Helpful, but if fraud happens at 2 PM, waiting for the midnight run is… bad.
Example: With an AI pipeline, streaming data (credit card swipes, login attempts) flows through a model that says, “Hmm, this looks shady” as it happens.
Why it works: You’re still building ingestion pipelines — except now it’s Kafka or Kinesis streaming events instead of CSV dumps.
Healthcare → Medical Image Analysis
Okay, I never ETL’d X-rays, but the pattern is the same: large, messy data that doesn’t fit in neat rows and columns. AI pipelines preprocess images (resize, normalize, extract features), feed them into models, then keep retraining as new data comes in.
Example: Instead of manually labeling thousands of scans, the model helps spot anomalies, and the loop keeps improving as doctors confirm results.
Where ETL pros fit: you’re the one who designs the ingestion and transformation stages — just swap “sales tables” for “DICOM files.” The pattern stays familiar.
👉 Key takeaway: whether it’s retail, banking, or healthcare, the backbone doesn’t change. AI pipelines just raise the expectations — from “show me what happened” to “tell me what’s about to happen.”
And yes, you don’t have to reinvent the wheel to build one. Tools exist to save you from hand-rolling every connector and job. So let’s talk about how Skyvia can help you put together your own AI data pipeline without living in error logs.
How Skyvia Can Help You Build Your AI Data Pipeline
If you’ve ever stared at a jungle of APIs and thought, “I just need this data in one place, why is this so hard?” — that’s where Skyvia shines. Skyvia is a diverse integration platform that helps you not only ingest data – backup, import/export, replication, automation, and more. It’s one of those tools that doesn’t make you reinvent the wheel. You don’t lose your SQL chops — you use them where they count. Skyvia just clears the grunt work. Point, click, map a few fields, and suddenly data is flowing between apps like you meant it all along.
Skyvia covers the boring-but-critical stuff like connectors, scheduling, monitoring, security — All done visually to slice down your dev time. I once spent more than 2 hours wiring Salesforce to Snowflake in Python. With Skyvia, I clicked through it in less than 10 minutes.
Anyway… the big win is friction. Less friction means you, the ETL pro, don’t get stuck wiring cables all day and can actually step into the AI era.
“We’re thrilled to be recognized as Top Data Integration and Data Pipeline Tool by TrustRadius and our customers. Our mission is to make data integration accessible to businesses of all sizes and to all clients, regardless of their coding expertise. Receiving this award confirms that we are moving in the right direction by creating an easy-to-use yet feature-rich solution capable of handling complex scenarios.” Oleksandr Khirnyi, Chief Product Officer at Skyvia, stated.
Skyvia Example: Salesforce → Snowflake
Here’s a pipeline I put together— visually, not with code:
- Source: Salesforce Leads, Opportunities, and Accounts. That’s the lifeblood of any sales org.
- Transform: I slipped in a calculated field using Extend, Days_Open = CloseDate – CreatedDate, on Opportunities. That tiny tweak feels small in ETL land but is pure gold for ML.
- Target: Snowflake. All clean and staged, ready for training models that predict which leads will close and when.
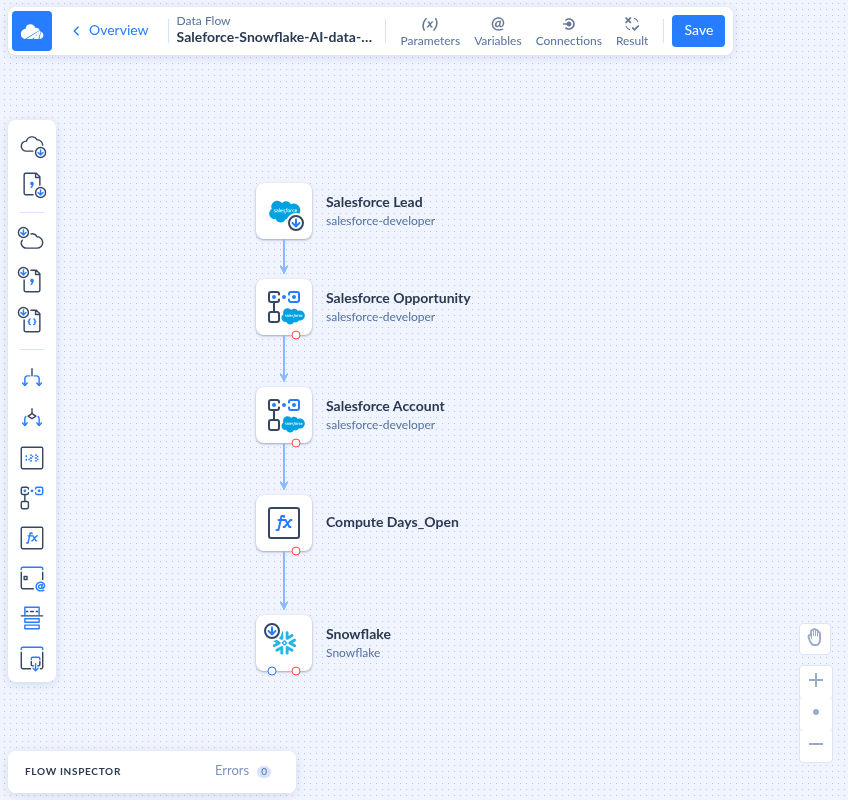
This isn’t rocket science. It’s just Skyvia making ingestion and prep painless so you can focus on the AI side.
Definitely not magic. It’s just Skyvia doing what it does best — moving and shaping data fast enough so your AI pipeline can pick it up without fuss.
👉 Ready to level up your ETL game? Try Skyvia free. Worst case, you save yourself a few hours of pipeline wiring. Best case, you look like the hero who just made AI work without a whole new tool stack.
Conclusion: The Future is Automated & Intelligent
So yeah… AI data pipelines aren’t some brand-new alien thing. They’re just the next chapter in the ETL playbook — same core skills, different outcome. Instead of only feeding dashboards, you’re feeding models that predict, recommend, and sometimes even act on the data.
The road ahead? More automation, more real-time, and yeah, more “oops, why did the model do that?” moments. But the upside is clear: if you lean into this shift, you’re not just a data plumber anymore. You’re the one turning pipes into the company’s secret weapon.

F.A.Q. for AI Data Pipeline

What are the most critical stages of an AI data pipeline?
Ingest, prep, feature engineering, training, deployment, monitoring. Basically ETL with two new hats: features instead of aggregates and models instead of dashboards.
Why is “garbage in, garbage out” so critical in AI?
Because models are even pickier than humans. If your ETL job sends messy data to a dashboard, a manager might spot the error. If you feed that same mess into a model, it’ll happily “learn” the wrong patterns and serve garbage predictions at scale.
Can I build an AI pipeline without coding?
Yep. Platforms like Skyvia or even cloud-native AI services let you do no-code/low-code builds. But — and here’s the kicker — knowing SQL/ETL logic makes you 10x better at using those tools. You’ll understand what’s really happening under the hood.
What is MLOps and how does it relate to AI data pipelines?
MLOps is basically DevOps for machine learning. It’s the set of practices, tools, and workflows that keep AI models healthy — deployment, monitoring, retraining. Your AI data pipeline feeds into MLOps because without reliable data flows, MLOps is just fancy talk.
