

Let’s be honest: data is piling up, spreading out, and demanding more from every team that touches it. That’s why platforms like Google BigQuery are getting all the love these days.
- It’s fast;
- It scales with your business;
- It allows users to run serious analytics without babysitting servers or dealing with hardware headaches.
Meanwhile, many businesses continue to operate on tried-and-true systems like SQL Server. It’s robust but not created for the cloud world we’re living in now.
So, users have data trapped on-premises, siloed off from the rest of the stack, and slowing things down. Reports lag. Insights stay hidden. Teams fly blind.
Sound familiar?
Here’s the good news: moving your SQL Server data into BigQuery changes the game. You get real-time access, powerful querying, machine learning tools baked right in, and all of it in one place. No more duct-taped dashboards or midnight Excel exports.
Of course, the big question is: how do you actually make the move without pulling your hair out?
This guide will break down the main methods for importing data from SQL Server into BigQuery, ranging from one-time exports to building a fully automated pipeline. We’ll also show how modern tools like Skyvia can seriously cut down the grunt work and make integration way less painful.
So, let’s dive in.
Table of Contents
- Why Integrate SQL Server with BigQuery?
- Methods for SQL Server to BigQuery Integration
- Method 1: Manual Export/Import via Google Cloud Storage (GCS)
- Method 2: Using SQL Server Linked Servers (with ODBC/OLE DB)
- Method 3: Custom Scripting
- Method 4: Google Cloud Data Fusion
- Method 5: Third-Party ETL/ELT Tools
- Key Considerations When Choosing a Method
- Common Challenges and How to Overcome Them
- Conclusion
Why Integrate SQL Server with BigQuery?
So why go through the trouble of piping data from SQL Server into BigQuery?
Let’s do a quick rundown.
- Scalability without the stress. BigQuery handles terabytes like it’s nothing. Whether you’re running one query or a thousand, it scales automatically behind the scenes.
- No servers, no sweat. It’s fully serverless. That means no tuning, no provisioning, and no patching. Google handles the plumbing, so you can focus on getting answers.
- Pay only for what you query. With on-demand pricing, you’re not burning cash on idle infrastructure. Run a query and pay for the data you touch. That’s it.
- Analytics superpowers. Native support for machine learning, geospatial analysis, and seamless integration with tools like Looker, Data Studio, and Vertex AI make it more than just a database. It’s an analytics powerhouse.
That’s a serious upgrade from most on-prem environments.
When Does This Move Make Sense?
There are a bunch of scenarios where syncing your SQL Server data with BigQuery just makes good business sense:
Centralized Analytics & Reporting
Tired of stitching reports together from multiple sources? Consolidating SQL Server data into BigQuery gives your team a single source of truth. Run queries across systems. Build live dashboards. Answer questions fast.
Data Archiving Without the Bloat
Keep historical SQL Server data in BigQuery without overloading your primary systems. You’ll keep performance high on SQL Server while BigQuery handles the heavy lifting for trend analysis and long-term storage.
Unlock BigQuery’s Advanced Analytics
Once your data’s in BigQuery, you’re free to layer on all kinds of advanced use cases, like:
- Machine learning;
- Forecasting;
- Segmentation;
- Anomaly detection.
Stuff that’s tough or downright impossible to do efficiently inside SQL Server.
Future-Proof Your Stack
Still running on aging hardware or legacy SQL Server instances? Moving to BigQuery is a big step in modernizing the data infrastructure. You’ll be:
- More agile;
- More cloud-ready;
- More scalable.
Methods for SQL Server to BigQuery Integration
There’s no “best” way to move data from SQL Server to BigQuery, just the one that fits your setup. It all depends on things like:
- How much data you’re dealing with;
- How often you need it to move;
- How much effort you want to put into managing the process.
Most teams end up using one of these five routes:
- Manual Export/Import via Google Cloud Storage (GCS): basic, but it gets the job done for small one-offs.
- SQL Server Linked Servers (ODBC/OLE DB): familiar if you live in the SQL world.
- Custom Scripting: code it yourself and call the shots.
- Google Cloud Data Fusion: a visual, Google-native option for building pipelines
- Third-Party ETL/ELT Tools: plug-and-play platforms that handle most of the heavy lifting.
Each approach comes with its mix of pros, cons, and trade-offs. Let’s shortly compare them.
| Method | Best For | Pros | Cons |
|---|---|---|---|
| Manual Export/Import via GCS | One-time or small data transfers. | Simple setup, no extra tools needed. | Manual, repetitive, not scalable, no automation. |
| Linked Servers (ODBC/OLE DB) | SQL-heavy teams with legacy systems. | Can query across systems, uses familiar SQL tooling. | Complex setup, fragile connections, not built for cloud workflows. |
| Custom Scripting | Dev teams needing full control. | Highly flexible, customizable automation. | Time-consuming to build and maintain, requires ongoing dev resources. |
| Google Cloud Data Fusion | Enterprises with hybrid/multi-source needs. | Scalable, visual interface, integrates well with GCP ecosystem. | Steeper learning curve, may be overkill for simpler pipelines. |
| Third-Party ETL/ELT Tools | Growing businesses needing quick wins. | Fast setup, built-in connectors, no/low-code options, monitoring support. | May hit pricing limits at scale. |
Now let’s get into the nuts and bolts of each method. When it makes sense, how it actually works, and what might trip you up.
Method 1: Manual Export/Import via Google Cloud Storage (GCS)
Best for
It’s a solid choice for:
- Small teams.
- Ad-hoc analytics.
- Businesses without dedicated data engineers.
This approach fits people who want to get things done. No automation, no fancy tools, just a straight-up file transfer. If you’re dealing with one-off jobs or testing things out, manual export keeps it simple.
Step-by-Step Guide
- Go to BigQuery in the Google Cloud Console
Head to Google Cloud. Find the dataset and table (or query result) you want to export. If it’s a custom query, make sure you run it first. Exports only work on completed results.
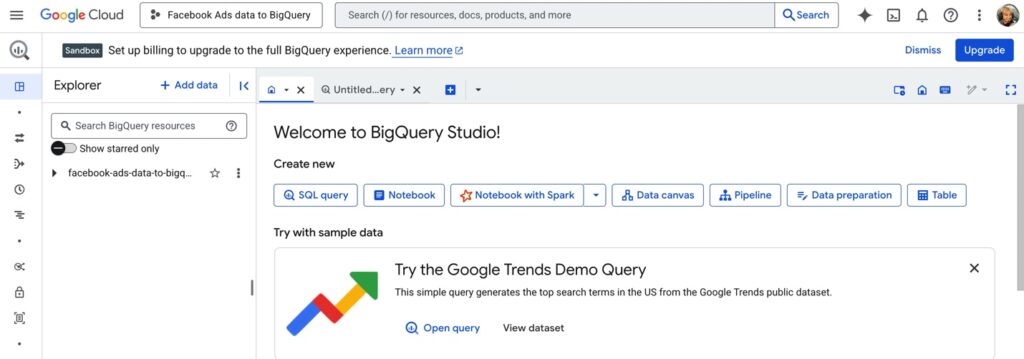
- Choose your export source
You can export:
- An entire table.
- The results of a custom SQL query (use “Save Results”).
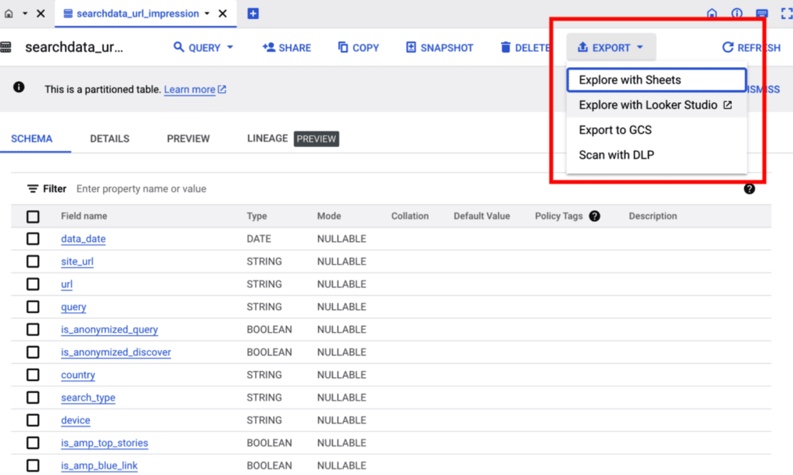
For tables:
- Right-click the table name or click the three dots (⋮).
- Select Export > Export to GCS.
For query results:
- After running your query, click the Save Results button above the output.
- Choose Export to GCS.
- Set export options
- Pick the destination path: gs://your-bucket-name/folder/filename.csv.
- Choose a file format: CSV, JSON, Avro, or Parquet.
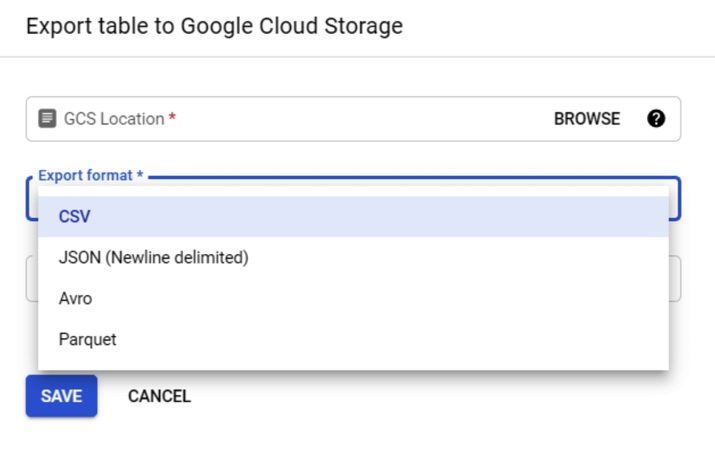
- For large datasets, BigQuery will automatically split files into chunks like filename000000000.csv.
- Optional: Set compression and field delimiter if needed.
- Export the file
Click Export and let it run. You’ll see a confirmation message once it’s complete. Large exports might take a few minutes. Don’t close the browser.
- Go to Google Cloud Storage (GCS)
Visit the console browser and navigate to your bucket. You’ll see the exported file(s) there. Use the checkbox to select it.
- Download the file
- Click the file, then hit the Download button.
- Save it locally or move it wherever it’s needed.
- Import into your destination system
Most platforms support importing CSV/JSON files. Follow their import steps and point them to the downloaded file.
Pros
- Zero setup. You can do this in five minutes flat.
- No tools or services to learn. Only native Google stuff.
- Full control over file format and structure.
Cons
- Manual completely. You’ll get tired of this fast if you have to repeat it.
- No scheduling, no automation, no error handling. You’re on your own.
- Easy to mess up file naming, formatting, or forget a step.
Method 2: Using SQL Server Linked Servers (with ODBC/OLE DB)
Best for
This approach suits businesses that live in SQL Server but need to tap into BigQuery for analytics, external data, or newer cloud-based sources. It’s good if you have:
- In-house DBAs.
- Legacy systems.
- Reporting pipelines built around SQL Server.
There is no need to copy/paste data. Link them up and query across both as if they were one system.
Step-by-Step Guide
- Install the BigQuery ODBC or OLE DB driver
- Head to Google’s ODBC driver download page.
- Download and install the correct driver version (32-bit or 64-bit, depending on your SQL Server setup).
- Configure a DSN (Data Source Name)
- Open ODBC Data Source Administrator on your Windows server.
- Create a new System DSN using the BigQuery driver.
- Enter your project ID, default dataset, and service account credentials (you’ll need to generate a key file if you haven’t already).
- Set up a Linked Server in SQL Server
- In SQL Server Management Studio (SSMS), go to Server Objects > Linked Servers.
- Right-click and choose New Linked Server.
- Set the provider to Microsoft OLE DB Provider for ODBC Drivers.
- Give your server a name and configure it to use the DSN you just created.
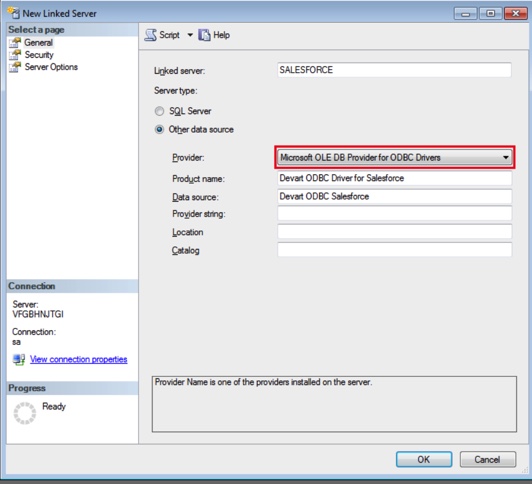
- Configure security settings
- In the Linked Server setup, under Security, map the local SQL Server login to a remote login (can be left blank for DSN-based access).
- Make sure RPC Out is enabled under server options.
- Query BigQuery from SQL Server
Now you can run queries like this in SSMS:
SELECT *
FROM OPENQUERY([YourLinkedServerName], 'SELECT * FROM `project.dataset.table` LIMIT 100') Pros
- Lets you query BigQuery straight from SQL Server. No exports, no syncs.
- Good fit for enterprise environments with strict IT processes.
- Keeps all data access centralized in one system.
Cons
- Pain to set up: drivers, DSNs, credentials, and permissions all need to line up.
- Performance can lag, especially on large datasets.
- Error messages are vague, and debugging can be difficult.
Method 3: Custom Scripting
Best for
This approach is a great fit for teams with in-house developers who aren’t afraid to get their hands dirty with code. If you’re working with complex logic, need full control over data transformation, or want to build a reusable integration pipeline tailored to your business, custom Python scripts give you that flexibility. It’s also a solid option when off-the-shelf tools just don’t cover your edge cases.
Pros
- Full flexibility. You’re not boxed into templates or UI limits. With Python and the right client libraries, you can connect, query, and manipulate data however you like.
- Automation powerhouse. Set it and forget it. Custom scripts run on a schedule, respond to events, and do the heavy lifting while you sleep.
- Ecosystem-ready. Python plays nicely with APIs, databases, spreadsheets, cloud services, and so on.
Cons
- Steeper learning curve. If Python isn’t in your toolkit yet, expect some ramp-up time. And if debugging makes you break out in hives, this might not be your jam.
- More moving parts. You’ll need to manage dependencies, API tokens, error handling, logging, and maybe even a hosting setup. Not hard, but definitely not “click and go.”
- Maintenance matters. Unlike plug-and-play tools, scripts need some TLC over time. APIs change, libraries update, and what worked last month might throw errors tomorrow.
Method 4: Google Cloud Data Fusion
Best for
It’s a nice choice for teams already living in the Google Cloud universe who want a visual, low-code way to juggle multiple data sources and stitch them together without writing tons of custom code. This method is ideal for data engineers who prefer drag-and-drop interfaces but still require power under the hood.
Step-by-Step Guide
- Create a Data Fusion instance
- Go to the Google Cloud Console. Search for Data Fusion, then click Create Instance.
- Choose the Basic edition for testing or smaller jobs, or Enterprise if you need advanced features like VPC peering or private IPs.
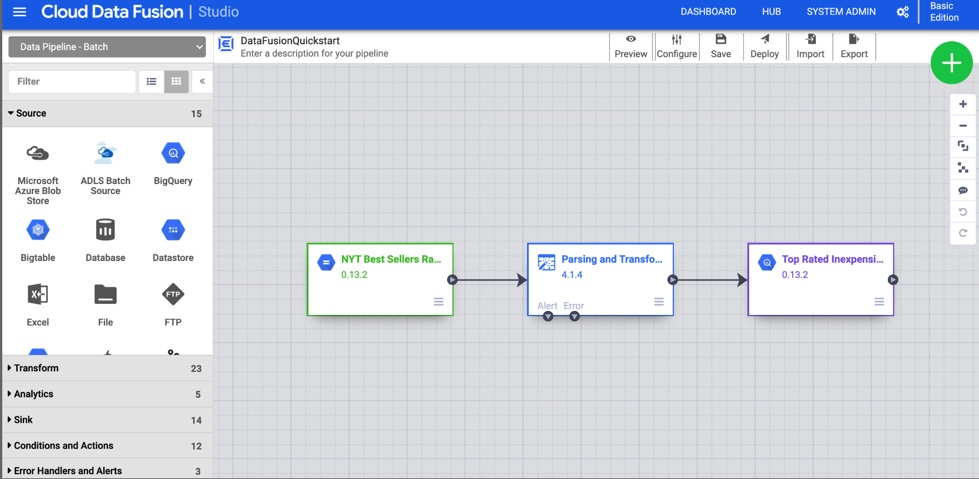
- Open the Pipeline Studio
- Once the instance is ready, click View Instance and then Pipeline Studio from the top menu.
- This opens the visual editor where you build your data flow with drag-and-drop components.
- Add a source
- Drag a source connector (e.g., Cloud Storage, BigQuery, or MySQL) onto the canvas.
- Click it, then enter connection details (like bucket path, SQL credentials, etc.). Use the “Test” button to confirm that it works.
- Add transformations
- Drop in transformations like Wrangler (for data cleaning), Join, GroupBy, or JavaScript (for custom logic).
- Chain them together by drawing arrows from one component to the next.
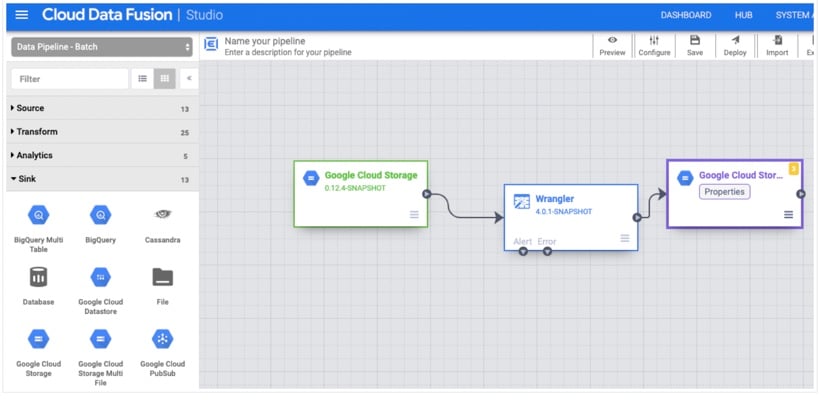
- Define the destination
- Drag your destination, like BigQuery, Cloud SQL, or Cloud Storage, to the canvas.
- Set up the table, schema, or bucket path. Click Validate to confirm that the pipeline layout is ready to go.
- Deploy and run
- Click Deploy.
- Then, click Run. The interface will show job status, step-by-step logs, and throughput.
- You can also watch how long each step takes and troubleshoot errors from this view.
- Schedule the pipeline
- Once it runs smoothly, set it to run daily, hourly, or on-demand using Schedule options or Cloud Functions for event triggers.
Pros
- No heavy lifting. You don’t need to code everything by hand. Just wire things up visually.
- Plays well with Google Cloud. Seamless integration with BigQuery, Pub/Sub, Cloud Storage, and other native services.
- Reusable pipelines. Once you build a pipeline, you can duplicate, modify, and scale it fast.
- Enterprise-ready. Supports lineage tracking, error handling, and monitoring out of the box.
Cons
- Not truly no-code. While it’s low-code, you’ll still need some technical know-how, especially when configuring connections or debugging errors.
- Costs can add up. Especially with the Enterprise edition and large-scale data volumes, you’ll want to keep an eye on the bill.
- UI learning curve. The visual interface is powerful, but not exactly intuitive the first time around. Expect some trial and error.
Method 5: Third-Party ETL/ELT Tools
Best for
This one is perfect for teams that need a clean, reliable way to move data from SQL Server to BigQuery without writing code or building pipelines from scratch. There are solid options out there:
- Fivetran is enterprise-grade but pricey.
- Airbyte is flexible but requires engineering muscle.
- Hevo is smooth but comes with a higher cost.
Skyvia stands out if you want something that’s:
- Fully cloud-based.
- Easy to set up (think: minutes, not hours).
- Budget-friendly.
- Designed for non-developers.
If your business lives in SQL Server but wants to unlock analytics in BigQuery without spinning up complex infrastructure, it’s your shortcut.

Step-by-Step Guide
Start by logging into Skyvia. If you don’t have an account, go ahead and sign up for free.
- Create a SQL Server connection
- Click +Create New, then select Connection → SQL Server.

- Provide your server address, user ID, and password.
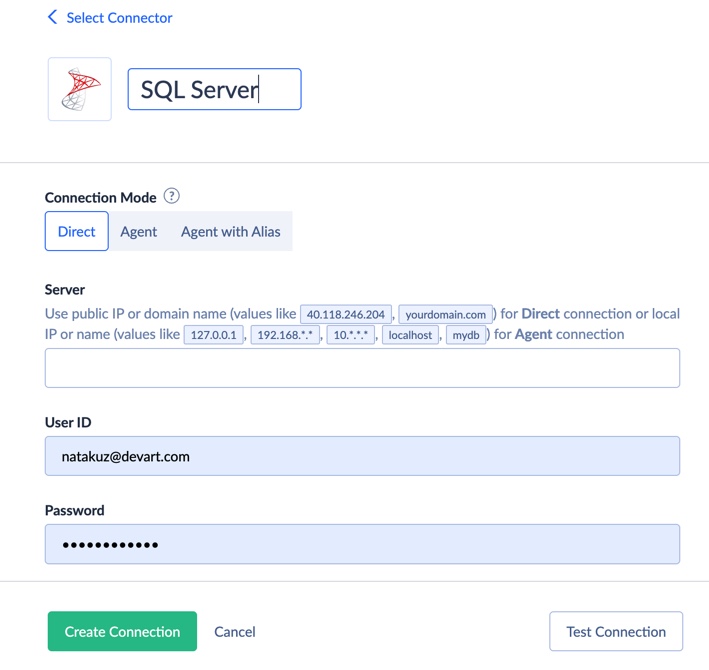
Note: Choose Direct if your SQL Server is publicly accessible. If it’s on a local network, use Skyvia Agent for a secure tunnel between your local DB and Skyvia.
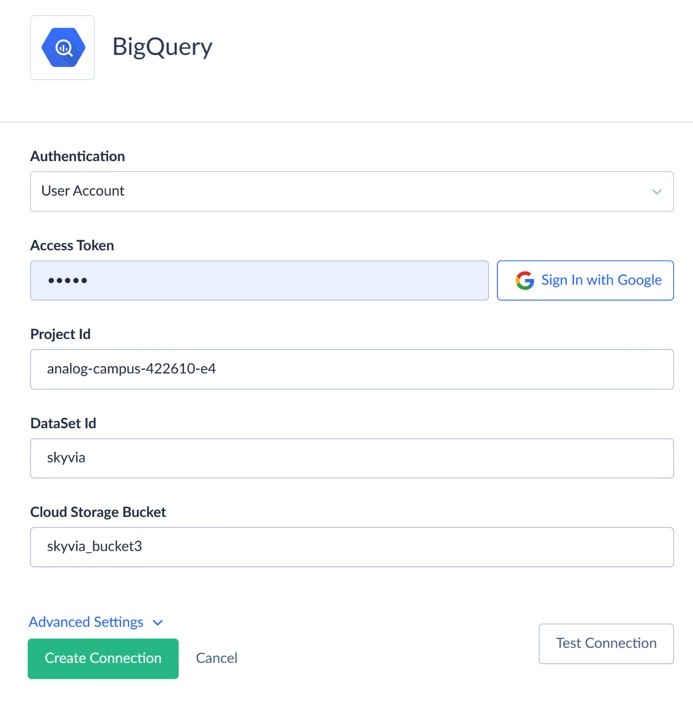
- Create a BigQuery connection
- Choose your authentication method. Skyvia supports two ones for Google BigQuery: User Account or Service Account.
- User Account: Sign in with your Google account (Skyvia uses secure OAuth token-based access).
- Service Account: Upload your private key JSON from Google Cloud Console.
- Enter your Project ID and Dataset ID. You can find this information in the Google API console.
- Optionally, specify a Cloud Storage bucket if you’ll use bulk import or replication.
- Build the import integration
- Click +Create New and select Import.
- Set SQL Server as your source and BigQuery as your target.
- Click Add new to create an import task.
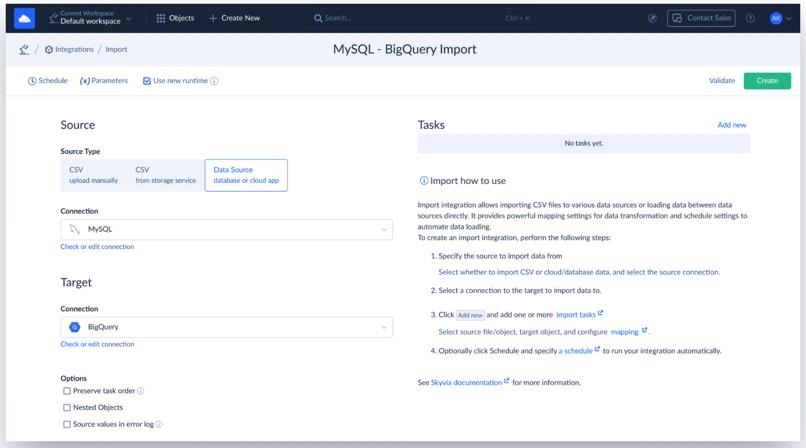
On the Source screen:
- Choose the SQL Server table you want to import.
Note: Each table is linked to a different task. You can add more tasks later.
On the Target screen:
- Choose the BigQuery table to load into.
- Select the import operation (Insert, Update, etc.).
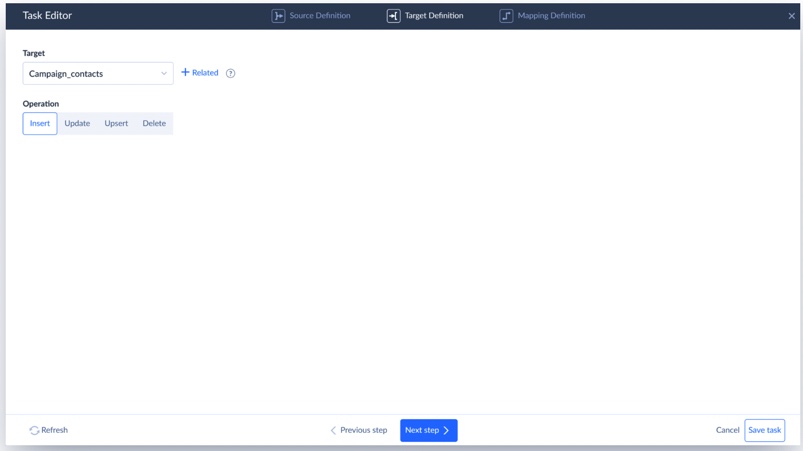
- Map your data
Skyvia shows a visual field-mapping interface:
- SQL Server columns on the left, BigQuery columns on the right.
- Click a target column, match it to the source field.
- Need to convert data types? Use Expression Mapping to reformat dates, change number types, or apply custom logic.
- When you have finished, click Save Task.
- Run and monitor
- Click Run to start your import manually.
- Or click Schedule to set up recurring syncs (daily, hourly, etc.).
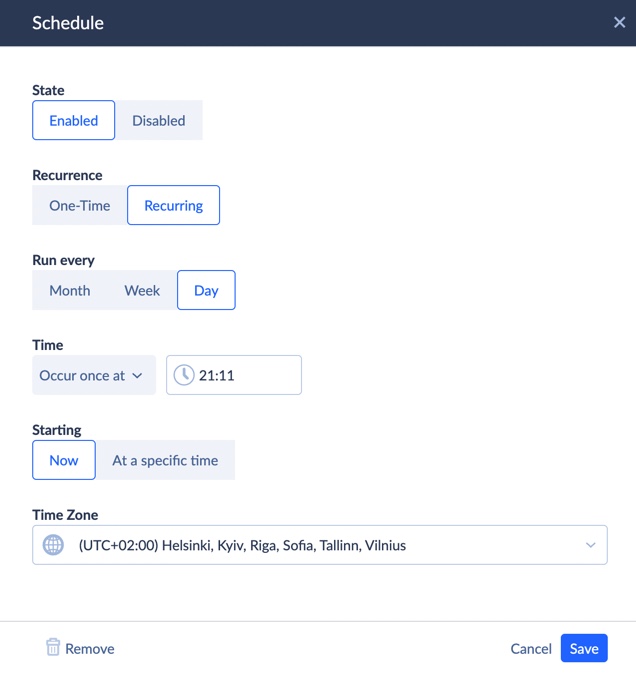
Once it’s finished, your SQL Server data is live in BigQuery and ready to power dashboards, analytics, or reporting tools.
Pros
- No-code or low-code setup. Most tools in this category offer visual interfaces that let you connect SQL Server to BigQuery with minimal technical effort, which is perfect for teams without deep engineering resources.
- Fast implementation. You can go from zero to scheduled syncs in a matter of hours, not weeks.
- Prebuilt connectors. SQL Server and BigQuery are standard integrations supported by nearly every major platform, with built-in best practices.
- Built-in scheduling and monitoring. Set sync intervals, monitor job status, and get failure alerts, all through a web interface.
- Scalable infrastructure (for most). Cloud-native ETL tools can handle moderate to high data volumes without much manual tuning.
Cons
- Vendor lock-in. You’re tied to the platform’s capabilities and pricing model. If it doesn’t support a custom use case, you’re stuck or pay more.
- Limited transformation logic. While some tools support light data shaping, complex business rules often require an extra layer (like dbt or SQL in BigQuery).
- Volume-based pricing. Many tools charge per row, per sync, or per user. It scales up fast if you’re syncing large SQL Server tables frequently.
- Less control and transparency. You don’t always see what’s happening under the hood. Troubleshooting complex issues can be harder than with a custom script.
Key Considerations When Choosing a Method
We’ve walked through five solid ways to move data from SQL Server to BigQuery. But before you lock in your strategy, here are a few real-world things to keep in mind. Think of this as your cheat sheet to find the method that actually fits your team, your goals, and your sanity level.
Data Volume
Are you moving a few hundred records or millions of rows every day? Manual methods might work for smaller datasets, but high volumes need automation, optimized syncs, and tools that won’t choke under load.
Frequency of Integration
Is this a one-time migration, a daily batch job, or do you need near real-time updates flowing into BigQuery?
- For one-offs: export/import or a quick Skyvia import is fine.
- For regular syncs: go with a scheduled, automated solution.
- For real-time: you’re in custom scripting or streaming territory.
Technical Expertise
Do you have developers, or do you need a tool that anyone can use?
- If you’ve got Python chops or a data engineer, custom scripts or Data Fusion give you control.
- No devs? Stick with no-code platforms like Skyvia. Clear UI, zero config files, no drama.
Budget
Balance tool pricing with development time.
- Third-party tools charge by rows, syncs, or seats.
- Custom scripts cost less upfront but take time to build and maintain.
- No-code platforms, like Skyvia, offer a nice middle ground for smaller teams.
Data Transformation Needs
Are you just moving raw tables or reshaping the data along the way?
- If it’s basic column mapping, most tools can handle it.
- For serious cleaning, joins, or calculations, consider something with expression mapping or plan to handle it post-load in BigQuery or with dbt.
Scalability
Will this method still work when you double your data volume or triple your syncs?
- Some tools (like Fivetran or Airbyte) are built to scale.
- Manual or semi-automated setups might not age well, especially if you’re growing fast.
Security and Compliance
How is your data handled in transit and at rest?
- Look for support for OAuth, SSL/TLS, tokenized access, and data encryption.
- If you’re in a regulated industry, compliance (HIPAA, GDPR, SOC 2) should be a dealbreaker, not a footnote.
Common Challenges and How to Overcome Them
Schema Mismatches
The problem: SQL Server and BigQuery don’t always speak the same data-type language. A DATETIME in SQL Server might not line up perfectly with BigQuery’s TIMESTAMP, or a DECIMAL(10,2) might throw a fit when landing in a FLOAT.
How to deal:
- Use mapping tools wisely. Most platforms (like Skyvia) let you tweak column types or use expression mapping to convert values mid-flight.
- Do a dry run. Test your integration with a few rows before syncing a giant table.
- Standardize early. If you know your target format, normalize column types in SQL Server before exporting.
Data Integrity
The problem: You moved 100,000 rows, but only 99,842 showed up. Somewhere along the way, records got skipped, transformed wrong, or dropped.
How to deal:
- Enable logging. Always. Most tools will show exactly how many rows synced and flag any failed ones.
- Use primary keys or hashes. These help ensure you’re not duplicating or missing rows when syncing incrementally.
- Run row counts. Compare record totals between source and target. Quick and effective sanity check.
Performance Bottlenecks
The problem: The sync is slower than Monday mornings. Large datasets, slow connections, or inefficient queries can cause major lags.
How to deal:
- Sync incrementally. Don’t move everything every time, just the new or changed data.
- Optimize source queries. Use indexes in SQL Server, reduce result size, and avoid pulling entire tables when a filtered view will do.
- Break it into chunks. Split large tables by date or ID range and move them in batches.
Security Concerns
The problem: You’re moving sensitive data (names, emails, customer info), and you don’t want it floating around in the open.
How to deal:
- Use encrypted connections. Always check that your tool uses SSL/TLS between SQL Server and the cloud.
- OAuth or token-based access. Avoid hardcoding passwords; go for secure auth wherever possible.
- Limit exposure. Only connect the tables and columns you actually need. No reason to sync your entire DB.
Ongoing Maintenance
The problem: Everything works perfectly until it doesn’t. Schema changes, expired tokens, or platform updates can quietly break your flow.
How to deal:
- Set alerts. Use tool notifications or email alerts to catch failed syncs immediately.
- Review logs weekly. Just peek in. Ensure jobs are running clean.
- Document your setup. Future you (or your coworker) will thank you when it’s time to troubleshoot.
- Plan for schema drift. If column names or types change in SQL Server, update your integration task mappings right away.
Pro tip: Set a calendar reminder once a month: “Check data pipeline health.”It’ll save you a panic attack later.
Conclusion
Getting your data from SQL Server into BigQuery is a smart move for teams who want to:
- Unlock insights.
- Run powerful analytics.
- Stop drowning in spreadsheets.
When your data’s stuck in silos, it can’t do much. But once it’s in BigQuery? Game on.
We’ve walked through five solid methods, from manual exports and Python scripts to fully automated tools like Skyvia. And here’s the truth:
There’s no universal solution for everyone. The best method depends on:
- The data volume.
- Team’s skill set.
- Budget,
- Periods of run.
However, if you’re looking for something that just works, Skyvia might be the solution.
It strips out the complexity, handles the heavy lifting behind the scenes, and lets you focus on what actually matters: the data and what you can do with it.
F.A.Q. for SQL Server to BigQuery Integration

Can I replicate data from SQL Server to BigQuery in real-time?
Yes, but you’ll need a tool or setup that supports change data capture (CDC) and streaming, like Skyvia or Fivetran, or a custom pipeline with Pub/Sub and Dataflow.
How do I ensure data security when migrating from SQL Server to BigQuery?
Use SSL/TLS encryption, OAuth, or token-based authentication, and restrict access to only necessary data. Also, choose ETL tools with strong compliance standards.
What are the main challenges when integrating SQL Server with BigQuery?
Common issues include data type mismatches, connection/auth setup, large volume performance, schema changes, and keeping everything in sync long-term.
Do I need to transform my data before loading it from SQL Server to BigQuery?
Not always. You can load raw data and transform it later in BigQuery. But for cleaner results, some light transformations (e.g., type conversion) help upfront.
