

Database replication should have been planned since day one. Now, Sander’s company is no longer that promising startup. They’ve leveled up their game. That fateful day has arrived – the hint of stale coffee and nervous sweat filled the room.
The rapid clickety-clicks, the ringings, and shaky voices – if measured are beyond the charts. The boss’s shoes thud as he walks back and forth, and he prays for another C-level boss not to call him. And Sander’s team? Fingers crossed. “We’re done for if this query hangs again”, says Sander. That day is their biggest sales hit.
They have one server for everything. So, a Single Point of Failure traps them. And when CPUs are to the roof and RAM is maxed out, everything falls apart.
Database replication could improve performance and keep their services up for longer. That’s our talk for today – the meaning of database replication, the how-tos, and more.
Ready?
Table of Contents
- What is Database Replication?
- Database Replication vs. Related Concepts
- Why is Database Replication Important? Key Business Benefits
- Types of Database Replication: Finding the Right Fit
- Common Database Replication Techniques
- How to Set Up Database Replication (Step-by-Step)
- Monitoring and Troubleshooting Replication
- Challenges of Database Replication and How to Overcome Them
- How to Choose the Right Database Replication Tool
- Conclusion
What is Database Replication?
Database replication is the process of having several updated copies of the database on other servers to improve availability, keep performance up, balance workloads, and help with disaster recovery.
This means that it distributes data across locations, and users can access the closest one, reducing latency. Users can have the same latest data as it syncs across servers. Analytics teams can also run complex queries in a replica without a drastic impact on daily transactions.
At first, everything’s fine with just one database server. That’s how Sander’s team started. But then, many customers popped up across different regions. Data grew from hundreds of thousands to millions. So, it started to feel really slow – and the stress goes up, the support tickets pile up.
What a relief this could have been if Sander and his team had planned for replication early on.
Instead of untouched cups of stale coffee, they’ll brew a new hot pot. Instead of rapid clickety-clicks, endless phone ringings, and shaky voices, everything is what they want it to be. The boss? He’s back in his room, leans back on his chair, and plans for the next best thing for his team. And Sander? All checklists show green check marks for him, not red Xs. CPU runs normal, RAM with room for more, and I/O is manageable.
But how does this work in the real world?
How Data Replication Works
Think of replication as the backbone of a global database architecture. It’s the ongoing process of copying changes from a primary database to one or more replicas so applications in different geographies read (and sometimes write) against a local copy.
In other words, you’re wiring up a geographically distributed system where updates made in one place are propagated (near-real time or on a schedule) to databases around the world.
Modern cloud database solutions make this far less painful than it used to be. With a few clicks or a short CLI script, you can spin up a primary in the US and push replicas to Germany, South Africa, and Singapore (and back them up in another region).
Managed services handle the plumbing: secure links, encryption, change streams, health checks, so you spend time on routing and SLAs, not on crafting brittle replication jobs.

Why go this route? Two big wins:
- High availability. If one region hiccups, traffic can fail over to a healthy replica. Maintenance windows stop being a fire drill.
- Low latency. Users in Frankfurt hit a German replica; users in APAC hit Singapore. Reads (and writes, if enabled) stay snappy because data lives closer to the user.
Under the hood, replication is one of the core data synchronization methods. It detects what has changed, often via Change Data Capture (CDC) using logs or triggers, and applies only those deltas to replicas, instead of re-copying entire tables. Topologies can be simple (one primary, many read replicas) or advanced (multi-primary/active-active with conflict handling), depending on whether you need global reads only or regional writes too.
Database Replication vs. Related Concepts
You may get confused about database replication because of some similarities with other data management concepts. Thinking of backup or data replication?
Database Replication vs. Backup: Key Differences
- Database replication is about continuous sync. Changes on the primary are streamed to multiple live copies that are stored online and actively used. Apps read (and sometimes write) against local replicas, so if one region hiccups, another keeps serving traffic. Think real-time operational continuity, not just copies on a shelf.
- Database backup is a point-in-time snapshot created for recovery after data loss and stored offline (or in cold/cheap storage). You don’t query a backup; you restore from it when things go south, ransomware, accidental drops, bad deployments. It’s your insurance policy for disaster scenarios.
Where they overlap: both support Data Protection, Disaster Recovery, and Business Continuity, just in different ways. Replication keeps services up by having ready-to-go live copies; backups let you roll back the clock when corruption or deletions have already spread to replicas. Mature teams run both: replication for uptime, backups for restore.

| Aspect | Replication | Backup |
|---|---|---|
| Purpose | Keep systems online (operational continuity) | Restore after loss/corruption (insurance) |
| Freshness | Near real time (continuous sync) | Point-in-time snapshots |
| Usage | Actively queried replicas | Not queried; restored when needed |
| Storage | Online, hot | Offline/colder tiers |
| Failure modes covered | Node/region outages, latency | Ransomware, bad deletes, data corruption |
| Gotcha | Bad writes, replicate fast | Older snapshot may lose recent changes |
Is Data Replication and Database Replication the Same?
It seems so, but they’re not. Data replication is a broader term, and it’s about copying data itself, not the schema, tables, stored procedures, etc. Data may also come from different sources, like files, logs, streams, and also databases. The target can be another system, like a data warehouse or a data lake.
Database replication is managed at the database engine level, like SQL Server or PostgreSQL replication. The formats should be the same (SQL Server to SQL Server, or MySQL to MySQL). But data replication can have a different target than the source.
Since data replication involves databases too, it is safe to say that database replication sits under the data replication umbrella. But not all data replication involves databases.
Why is Database Replication Important? Key Business Benefits
Do you know why YouTube rarely goes down, and Gmail mostly stays up with trillions of emails? Google uses Spanner to store videos, texts, and images and handle all of these on a planetary scale. And yes, they are synchronously replicated and globally distributed.
And why is that so? You probably had an idea from the meaning of data replication. But let’s consider the benefits in more detail below.
High Availability and Fault Tolerance
Have you ever complained about watching cat videos in YouTube because it’s down everyday? Like me, you probably haven’t. Replication is their safety net – it’s almost always available. If the primary database goes down, a replica will take its place (that’s fault tolerance). So, you enjoy your videos with fewer or no interruptions.
Sander is convinced of this first benefit, citing Google as a use case. For them and for you, that means your app keeps running and users stay happy. And no more calls from your boss in the wee hours of the evening.
Improved Performance and Load Balancing
People from Africa probably won’t watch your YouTube video if it’s stored in Europe, and there’s no replication. It will be so slow. Remember the days when videos kept buffering? That will be the case if there’s no replication and the video is not globally distributed.
Speed is important for users, or they’ll get impatient. With replication, queries go to the nearest replica. It also takes out the pressure from the primary database. The result? It’s like the YouTube video is just around the corner – faster response, no buffering. It gives more breathing room for your app and database server.
Disaster Recovery
You don’t want your company’s services down for hours, like what happened to Sander’s company. If it ever goes down, it should be in minutes, not hours or more than that – like the 2020 Google outage.
Having replicas makes it possible. It kicks in when something fails, and it has your fresh copy of data. This is an important part of your company’s disaster recovery plan.
Enhanced Data Accessibility for Analytics
Back in the day, we relied on backups to run analytical queries. It quickly goes stale because it’s frozen in time.
Not until we have database replication. We can run the complex queries in a replica without drastic effects on the primary. The replica will carry the weight of heavy queries for reports, dashboards, and BI tools.
Lower Latency
Having one database for everything is not ideal for users scattered around the globe. Having replicas in strategic regions, users can connect to the nearest one, reducing latency. Querying closer to home means faster results. The less the latency, the better for users.
The benefits are exciting, aren’t they? It makes you want to jump to replication right now. But hold your horses. Let’s discuss how this is done first.

Types of Database Replication: Finding the Right Fit
“What if we chose the wrong setup and regret it later?”
That’s a valid question. Newbies have these heebie-jeebies when they’re doing this for the first time. But once you know what they are and their trade-offs, you can choose the one that’s right for you.
Database replication types have two categories: By architecture and by data sync methods.
By Architecture
This is where you start. You refer to each server as a node and give it a role. It’s either master (primary) or slave (replica). Below are the types based on architecture:
Master-Slave (Primary-Replica) Replication Explained
This is the classic way database replication works in production. One node is the master (the primary) and handles all writes. One or more slave nodes (replicas) are read-only and keep up by applying the primary’s changes as they happen.
How it works, step-by-step
- A client writes to the master/primary. Inserts, updates, and deletes are committed and recorded in the transaction log.
- The primary streams those committed log entries (e.g., WAL/binlog/redo) to each replica.
- Replicas receive the stream and apply operations in order, bringing their data pages into line with the primary.
- Applications route read queries to replicas, keeping the primary free for fast writes.
- Monitoring watches replication lag; if a replica drifts, it’s throttled, resynced, or (if needed), promoted during failover.

Typical use cases
- Distribute read load for APIs, dashboards, and reports.
- Lower latency reads by routing users to a nearby replica.
- Hot standby for high availability and quick failover.
- Offload backups, ETL, and heavy analytics from the write path.
- Burst handling for read-heavy events (product launches, campaigns).
Multi-Master (Master-Master) Replication
Headline first: In a multi-master, any node can accept both reads and writes. There’s no single write leader.
Each primary records local changes and ships them to its peers, which do the same in return. Compared with Primary-Replica, you’re not funneling every text through one box. Each region can write locally and keep humming if another region blinks.
How it works:
In the figure, Primary A, B, C, and n are all read-write.
- A client writes to the nearest primary (say, Primary B).
- B commits the change and publishes it to the other primaries (A, C, n).
- Peers apply the update in order; if two primaries changed the same record, a conflict policy kicks in.
- Reads can hit any primary; most teams route users to the nearest node for low latency.

Why teams pick it
- Higher fault tolerance: no single point of failure for writes; if one primary goes down, others keep taking traffic.
- Lower write latency: users in EU write to EU, APAC to APAC. No round-trip to a distant leader.
- Capacity scaling: spreads write load across nodes instead of overloading one primary.
What gets tricky
- Write conflicts: two primaries can edit the same row at once. You’ll need rules: last-write-wins, source-priority, timestamps/vector clocks, or field-level merging for sensitive objects.
- Consistency trade-offs: many setups are asynchronous and eventually consistent. If you need strict ordering, you’ll consider quorums/synchronous replication and eat the latency.
- Operational discipline: global IDs, clock drift mitigation, schema-change choreography, robust monitoring for lag/divergence.
Where it fits in database replication types
- Think of Primary-Replica as centralized writes with simple ops and strong ordering; Multi-Master distributes writes for resilience and regional speed but asks you to manage conflicts and consistency. Most global platforms start with Primary-Replica for simplicity, then graduate parts of the workload to Multi-Master where regional writes or uptime requirements demand it.
Typical use cases
- Global SaaS needing regional read/write (profiles, collaboration, content edits).
- Retail/fintech that must stay live during regional outages or network partitions.
- Multi-region APIs where shaving write latency is a must-have.
By Synchronization Method
Syncs make database replication work. Without it, no replication will take place. You can classify them as synchronous and asynchronous.
Synchronous Database Replication
In synchronous data replication, every write on the primary must also be written in the replicas before it’s confirmed. This needs high consistency at the cost of performance. So, if you prioritize accuracy over speed, this is the one.
This type is like a phone call. The receiving end should accept the call, or no call can happen. Same thing, the write won’t happen if one or more replicas fail to write it. It’s all or nothing.
This option has higher latency. You will feel the lag if one or more replicas are slow or unavailable.
Best for: global financial systems or something similar, where accuracy is more important than speed.
Watch out for: Slower performance when writes wait for replicas.
Asynchronous Database Replication
In asynchronous data replication, the write is confirmed in the primary. The replicas will catch up a bit later. If speed is more important to you than accuracy, this is for you.
This type is like sending an email. The receiver will receive the email asap. But he can read them later. Same thing, the write will happen in the primary. Users connecting to replicas may not see the updates immediately.
This type has lower latency.
Best for: replicas for reporting and apps where users want it to be like The Flash.
Watch out for: data loss when writes fail in the primary.
Hybrid (Semi-Synchronous) Data Replication
Semi-synchronous, or hybrid, data replication is the middle ground. The primary waits for at least one replica to confirm before moving on. The rest of the replicas will wait.
This type is like waiting for a friend to reply, “Got it,” before you do what you need to do.
This is a balance between speed and accuracy. It reduces the risk of data loss.
Best for: Apps needing both performance and reliability, like e-commerce platforms.
Watch out for: more complexity, yet not as strong as full synchronous.
Common Database Replication Techniques
When the tide has subsided a bit, Sander said, “Alright, I now know what replication is and the types. Any tips on how to actually replicate it?”
This is the easiest, yet the heaviest, if you don’t know what you’re dealing with. It means “copy everything”. Truncate the table first, then write from the primary to the replica. Everything. This way, everything is fresh. See below:
There are a few that you and Sander can use. Check them out next.
Full-Table Replication
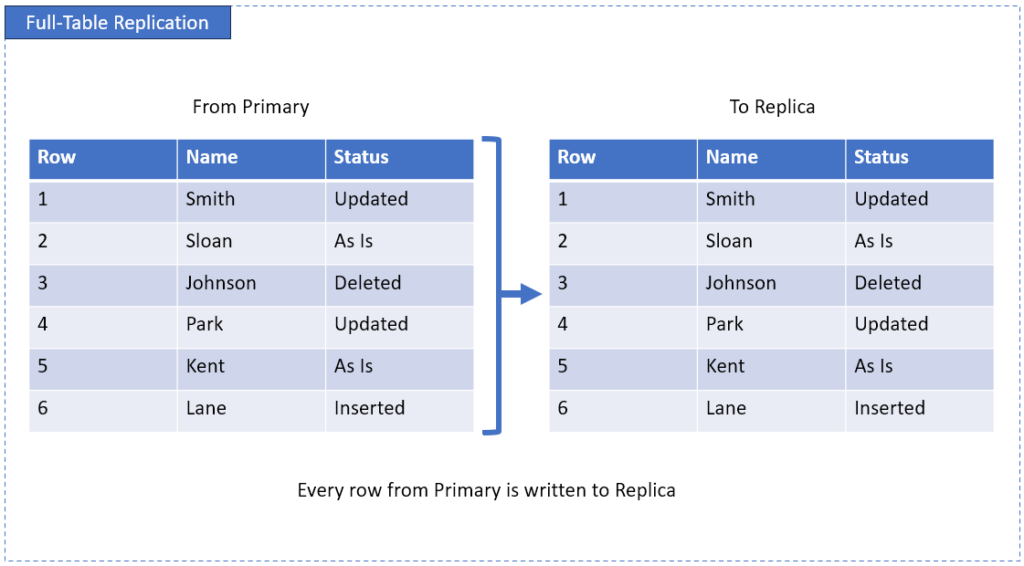
But remember that this is resource-intensive. It will be like a sumo wrestler carrying a big cabinet full of books with one hand.
Yes, your server can be huge – big RAM, lots of CPU, fast storage. But massive tables will push it to its limits. Your server will groan with the heavy load, and you’ll feel it during peak hours.
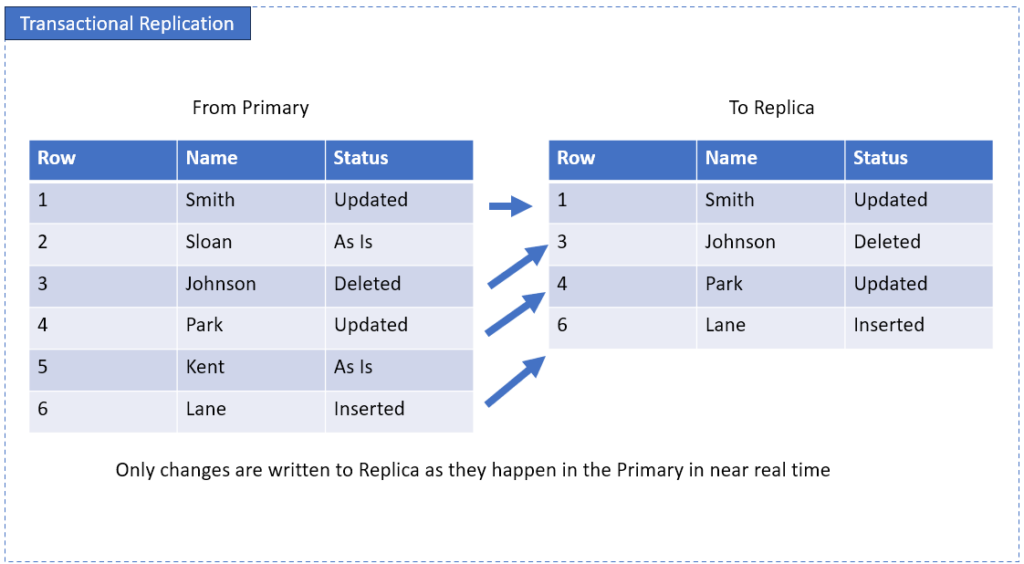
Transactional Replication
Instead of copying the whole table, this method ships each transaction almost in real-time. Insert a row? Update a column? Delete a record?
The replica sees it in a snap. It’s good for systems that can’t afford stale data — think finance, inventory, or e-commerce.
Snapshot Replication
This one is like taking a picture of your database. A snapshot is the state of all rows in the primary database at a given time, let’s say 9:00 AM.
All the rows updated, deleted, inserted, and stayed as is are copied to the replica at 9:00 AM. It stays that way until the next snapshot replication run. See a sample below:
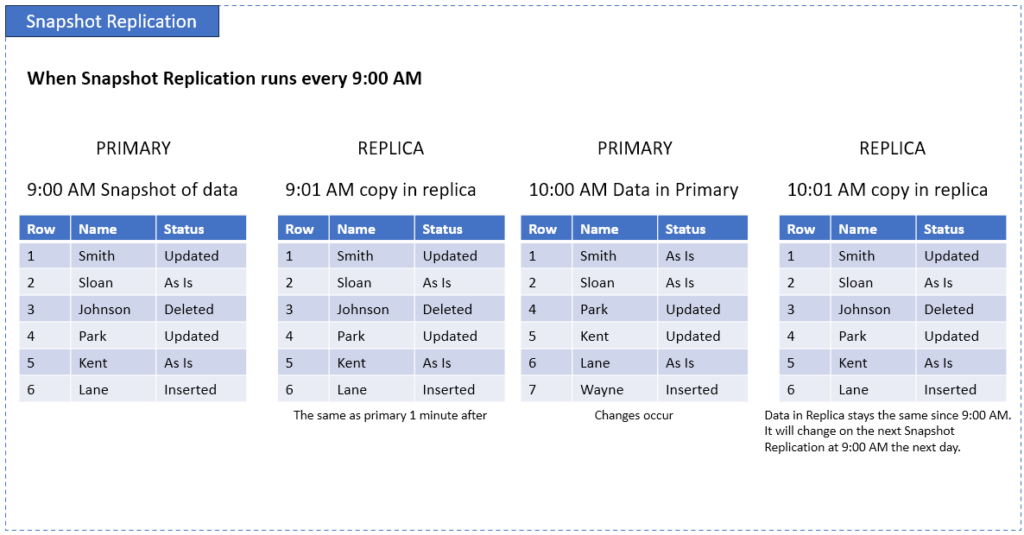
It’s simple and predictable – best for read-only replicas and data that doesn’t change often, like data for monthly, quarterly, or annual reports.
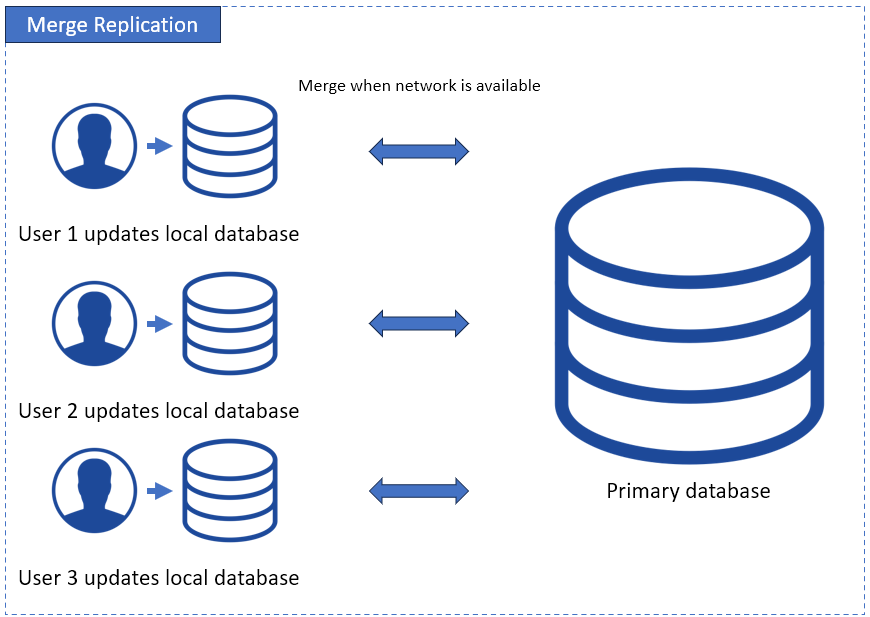
Merge Replication
This one’s like two writers editing the same Google Doc. Both the primary and replicas can accept changes, then merge them later. Handy for distributed teams or offline systems. Think of sales reps updating data on laptops.
They go to places where there’s no internet. When they get back to the office, merge replication kicks in. But merging isn’t always clean — conflicts happen, and you’ll need rules to sort out whose version wins.
See a sample illustrated below:
How to Set Up Database Replication (Step-by-Step)
To be honest, knowing the above techniques is not enough. Setting it up is another matter. That’s what this section is all about.
1. Preparation
Preparation involves your safety net, your database version, and your network capacity.
- Backup the primary database first: This is your safety net in case things go south when you do the actual replication. This is not skippable.
- Check database version and compatibility: Both your primary database and replicas should use the same database version. If not, they won’t act normally, and you’ll always be firefighting.
- Check network readiness: You don’t want a replica exposing your company’s secrets. Check firewalls, latency, and port settings specific to your database. Replication is chatty, especially when near real time. So, your network must let that chatter through.
2. Configure the Replica(s)
Configuration involves the replication user account and replication settings.
- Set replication user and permissions: Don’t use root, admin, or sa. Create a dedicated replication account on the primary with the least privileges needed.
- Adjust replication settings: This depends on your database. This may mean editing my.cnf (MySQL), postgresql.conf, or configuring SQL Server replication options. You’re setting the primary and replicas to have a “handshake”. So, make sure they do.
3. Start and Verify Replication
This involves starting the replication, verifying the logs and status, and checking for lag.
- Kick it off: Point your replica at the primary and start the replication process.
- Verify logs and status: Run the right commands (SHOW SLAVE STATUS in MySQL, pg_stat_replication in Postgres, SQL Server Replication Monitor) to confirm everything is flowing.
- Check lag: From the logs and status, look for delays between primary and replica — you want seconds, not minutes.
4. Test the Failover Process
Documentation and simulation are keys to this step.
- Simulate a failover: Don’t wait until disaster strikes. Test by switching a replica to primary in a safe environment and watch what breaks (and what doesn’t).
- Document the steps: Nothing’s worse than fumbling during real downtime. Make sure your team knows the playbook.
Monitoring and Troubleshooting Replication
Replication is not a fire-and-forget thing. It needs a watchful eye. Like looking at a car’s dashboard, see if you still have gas while driving. The same with replication. You want to know before downtime happens.
Monitoring Essentials
Sander wants to know how to monitor their database replication. So, a seasoned friend told him about 3 things:
Replication lag – Don’t make your “real-time” copy not real time anymore. Check how far behind the replica is from the primary. A small lag is fine, but a big one? That’s bad news.
Sync errors – Look for any broken transactions or skipped updates. Even one failed sync can cause data drift. Your database or a third-party tool has alerts in place for errors like these.
Network throughput – How fast does your data move between servers? Bottlenecks here can slow replication even if the databases are fine.
Tip: Set up alerts for lag spikes or sync failures. It’s easier to fix a 5-second delay than a 5-hour data gap.
Tools to Use
You don’t need fancy tools to start monitoring — most databases already have them. For example:
- MySQL: You can use the statement SHOW REPLICA STATUS in the MySQL CLI or any MySQL IDE.
- PostgreSQL: Use the pg_stat_replication view.
- SQL Server: There’s a Replication Monitor or system views like MSreplication_monitordata that you can use for SQL Server replication.
If you want insights into your monitoring, you can add third-party dashboards like Prometheus + Grafana, Datadog, or Redgate Monitor. These give you charts, alerts, and history trends instead of walls of text.
Troubleshooting Checklist
Panicky when something breaks? Well, it will break someday. But there’s a checklist for that, so don’t panic:
- Check replication lag. Why is it slow all of a sudden? If it’s growing, find out if it’s a network or workload issue.
- Review replication logs. Look for skipped transactions, permission errors, or a schema change not reflected in the replicas.
- Confirm connectivity. Make sure the replica still talks to the primary. A simple ping may be enough to tell you something’s wrong.
- Restart replication threads or services. Sometimes, a clean restart resyncs stalled replicas.
- Validate data integrity. Is there a data drift? Run checksums or data counts between primary and replica to ensure no drift.
Think of it like debugging a sync chain: verify the connection, confirm what’s out of sync, fix it, then restart the flow.
Challenges of Database Replication and How to Overcome Them
When replication breaks, you can almost hear the tension – keys clack faster, fans whir louder, even your pulse beats faster.
But these are avoidable. Let’s dissect each.
Replication Lag
This one’s the classic – the first thing you need to avoid. And yet, it may still happen. It starts for a second, then it feels like forever. The replicas are now behind. Then, you hear someone say, “I already posted it”, while the other party says, “Nah. I don’t see it!”.
It’s like paying your bills with a credit card on the due date. Unless the credit card company says go real time, you’re still unpaid (hello, penalty!).
Here’s How to Fix It:
- Adjust or tune your replication settings (e.g., adjust buffer sizes, parallel apply, batching).
- You can use asynchronous or semi-sync replication depending on your tolerance for lag vs. safety.
- Scale hardware/network if replicas can’t keep up with writes. Beef up RAM and CPU, upgrade to faster storage. Then, increase bandwidth.
Note that you can do these after the fact, meaning lag is already ongoing. You do some firefighting until the real fix is done. So, plan carefully.
Data Update Conflicts
This can happen in a master-master or multi-master. You update a row, and another guy ten cubicles away did it too for the same row. Who wins? Which update do you keep? How about you delete something the other guy is updating?
It’s a total mess.
Here’s How to Avoid It:
- Conflict detection/resolution rules: This can be last-write-wins, an app-defined logic, or custom conflict handlers.
- Application-level partitioning: You may route writes for certain rows/tables to specific masters.
- Change your policy to avoid working on the same data entity or category.
- Avoid multi-master unless truly needed — instead, use master-slave for simplicity.
Failover Downtime
Here’s how this one goes: The primary crashes. Failover kicks in. The time it took to transition to the backup system is the failover downtime. It’s not instant.
Those few seconds feel like forever – nobody can sign in, apps and reports time out. There’s silence in the room, except for sharp, deep sighs and squeaking chairs.
You can Prevent This. Here’s How:
- Automated failover tools: These are tools like Pacemaker, Orchestrator, or native DB cluster managers.
- Heartbeat monitoring to detect failure fast. This means your tool sends a small network packet or API call to see if a node is still up.
- Regular failover drills: This one’s a must to see if the team is ready when failover strikes. No more fumbling in the dark at 2 a.m.
Network Bottlenecks
If there’s a weak link, packets crawl. So, lag grows, and more red warnings. You may want to sync in smaller chunks.
The Fix:
- Optimize bandwidth: This includes optimization through compression, row-based replication, CDC, or skipping unneeded logs.
- Place replicas closer to primaries: It lowers latency and reduces lag by putting them geographically closer – not Manila to Berlin, but Manila to Singapore, for example.
- Dedicated replication channels: Instead of sharing bandwidth with app traffic, add a dedicated line.
Increased Complexity and Cost
It’s not always a happily ever after in database replication. It comes with strings attached – complexity and cost. But don’t get me wrong.
This complexity and cost give you peace of mind because you know your system can take a hit and still be standing and operational. It’s more costly to lose customers because of an unstable system.
Here’s how it gets complex. Whenever you add a node for a replica, you add a moving part in your system. It’s more configuration, more monitoring. Then, add another “What just happened?” moments when this new replica goes out of sync. You may need new experts depending on how big your setup is. This complexity equals costs.
Then, there’s new hardware, storage, and network overhead. Each replica needs compute power and network bandwidth. Even cloud-based replication stacks up the cost if you’re running a multi-region system for global users.
It’s not just your money. It’s also your time. Your team will need more time maintaining, troubleshooting problems, and updating configs.
But then again, it’s about keeping things working most of the time.
How to Choose the Right Database Replication Tool
Your peace of mind matters. That’s why choosing the right tool is so important to make a successful replication fly. Sander doesn’t want to waste time using tools that are difficult to use and won’t scale.
Using different tools for different databases means more learning and less work. So he wants something that is also simple, but will support his team and let the company grow with it.
Let’s begin by comparing native tools to third-party tools.
Built-in vs Third-Party Replication Tools
Databases like SQL Server have their own replication tools. I have used one back in the day to support a growing company and its database. But it only works for (guess what) SQL Servers. I have to learn a new tool when using a different database like PostgreSQL.
Third-party tools, however, can be simpler and allow for many databases, even SaaS apps.
Check out the comparison below:
| Feature | Built-in (e.g., MySQL native replication) | Third-Party (e.g., Skyvia) |
|---|---|---|
| Ease of Setup | Some often complex, some with manual steps, others with a wizard | Simplified, guided setup |
| Supported Databases | Usually useful for the vendor’s database only | Cross-platform – use it anywhere |
| Monitoring | Limited or CLI-based | Dashboards & alerts |
| Scaling & Automation | May or may not require custom scripts | Built-in scaling support, and with drag-and-drop graphical interface |
| Cost | “Free” but some are labor-intensive | Subscription but saves DBA time |
Key Features to Look For
These are the essentials when you’re looking for the best database replication tools for cross-platform databases. So, keep these essentials in mind:
- Multi-database support. You can use it with any database platform. You can replicate across vendors (e.g., MySQL → SQL Server or PostgreSQL) without writing custom scripts. Products like Skyvia support a variety of databases. See below:

- Real-time or near real-time replication. Tired of waiting on nightly jobs to finish? Near real-time replication keeps analytics dashboards and reporting systems up-to-date.
- Monitoring and alerts. You don’t wait until Monday morning to find out replication broke over the weekend. Receive it via email or Slack.
- Automation & scalability. Reduce manual work and errors by letting the tool handle scaling automatically.
- Ease of use. A step-by-step wizard or web UI saves you and Sander from memorizing commands. Below is a sample of Skyvia’s Replication UI:
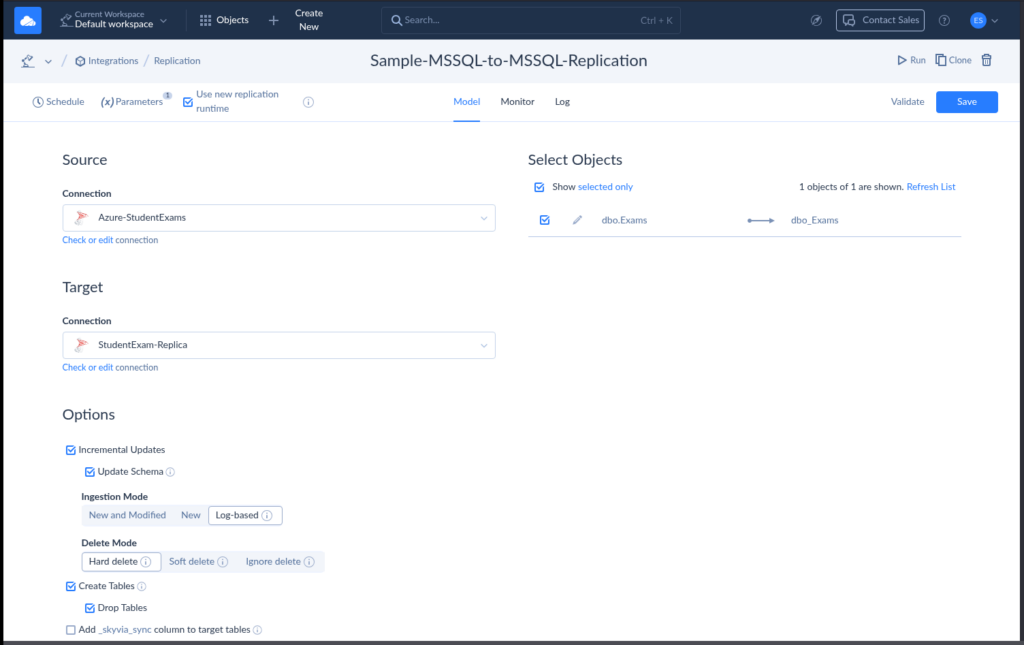
When to Switch to a Third-Party Tool
How do you know it’s time to move beyond built-in tools? Here are some signs:
- Your team spends more time fixing replication lag than delivering new features.
- Business growth is outpacing or always ahead of the current replication strategy.
- You need to replicate across different database vendors.
- Management wants updated reports and dashboards. They don’t care about log files or such.
How Skyvia Simplifies Replication
Skyvia is built to remove those headaches Sander worries about:
- No manual scripting or deep DBA expertise required.
- Supports cross-platform replication (SQL Server ↔ PostgreSQL ↔ MySQL, and more).
- Built-in monitoring dashboards and alerts.
- Cloud-based, so no extra infrastructure costs.
For teams juggling multiple systems, Skyvia makes heterogeneous database replication and real-time replication straightforward.
Conclusion
Database replication is making copies of your primary database into one or more replicas. It syncs the data between servers so you have improved availability, better performance, more balanced workloads, and better disaster recovery. You can offload analytics and reports to replicas so it won’t be mixed with day-to-day transactions.
With this, you can be confident that you are accessing the latest data that is consistent across different locations. You also learn about replication using Skyvia with a graphical web interface and a drag-and-drop feature. Give it a free try today, and see for yourself how easy it is to set up replication with Skyvia from here.

F.A.Q. for Database Replication

What are the 3 main types of database replication?
Snapshot, transactional, and merge replication.
Is database replication the same as a backup?
No. Replication keeps data synchronized, while a backup is for recovery at a point in time.
What are the main disadvantages of database replication?
Increased storage, network load, complexity, and risk of conflicts.
When should I use a third-party replication tool?
When native replication lacks features you need, like cross-database support, cloud sync, or advanced monitoring.
