

Otto’s sweating, but not because of the weather. His support ticket is a week old. The support guys? He can’t look at them straight. He still has no answers. He’s slumped in front of the dashboard. Numbers are crazy. Right when he’s in the middle of this firefight, his boss comes. “You know what? That best practices for data warehouse development … are we up to it?” he asked.
That hit him. Well, it’s not just him. The world today is eating up 181 zettabytes of new data everyday. Good SQL practices are not enough anymore. Maybe you’re on the same boat.
He’s using Skyvia. But that alone didn’t prevent the chaos. They need more.
Let me take you on his journey, and the five things he did to make a new difference.
Table of Contents
- Best Practice #1: Know the Why, Then Shape the How of Data Warehouse Development
- Best Practice #2. Choose the Right Architecture and Platform
- Best Practice #3. Design Your Data Model For Fast Queries
- Best Practice #4: Integrate Data With Quality Baked In
- Best Practice #5: Lock It Down From Day One
- Wrapping It Up
Best Practice #1: Know the Why, Then Shape the How of Data Warehouse Development
Eventually, Otto fixed the problem – temporarily, a hard-coded fix – enough to silence the users for now.
Until a meeting came…
He and his boss are now in the hot seat.
First Things First—What’s the Goal Here?
Stakeholders want a report of what happened. Then, a critical question came… “Why are we even doing this?”, the marketing guy asked. The room is suddenly quiet. Otto froze, and so did the rest. Nobody has a clear answer.
Marketing wants the dashboard faster. Finance wants the numbers clear and audit-ready. Ops just wants to take their life back. And Otto? “I worked with Phil on this dashboard.” Then, he sat down and worked in Skyvia. His boss? The higher ups told him to talked only to Phil, but now he just wants to save the project.
You see, this happens when purpose is not there. Is this for tracking leads? Or are we just cleaning the numbers? Your fancy dashboard and your shiny data warehouse are just that – shiny and fancy. Is it useful? Maybe just for “Phil”.
I had a similar experience back when I was a newbie. The project failed.
How about you? Why is your data warehouse built in the first place?
Get the Right People Talking (Before the Code Starts)
“So, you talked to Phil and not to us?” the finance guy asked.
The answer is clear. Otto wrote his first line of SQL without gathering everyone in the room. He could have called marketing, sales, finance, ops – everyone concerned. The fog will clear once they start talking (or sometimes arguing). His goal? Run the meeting, listen, take notes, and make them agree. And their bosses? That’s for his boss to handle.
Is this too much for you?
I’m an introvert, and things like these are very uncomfortable – but doable. My first big project is like this, but once everything’s in place, everyone agreed, then developing the warehouse won’t be a hit or miss. Only then is the time to open my tech tools.
Define “Winning” in Writing
Otto got his project docs written down – requirements, timeline, everything. And Phil signed it. That’s a plus for Otto, but the problem? It’s just for Phil.
Many teams mess up with this. What’s “done” for marketing? Did finance agree it’s done? What’s the definition of “done”? Make your stakeholders agree with it.
Then, get it in writing and make them sign. Paper beats memory every time.
Show Results Early, Don’t Wait for “Version 1.0”
Ah, this one’s a classic. School taught me waterfall. In real life? In my years of experience, it doesn’t deliver. So, agile became my friend.
Otto knows agile well. He takes a requirement or two, deliver it to Phil, Phil comments, Otto adjusts, iterate again, until it’s done (But then again, it’s only for Phil). This is illustrated below:
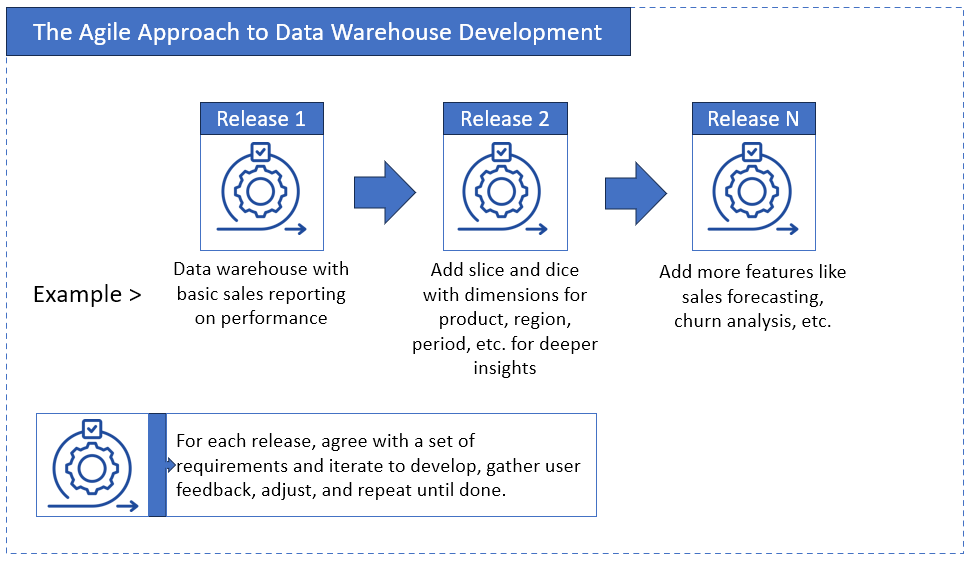
If you deliver until every bit of the requirements are done then ask for user feedback late (that’s waterfall), you’re in big trouble. Stakeholders will wait like it’s forever. And you lose their trust. Phasing it will give you quick wins. You build trust and excitement. And when things go south, it’s easier to fix.
Another plus of an agile approach is when stakeholders changed things midway.
Keep Checking Alignment as You Go
Stakeholders change their minds. I’m not kidding. What mattered to them three months ago? Might not matter now. You can’t force them to stick to what they signed. Why? Markets shift, trends change, a new crisis appears – anything can change their minds.
I’ve seen this many times, that’s why I stick to agile. It’s easier to change directions. Besides, I already have my quick wins. Users still trust the development process. We’re all happy with it, and we’re ready for the next drift.
And Otto? The project pushed through – this time, with everyone involved. The purpose and goals were set. Everything went fine. But a major drift happened. So? The next project phase dealt with it. Painful, yes – but it could have been harder, even almost impossible, if he hadn’t been doing it in phases.
But what’s the point of the sign-offs? It only shows that the team (you and them) agreed on something for project tracking. Don’t use it as a weapon against them. You will lose trust. Just get the new requirements, and let them sign it (again, for tracking).
Documentation: Annoying Today, a Lifesaver Tomorrow
Otto doesn’t like paper docs. So am I. Maybe you, too. But future you will thank you.
This is not only about sign-off docs or a bunch of emails and meeting notes. But why does this table exist in the warehouse, or what’s this column for? How do things flow from this to that? Why? Because you can not magically remember everything. And when a team member leaves (or you leave), the next person has something to learn from.
Imagine you have five sources flowing into your data warehouse. Everyone assumes you know everything (They did to me). Then, months later, someone asks why a column is missing. Are you going to dig into your source control to check the history of your scripts?
Good docs turn that nightmare into a quick fix. Even a few clear notes now save hours of frustration later.
So, the bottom line for this best practice?
Get the “why” from the right people. Then, the “how” will follow. And keep the project grounded in reality.
That’s how you build a warehouse that actually helps the business — not just stores data.

Best Practice #2. Choose the Right Architecture and Platform
Time went by for Otto. Things are looking good. But do you know where his warehouse is? On-premises. “Our servers can handle it.” he says.
Until a new product launch changed everything. Another major drift is about to happen for Otto.
Cloud is King
On-prem? It works, until it doesn’t. More servers. More cooling. And more approvals. Months of requisition. It’s too snail-paced.
And cloud data warehouses? It’s more scalable, more flexible. Less upfront headache. You still need a budget, yes, but no requisitions for racks or waiting for installation. Spin up Snowflake, BigQuery, or Redshift, and you’ve hit a major milestone.
The new product launch in Otto’s company was a hit. In short, data volume suddenly exploded. The servers Otto trusts? CPU processing – 100%. Disk I/O – to the peak. And disk space – close to full. Now what?
Otto didn’t see this coming. Another quick fix was applied. But it’s good for only a week. “Boss, we need to take this to the cloud.”, Otto told his boss. And so after many late nights and countless quick fixes, their warehouse finally moved to Snowflake.
Another product hit happened. Business is doing well. But now, it’s different. Product hits no longer mean late nights for Otto.
Picking the Platform
Snowflake. BigQuery. Redshift. Each has its good sides, so one might suit your needs. Snowflake was team Otto’s choice to adjust for growing data and processing needs.
So, consider:
Snowflake is elastic, multi-cloud, easy concurrency. BigQuery is fast, serverless, simple scaling. Redshift is AWS-native, great for Amazon-heavy stacks.
Back when I used SQL Server and SSAS? That’s enough for small projects. Today? Data grows too fast. Cloud is where you lift them.
Plan for Scalability
Think long-term. Because data doubles, then triples. You want a warehouse that grows without a painful rewrite. This hit Otto too hard, but he learned his lesson.
Did you have this same problem too?
Today, even my transactional data is in Supabase. My go-to warehouse? Snowflake. But pick what fits your business. The wrong choice now = headaches later.
Think Multi-Cloud Before You Commit
Salesforce here, QuickBooks there. Today, it’s one platform. Tomorrow? Could be another. If you didn’t plan for this, your pipelines might end up duct-taped.
So, map the systems. List the connectors. Is your warehouse tool ready for this? Last time I checked, my tool unites my scattered data (Thanks to Skyvia).
That bit of prep now? Saves you from the “oh no” scramble later.
Choose Between Top-Down or Bottom-Up Approaches
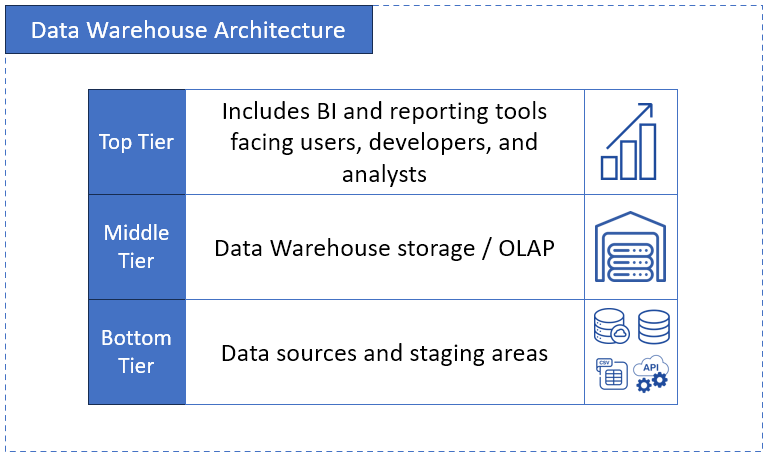
What makes a data warehouse? Let’s talk about data warehouse architecture. It includes:
- Bottom Tier – where does your raw data sit? I mean data from databases, ERP, CRM, flat files, IoT, etc. They get extracted and staged here.
- Middle Tier – this is your data warehouse storage and OLAP engine. It’s where you clean, transform, and gather your data together. You also optimize queries here.
- Top Tier – this part is what you and your users see on screen and interact with – BI dashboards, reporting tools, SQL queries, and analytics applications.
This is illustrated below:
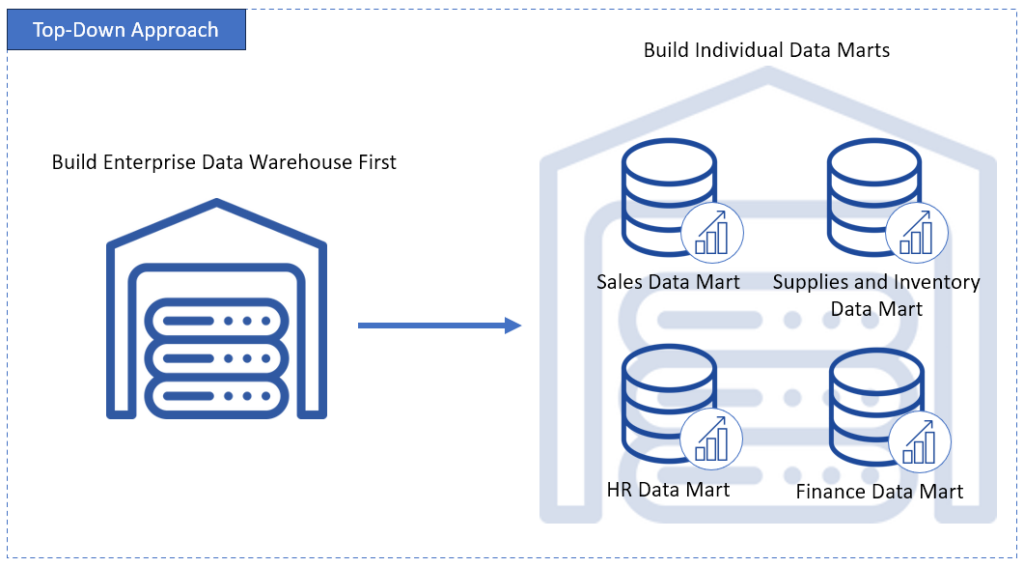
When Otto was about to build his warehouse, what approach did he choose? There are two choices:
- Top-Down (or Inmon’s approach) – this one starts by designing a central Enterprise Data Warehouse (EDW). And from this, data marts will emerge for different departments or business areas. If you’re looking for consistency and a single source of truth, this is it. But this approach is a big bang and slower to implement. And upfront cost? You have to dig your pocket deeper.
- Bottom-Up (or Kimball’s approach) – this is the opposite. It starts by delivering the data marts for each business area. Then, integrate into a broader, central warehouse. Want quick wins? Then this is the approach for you.
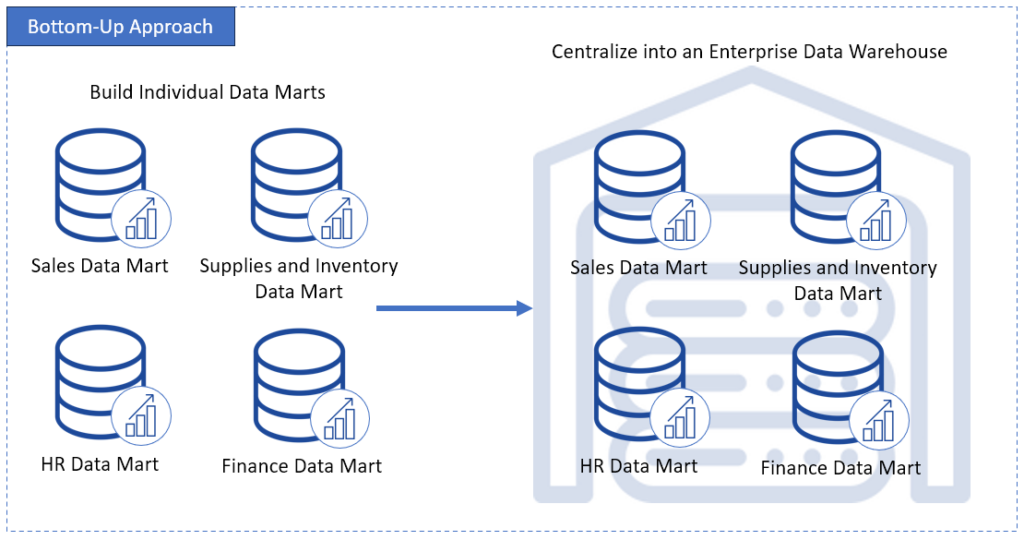
Otto chose Bottom-Up. It logically fits his project phasing approach. This has been my choice too.
How about you? Are you for consistency or quick wins?
The takeaway?
Platform and architecture choices matter a lot. Compute power, scalability, performance – all affected by your choice of platform and architecture.

Best Practice #3. Design Your Data Model For Fast Queries
This best practice is where Otto puts more hours – and for a reason. He ignores it, and queries break, dashboards crawl, and reports lag. The result? More users complain.
This is the core of your data warehouse development approaches. So, you must get it right, and everything else moves along.
Choose Between Star vs. Snowflake
It starts with the right structure. The structure you choose will tell how easy it is to query the warehouse and how fast it will run. And for the users? It tells what they can slice and dice in their reports. All of these refer to dimensional modeling.
You can choose between a star or snowflake schema.
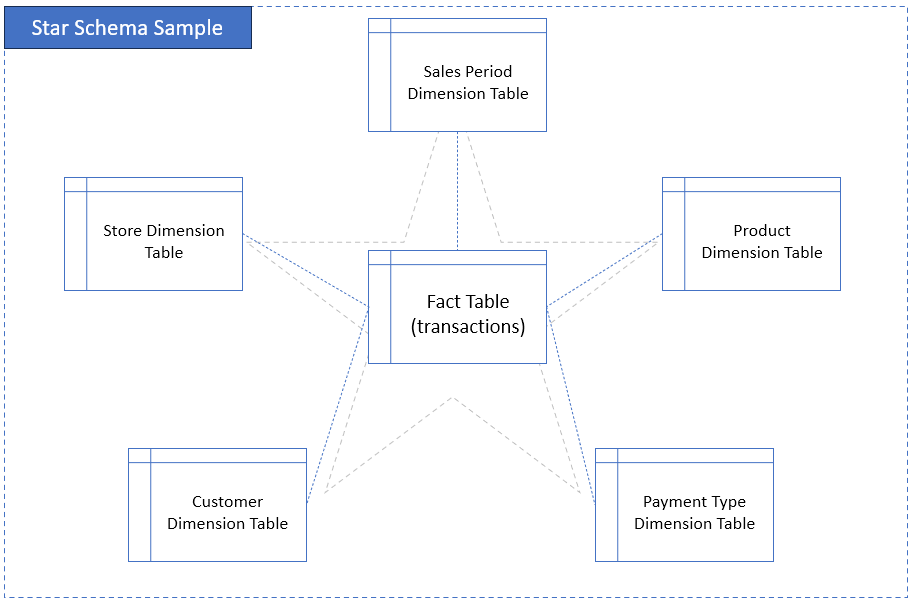
Star schema: simple. Fact table in the middle, dimensions radiating out. It’s quick to query and easy to understand. This is Otto’s choice. I start with this structure when making new data warehouses. Only when it makes sense, then I’ll change it to a snowflake schema.
Below is a Star Schema sample.
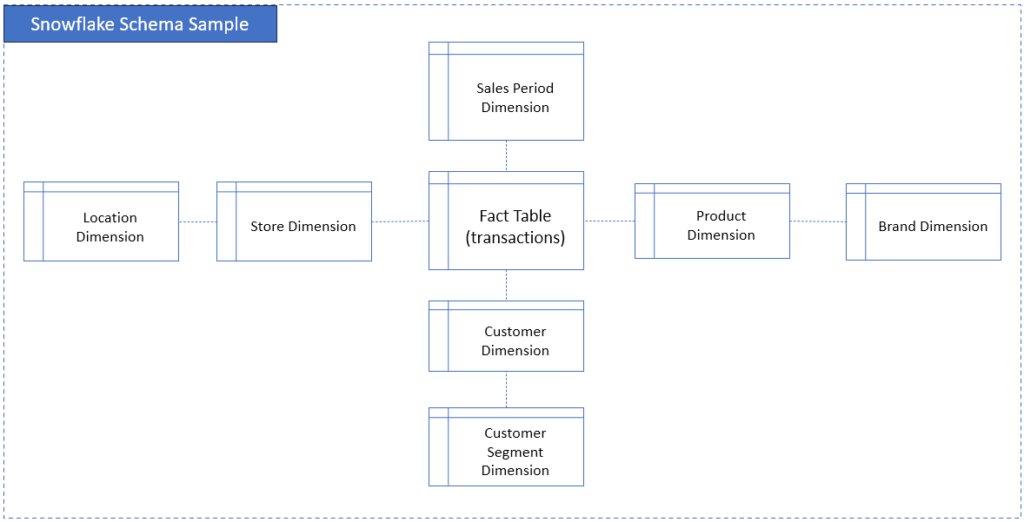
Snowflake schema: dimensions split into sub-dimensions. It’s more normalized. It saves space, sometimes improves data integrity. But don’t get confused. This is not the Snowflake product we discussed earlier.
Below is a sample Snowflake Schema with sub-dimensions:
Example: My insurance star schema had sales period, product, insurance type (fire, car, etc.), and a fact table for transactions and active policies. Clean, fast, and no mystery joins.
Add Surrogate Keys
Otto realizes that to keep the dimension tables connected to his fact table, he needs surrogate keys.
Surrogate keys make joins simple and queries fast. Use them in your fact and dimension tables. It keeps the “star” shape of your schema. Keep it simple, and avoid spaghetti models.
In that insurance warehouse I had, star schema + surrogate keys = join performance boost. Keeps me away from complaints about dashboard lag.
Index Early, Index Smart
The patience of Otto’s users is short. They want less than a second, or it’s a ticket. But table rows pile up every day. So, queries slow down. What now? Indexes fix that.
But where do you place them? On columns that people use to filter, like a sales period or a product category. Otto’s users frequently filter on product and store info. So, he adds an index in the fact table for these columns.
But wait – isn’t this the same as surrogate keys? No…That’s for data modeling. Indexing is for fast queries when filtering your datasets. But both surrogate and index keys make queries fast.
Once, a teammate was out sick. His report ticket landed on my desk. User said, “it’s crawling.” So, I checked, and there’s no index. Then, I added one, reran it. Boom! Instant speed. Complaint gone, and it never came back.
Adding indexes is easy. It won’t add to late-night jobs. And it will save hours later.
Lesson? Build for tomorrow’s data volume. Choose between a star or snowflake schema when modeling your data warehouse.
Best Practice #4: Integrate Data With Quality Baked In
Next Monday won’t be good for Otto. A null value slips through his pipeline. Dashboard numbers just gone…blank. Summing sales numbers with null results to null. So, you can imagine the execs’ faces the next day.
This is a sample of bad data creeping in. Otto’s pipeline expects a value, but it’s null. “So, what’s your fallback, Otto?”, his boss asked. A moment of silence…then Otto replied, “Sorry, boss. This one got away.”
People stop trusting the numbers – and so is the warehouse – because insights are just not there. So, please, clean the data.
ETL vs. ELT — Same Goal, Different Road
You have a classic and a modern approach to moving data.
ETL is the classic. You get (Extract), clean and prep data first (Transform), then save (Load) it into the warehouse – nice and tidy. That’s it.
I used this one for my insurance warehouse, so everything came out squeaky clean.
ELT flips it: You dump raw data first (Extract and Load), then clean it (Transform) inside the warehouse. This one’s faster. Works great if you’ve got cloud muscle and need speed. Otto chose ELT with his Snowflake data warehouse. It’s a logical choice, if you ask me.
Shown below are the main differences between the two:
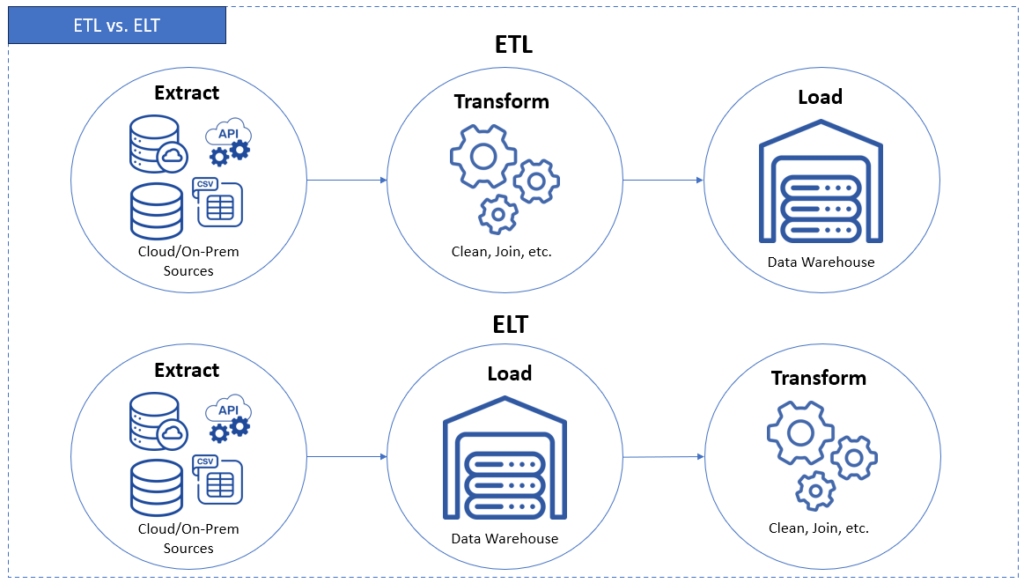
Neither is “better.” So, pick the one that makes sense for your needs.
“We’re thrilled to be recognized as Top Data Integration and Data Pipeline Tool by TrustRadius and our customers. Our mission is to make data integration accessible to businesses of all sizes and to all clients, regardless of their coding expertise. Receiving this award confirms that we are moving in the right direction by creating an easy-to-use yet feature-rich solution capable of handling complex scenarios.” Oleksandr Khirnyi, Chief Product Officer at Skyvia, stated.
Don’t Let Junk Slip Through
Newbies learn this the hard way. They haven’t realized what nulls and apostrophes can really do at first. It did to me. T-SQL code breaks at apostrophes. And like Otto, nulls nullify sales numbers. There’s also these weird timestamps from 1999. Duplicate rows are also stacked like pancakes (missing a join?).
These little landmines blow up reports. I’ve seen dashboards crater because a single field didn’t match a format.
The solution? Clean it early. If a column is nullable, SQL and your tools have functions to test and convert it. Create rules so everyone knows what “good data” looks like — that’s data governance in plain English.
If you’re the same guy who did the apps, validate the inputs. Never let the user save bad data. Because once bad data spreads? You’ll spend more time fixing messes than building anything new.
Put It on Autopilot (But Stay Awake)
You don’t want to babysit data jobs at 2 a.m. That’s why automation is a big deal.
Back in the day, I used SQL Server Agent to run nightly jobs. Now? Tools like Skyvia handle scheduling, syncing, and even quality checks. If you’re SQL savvy, you can add even more. Thanks to SQL and Skyvia, Otto had it covered eventually.
But here’s the thing — automation doesn’t mean you just sit tight and wait. That’s why I place error handling where it matters. Put alerts into every pipeline. Then, add logging, so I know the exact place these landmines blew up. But I keep it lean, or these will slow down my pipeline.
If something breaks, I know before my phone lights up with angry Slack pings.
The takeaway? Get your pipeline flow right, clean it as it moves, and keep a watchful eye.
That’s how your warehouse stays useful — and believable.
Best Practice #5: Lock It Down From Day One
Data’s valuable like cash in a vault. But here’s the thing — most teams build the warehouse first, then bolt on security later. That’s how breaches happen.
Start wrong, and you spend years patching holes instead of doing real work.
Otto was called out by the Data Privacy officer one day. Sensitive customer data was exposed because of a poorly set permission. Luckily, it didn’t leak publicly — but it could have.
Let’s lay down what he should have done.
Keep the Bad Guys Out
Hackers love data warehouses. Why? It’s a one-stop shop – credit card numbers, personal info, trade secrets, whatever. All in one place.
You need layers of defense, not just a strong password.
- Encrypt data — both when it’s moving and when it’s just sitting there.
- Lock down who gets access. Not everyone needs the keys to every room.
- Rotate those keys often.
Think of it like airport security. The gate agent doesn’t need access to the cockpit.
That close call from the Data Privacy officer? It shook Otto. So, he rolls out strict role-based access, encryption, and audit logs. From then on, when new people join, onboarding includes security checks by default.
Decide Who Owns What
Here’s where data governance comes in. Without it, things get messy. Fast.
Who approves schema changes? Who fixes a bad data feed? And who decides when a column gets renamed?
If you don’t assign roles early, you’ll end up with three teams fighting over the same problem. Write down clear policies and clear owners.
That way, when something goes wrong, you know exactly who to call — and who’s responsible.
Follow the Rules
Governments don’t play around when it comes to data. GDPR. HIPAA. CCPA. Each has its own rules on what you can store, how long you can keep it, and who can see it.
Stay compliant or pay for it later — literally. This is not a joke -massive fines, legal headaches, angry customers.
Bake compliance into your data warehouse development process from the start. It’s way easier to follow the rules now than scramble during an audit later.
The bottom line?
Security isn’t extra credit. It’s part of the build. Lock things down early, define who’s in charge, and stay on the right side of the law.
Your future self — and your users — will thank you.
Wrapping It Up
Building a solid data warehouse isn’t just about tech. It’s about knowing why you’re building it and choosing the right setup. Design a model that runs fast, keep data clean, and lock it down real tight.
Five best practices for data warehouse development, one goal: trustworthy data that drives decisions.
You know what? Skyvia can help get you there.
From automating integrations to handling flow and checks, it’s like having an extra set of hands on your team — minus the payroll headache.
Start your free trial or request a demo today and see how smooth data management can be.Data is only getting bigger — and smarter. AI and machine learning will push warehouses harder than ever.
Set yours up right now, so you’ll be ready for whatever’s next.

F.A.Q. for 5 Best Practices for Modern Data Warehouse Development

What is the difference between ETL and ELT, and which is better?
ETL transforms data before loading. ELT loads first, then transforms. Best choice depends on the tools and needs.
How does data modeling, like using a star schema, impact performance?
A clear model speeds up queries and reporting while reducing complexity.
How can I ensure high data quality in my data warehouse?
Use validation rules, cleansing processes, and regular monitoring to keep bad data out.
What role does data governance play in data warehouse development?
It sets rules and ownership to keep data accurate, secure, and compliant.
