

Businesses need data engineering solutions to cope with enormous data flows. Thus, the organizational ecosystem could function like a unified mechanism. Moreover, companies also obtain better control over all the digital data within an organization and extract proper value from it.
Let’s have a look at the real-life example. A properly designed sales funnel connected with analytical tools tells essential details about customers and their preferences. That’s a great business value, leading to excellent brand loyalty and retention rates.
There are multiple similar examples, but one thing is common for all of them – it’s necessary to select proper data engineering solutions to construct elaborate data systems. So, we have prepared an overview of popular data engineering tools in 2025:
Table of Contents
Best Data Engineering Tools
Data engineers are responsible for designing architectures and coordinating data flows. For that, data engineers have to write complex scripts that manage data during different stages of its life cycle, from collection to serving. To make the process streamlined and optimized, data engineering tools are there.
The principal stages of data engineering are the following:
- Collection
- Storage
- Transformation
- Aggregation
- Optimization
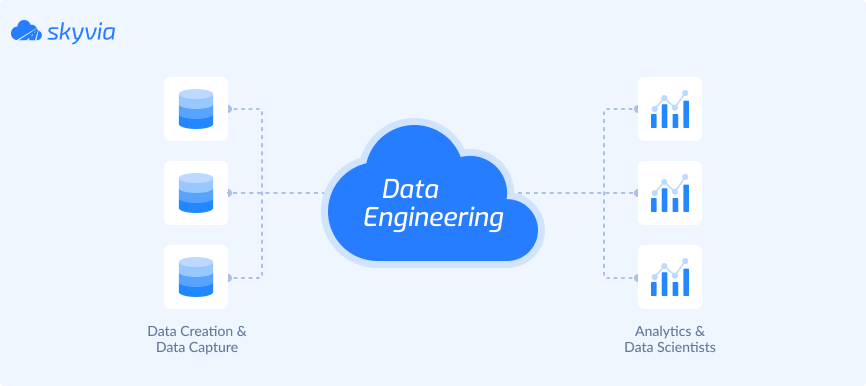
According to the above-mentioned list, the categories of the data engineering tools are more or less the same. Still, some services carry out more functions than others.
Skyvia
One of the multifunctional data engineering tools is Skyvia – a cloud-based platform for simple and complex data integration scenarios. It can perform data extraction, transformation, and load into the preferred destination (app, database, or data warehouse).
Skyvia has recently been nominated as the most user-friendly and easiest-to-use ETL software by G2. Its no-code approach contributes to designing data pipelines with an easy touch, saving lots of time for data engineers. What’s more, Skyvia connects to other popular tools on different edges of data engineering pipelines. As a result, Skyvia could become the center of the data engineering pipeline.
Key Features
- No-code data import (ETL and Reverse ETL) between cloud apps, data loading from a database to the cloud, or vice versa.
- Export data from applications to CSV files.
- Replicating data (ELT) into a data warehouse and keeping it updated automatically.
- Bi-directional synchronization of data between apps, databases, and data warehouses.
- Complex data integration scenarios involving several sources.
- Meets the data integration requirements of startups as well as enterprises.
Pros
- Visual data management with drag-and-drop functionality.
- Scheduling data transfer for automated data updates with a 1-minute interval, which is practically a real-time data integration.
- Pre-made connectors to 180+ sources.
- Has a free plan – start using Skyvia to see how it suits your business.
Cons
- Notifications about the progress or completion of data transfer are missing (though there are emails with error descriptions).
- No information about a new release.
Pricing
- Free plan
- Basic plan at $15/month
- Standard plan at $79/month
- Professional plan at $399/month
- Enterprise plan matching particular regulatory requirements at a custom price.
To select a plan that suits you best, contact Skyvia Sales Team to schedule a demo and get further details.

Amazon Redshift
Amazon Redshift is a popular data warehousing solution for companies dealing with big data. It takes data management to the next level and speeds up the process of getting insights out from data. The latter owes to Amazon Redshift’s ability to integrate with data science and analytics solutions.
Key Features
- Redshift has a columnar storage architecture, which aims to compress data for better querying and analysis.
- Implements MPP paradigm to speed up operations with data.
- Offers data protection and recovery through backup.
Pros
- Quick querying
- Easy to setup
- Seamlessly integrates with the data in S3
- Auto or on-demand scaling
Cons
- The interface could have been more intuitive
- JSON support in SQL is minimal
- Missing option to restrict duplicate records
Pricing
Amazon Redshift cost is based on the pay-as-you-go model depending on the storage and computing capacities requested.
Looker
Google’s product Looker is a breakthrough solution that clarifies complex data for everyone. It can sit on top of any modern database or data warehouse to fully leverage its power. Its role in data engineering is to extract the needed information and drive insights out of it through analysis.
To supply Looker with data from different sources for enhanced analytics, consider Skyvia for that. It also easily connects to BigQuery for data transfer, which might be extremely useful for those who use a data warehouse as a basis for analysis.
Key Features
- Accessible via the web-based interface for data exploration and analysis.
- Doesn’t require extensive knowledge of SQL, so business users can easily exploit Looker.
- Embeds into other applications and services owing to robust API.
- Creates customizable dashboards and reports.
Pros Cons
- Data filtering and navigation
- New updates with each monthly release
- Simple and easy-to-understand UI
Cons
- It can be slow sometimes
- It can be difficult to customize the visualizations
Pricing
See all the pricing details here.
Apache Spark
One of the leading data engineering tools for working with big data is Apache Spark. This service is powerful in processing large amounts of real-time data across different clusters. Spark works perfectly in the finance and banking sectors to detect fraudulent transactions immediately. It’s also popular in the entertainment, gaming, and healthcare industries.

Key Features
- In-memory cluster computing to increase the data processing speed.
- Fault tolerance due to distributed datasets.
- Algorithms for machine learning tasks.
- Integration with other Apache tools.
Pros
- Multiple language support
- Great performance for both streaming and batch data
- Outstanding processing speed
Cons
- No Dataset API support in the Python version of Spark
- Lack of documentation
- Debugging is difficult
Pricing
Apache Spark is an open-source free solution.
Segment
Segment is a Customer Data Platform (CDP) for the collection, management, and utilization of customer data from digital resources. It also assists businesses in engaging with their audiences in real time. Segment is mostly suitable for organizations in retail, media, financial services, and healthcare.

Key Features
- Design of cross-channel engagement
- Customer data pipeline optimization
- User privacy protection
- Customer profile sync with data warehouse
Pros
- Ability to disaggregate data to analyze customer engagement
- Handling PII information and GDPR
- It‘s easy to add a new endpoint/application to receive the data
Cons
- Rules for user identification and deduplication
- There is not enough consistency across connectors
- Most features are only available on the Business tier
Pricing
Segment offers three plans: Free, Team, and Business. The Team package starts from $120/month, while the Business plan’s cost is customized depending on the company’s traffic.
Fivetran
Fivetran is a low-code data integration platform that helps businesses to consolidate their data. Its main function is to extract data from various sources and load it into a data warehouse following the ELT concept.
Key Features
- Has more than 300 connectors
- Data scrubbing functions
- Scheduling data load
- Monitoring data pipelines
- Support for data lakes
Pros
- Near real-time data replication
- Granular control over data loaded
- Plenty of connectors available
Cons
- No detailed logging
- No options for masking sensitive data
Pricing
Fivetran offers a free plan for low data volumes. The price increases progressively for growing data volumes.
Apache Kafka
Apache Kafka tool is a part of the data engineering toolkit for working with big data. This platform is fault-tolerant and highly scalable. It aims to process real-time data streams. Apache Kafka is particularly useful in website activity tracking, messaging systems, logging, and so on.

Key Features
- Relies on a publish-subscribe model with producers of data and subscribers or consumers.
- Allows parallel processing and distribution of data.
- Ensure needed data transformations
Pros
- Excellent administration
- Event-driven architecture
- Asynchronous processing
- Scales horizontally very well
Cons
- It could be difficult to monitor Webhooks
- Ui doesn’t change over the years
- Learning curve to be simplified
Pricing
Apache Kafka is gratis.
Power BI
The core objective of data engineering is to design pipelines where data serves businesses. So, such a business intelligence and data visualization tool as Microsoft Power BI is the right service for that purpose. It copes with data by turning it into valuable insights for businesses.
Key Features
- Uses DAX formula language for making calculations.
- Creates interactive reports and dashboards.
- Publishes and shares data with collaborators on-demand.
- Integrates with Azure Machine Learning.
Pros
- Excellent report generation
- Open on mobile devices, desktop apps, and web
- Inexpensive licensing model
Cons
- Many sudden bugs are coming out
- Sometimes difficult to share dashboards
- No Mac version
Pricing
Power BI comes in three editions: Free, Pro for $15/month, and Premium starting from $29.90/month.
Google BigQuery
Based on Google Cloud, BigQuery offers exceptional data warehousing and analytics at scale. It would be a perfect solution for businesses that manage significant data amounts in the cloud. To set up data transfer from business apps into BigQuery, consider Skyvia for that.
Key Features
- Limitless scalability
- Serverless architecture
- Integrated AI collaborator
- Cost-effective storage
- Powerful big data analytics
- In-built ML models
Pros
- Automatically optimizes queries to fetch data quickly
- Inexpensive data storage
- Python library support
Cons
- Not able to search specific column fields using search functionality
- There is no user support
- No multi-transaction ACID compliance
Pricing
The service uses the on-demand pricing model.
Tableau
Tableau is another popular business intelligence and data visualization tool. It connects to different digital sources and creates interactive dashboards based on the ingested data. Tableau is popular across multiple industries due to its ability to explore complex datasets and flexibility in use. This makes it also convenient in use for both technical and non-technical users.
Key Features
- Drag-and-drop interface
- Supports a wide variety of chart and graph types for visualization
- Combines data from multiple sources
- Provides apps for Android and iOS
Pros
- Handles large data sets very well
- A very good set of charts
- Easy to discover and explore information
Cons
- Limited data preprocessing
- Limited product support
Pricing
There are three pricing models:
- Viewer at $15/month for observing reports
- Explorer at $42/month for observing and editing reports
- Creator at $75 for data scientists and analysts who create and analyze reports
Key takeaways
Most tools mentioned in the article originate from famous IT corporations, such as Apache, Microsoft, Amazon, and Google. Some of these solutions are unique in their genre and have no competitors on the market.
Solutions for data engineering provided here also appear on other lists of the best data engineering tools. Such selection owes a mix of criteria:
- affordable pricing
- powerful functionality
- investments
- customer pain resolution
Overall, using some of the tools provided in this article will help to design a robust data engineering itinerary. As an ETL tool is usually a core of a data engineering pipeline, we suggest starting with Skyvia on the way to outstanding achievements!

